Hello everyone,
I am currently working on calculating the Model-Flo-Utilization (MFU) using Flash AttentionV2 and have encountered a couple of issues that I hope to get some insights on:
- Discrepancy with Paper-Reported MFU: Despite referring to many docs including the use of sdpa, the calculation of flops, we are unable to achieve the same MFU values reported in the paper. Could there be specific implementation details or considerations that I might be overlooking?
- Higher MFU values for large model training: In our experiments, we have found that the MFU values for large model training are higher than the values we calculated. Are there common pitfalls or problems in MFU calculations that could lead to this discrepancy? Are there specific aspects that might explain why we observed lower than expected MFU values?
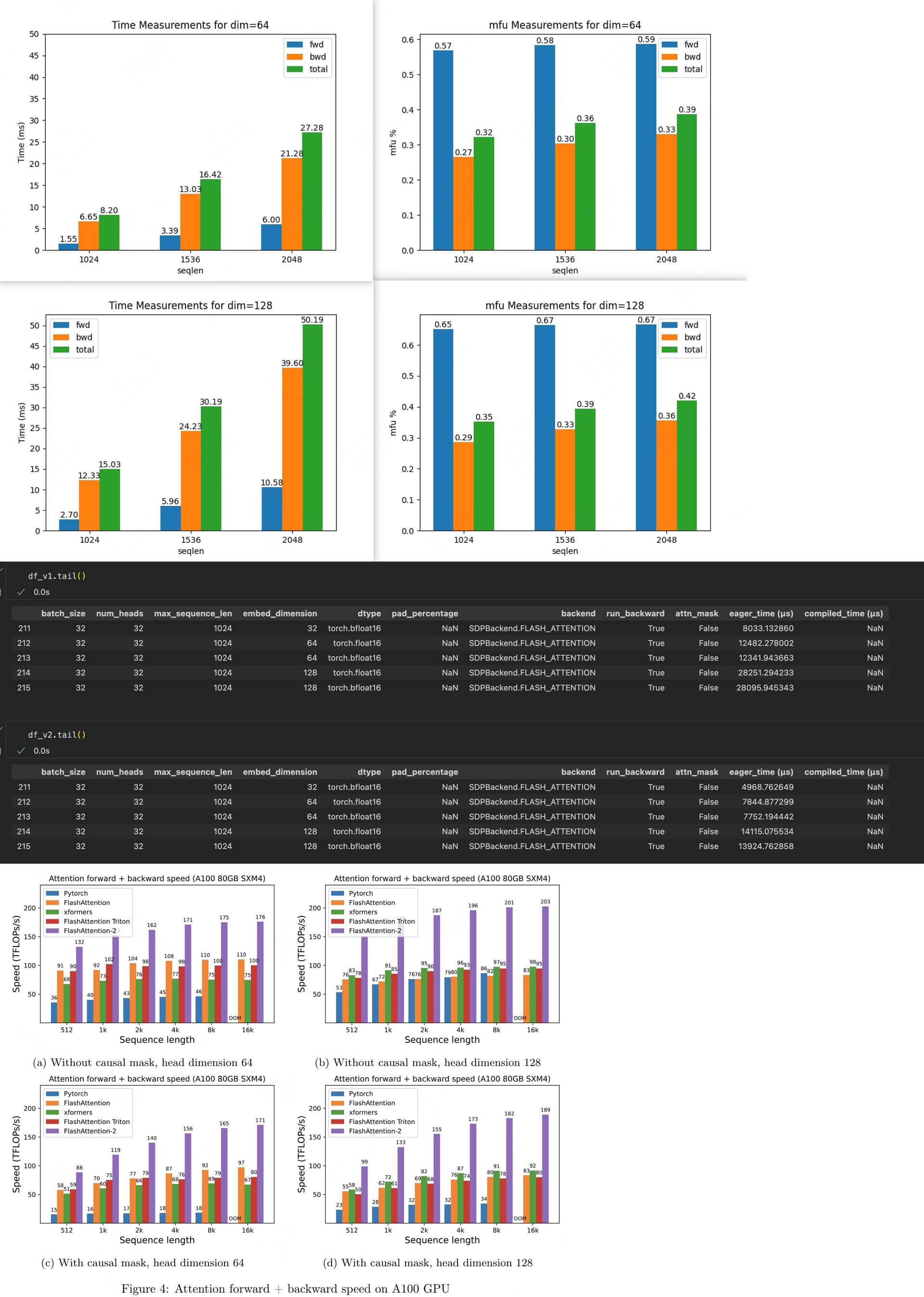
The following figure shows our test results with data type bfloat16, batchsize = 32, num head = 32, running on the A800, pytorch=2.3.1, cuda=11.8 (Image 1)
We can see that the running time of the test results at seqlen=1024 and dims=128 is close to the results in flash attention v2 pr. (Image 2)
But converting mfu to flops we are far from the results in the v2 paper, which is very confusing to me. (Image 3)
(I’m sorry because new users can only upload one image so I’ve combined all three in one)
test code:
import torch
import torch.nn.functional as F
from torch.nn.attention import SDPBackend
from torch.cuda import amp
TFLOPS = 1000000000000
A800_PEAK_FLOPS = 312 * TFLOPS
LOOP_TIME = 10
batch_size = 32
num_heads = 32
class SDPA(torch.nn.Module):
def __init__(self):
super(SDPA, self).__init__()
def forward(self, Q, K, V):
with torch.nn.attention.sdpa_kernel(SDPBackend.FLASH_ATTENTION):
output = F.scaled_dot_product_attention(Q, K, V, is_causal=False)
return output
def cal_flops_attn_fwd(seq_len, dims):
flops = 0
# scores = torch.matmul(Q, K.transpose(-2, -1))
# [s h] * [h s] = [s s] -> 2 * s * s * h
flops += 2 * seq_len * seq_len * dims
# output = torch.matmul(attention_weights, V)
# [s s] * [s h] = [s h] -> 2 * s * h * s
flops += 2 * seq_len * dims * seq_len
return flops * batch_size * num_heads
def cal_flops_attn_bwd(seq_len, dims):
return 2 * cal_flops_attn_fwd(seq_len, dims)
if __name__ == "__main__":
def measure_time(func):
total_fwd_time = 0
total_bwd_time = 0
start = torch.cuda.Event(enable_timing=True)
end = torch.cuda.Event(enable_timing=True)
with amp.autocast(enabled=True, dtype=torch.bfloat16):
for i in range(LOOP_TIME):
start.record(stream=torch.cuda.current_stream())
r = func()
end.record(stream=torch.cuda.current_stream())
end.synchronize()
fwd_time_ = start.elapsed_time(end)
start.record(stream=torch.cuda.current_stream())
a = r.sum()
a.backward()
end.record(stream=torch.cuda.current_stream())
end.synchronize()
bwd_time_ = start.elapsed_time(end)
if i == 0:
continue
total_fwd_time += fwd_time_
total_bwd_time += bwd_time_
torch.cuda.empty_cache()
return total_fwd_time + total_bwd_time, total_fwd_time, total_bwd_time
for seq_len in (1024, 1536, 2048):
for dimension in (64, 128):
dtype = torch.bfloat16
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
query = torch.rand(batch_size, num_heads, seq_len, dimension, dtype=dtype, device=device,
requires_grad=True)
key = torch.rand(batch_size, num_heads, seq_len, dimension, dtype=dtype, device=device, requires_grad=True)
value = torch.rand(batch_size, num_heads, seq_len, dimension, dtype=dtype, device=device,
requires_grad=True)
warmup_iter = 3
# warm_up
for _ in range(warmup_iter):
res = torch.matmul(query, key.transpose(-2, -1))
torch.cuda.synchronize()
torch.cuda.empty_cache()
sdpa = SDPA()
with torch.nn.attention.sdpa_kernel(SDPBackend.FLASH_ATTENTION):
total_time, fwd_time, bwd_time = measure_time(
lambda: sdpa(query, key, value)
)
total_fwd_flops = cal_flops_attn_fwd(seq_len, dimension) * (LOOP_TIME - 1)
total_bwd_flops = cal_flops_attn_bwd(seq_len, dimension) * (LOOP_TIME - 1)
total_flops = total_fwd_flops + total_bwd_flops
fwd_mfu = (total_fwd_flops / A800_PEAK_FLOPS) / fwd_time * 1000
bwd_mfu = (total_bwd_flops / A800_PEAK_FLOPS) / bwd_time * 1000
total_mfu = (total_flops / A800_PEAK_FLOPS) / total_time * 1000
print(f"sdpa sum time: fwd time: {fwd_time}, bwd time: {bwd_time}, total_time: {total_time}")
print(f"sdpa avg time: fwd time: {fwd_time / (LOOP_TIME - 1)}, "
f"bwd avg time: {bwd_time / (LOOP_TIME - 1)}, "
f"total avg time: {total_time / (LOOP_TIME - 1)}")
print(f"sdpa mfu({seq_len}, {dimension}): fwd {fwd_mfu}, bwd {bwd_mfu}, {total_mfu}")
Any guidance or advice on these issues would be greatly appreciated. Thank you!
Best regards,
Uwwal