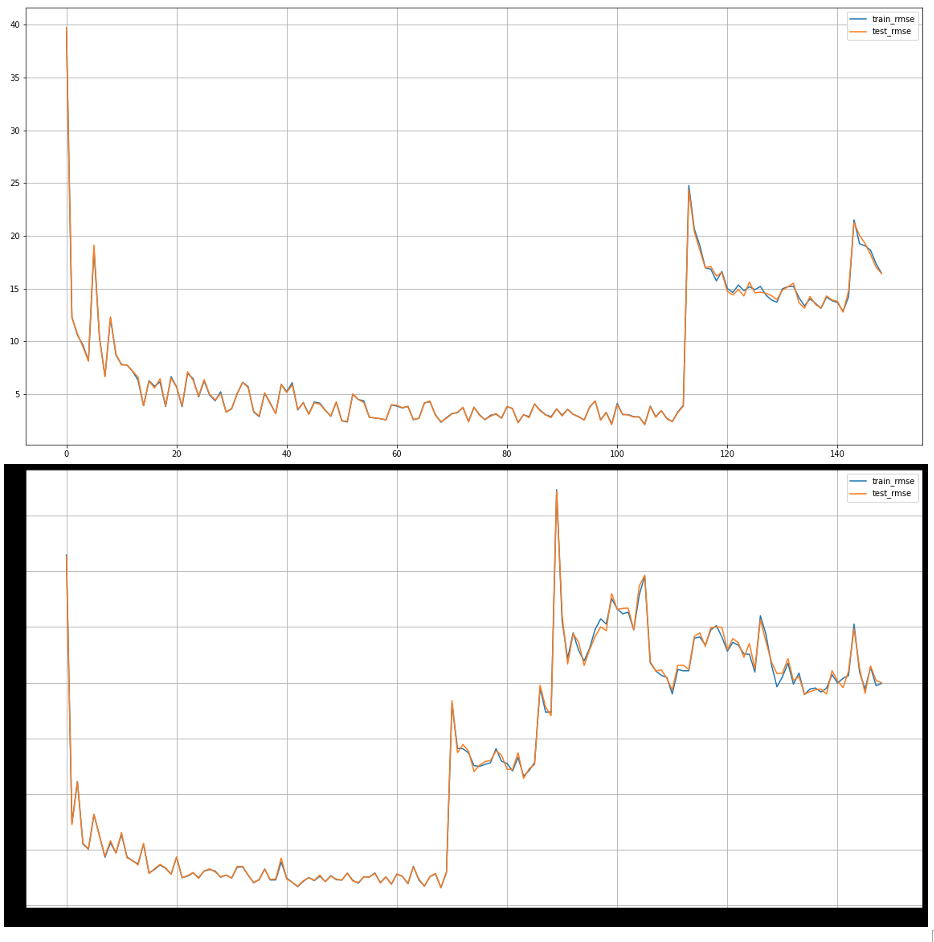
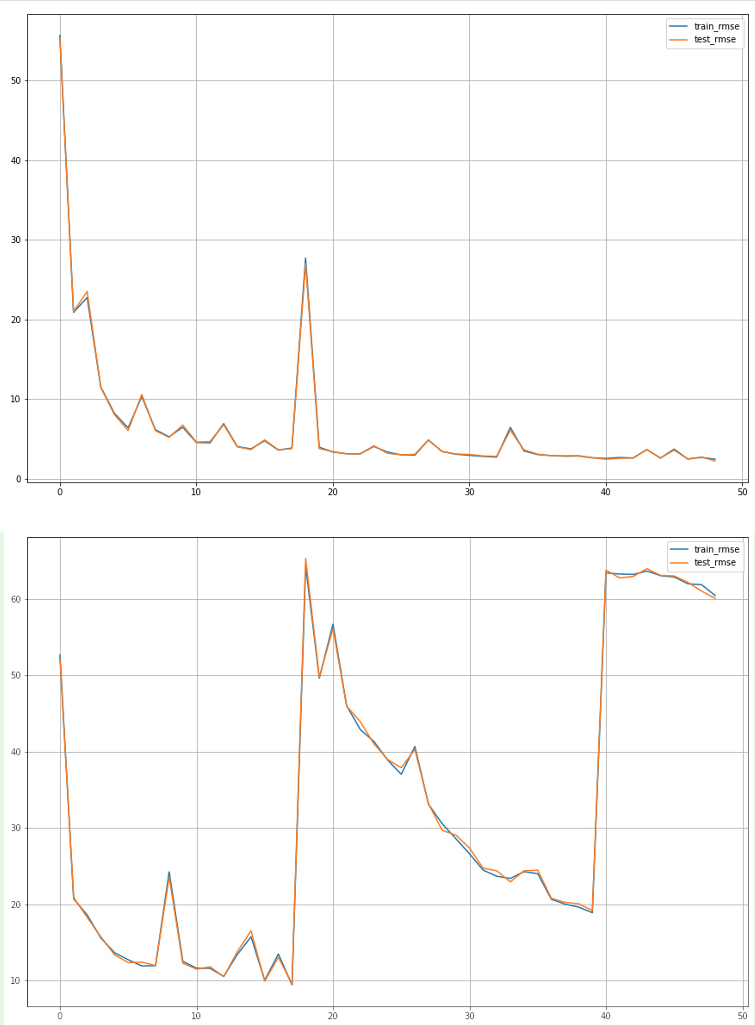
here’s my data loader code.
def load_data(x_data, y_data, step_size):
data_samples = []
labels = []
for i in range(int(x_data.shape[0]/step_size)):
data_samples.append(x_data[i*step_size: i*step_size + step_size, :])
labels.append(y_data[i*step_size + step_size-1, : ])
shuffle_ls = list(zip(data_samples, labels))
random.shuffle(shuffle_ls)
data_samples, labels = zip(*shuffle_ls)
test_set_size = int(np.round(0.15*len(data_samples)))
val_set_size = int(np.round(0.15*len(data_samples)))
train_set_size = len(data_samples) - test_set_size - val_set_size
x_train = np.asarray(data_samples[0:train_set_size])
y_train = np.asarray(labels[0:train_set_size])
x_val = np.asarray(data_samples[train_set_size:train_set_size + val_set_size])
y_val = np.asarray(labels[train_set_size:train_set_size + val_set_size])
x_test = np.asarray(data_samples[train_set_size + val_set_size: ])
y_test = np.asarray(labels[train_set_size + val_set_size: ])
return [x_train, y_train, x_val, y_val, x_test, y_test]
x_train, y_train, x_val, y_val, x_test, y_test = load_data(x_data_normalized, y_data_normalized, step_size = 150)
print("X_train shape: ", x_train.shape)
print("Y_train shape: ", y_train.shape)
print("X_val shape: ", x_val.shape)
print("Y_val shape: ", y_val.shape)
print("X_test shape: ", x_test.shape)
print("Y_test shape: ", y_test.shape)
# make training and test sets in torch
x_train = torch.from_numpy(x_train).type(torch.Tensor)
x_test = torch.from_numpy(x_test).type(torch.Tensor)
x_val = torch.from_numpy(x_val).type(torch.Tensor)
y_train = torch.from_numpy(y_train).type(torch.Tensor)
y_test = torch.from_numpy(y_test).type(torch.Tensor)
y_val = torch.from_numpy(y_val).type(torch.Tensor)
print("Tensor Size: ", "="*30)
print(y_train.size(), x_train.size())
print(y_val.size(), x_val.size())
print(y_test.size(), x_test.size())
print("Making Data Loader: ", "="*50)
batch_size = 128
train = torch.utils.data.TensorDataset(x_train, y_train)
val = torch.utils.data.TensorDataset(x_val, y_val)
test = torch.utils.data.TensorDataset(x_test, y_test)
train_loader = torch.utils.data.DataLoader(dataset=train, batch_size=batch_size, shuffle=False)
val_loader = torch.utils.data.DataLoader(dataset = val, batch_size= batch_size, shuffle=False)
test_loader = torch.utils.data.DataLoader(dataset=test, batch_size=batch_size, shuffle=False)
and the tensors shapes
X_train shape: (10500, 150, 6)
Y_train shape: (10500, 2)
X_val shape: (2250, 150, 6)
Y_val shape: (2250, 2)
X_test shape: (2250, 150, 6)
Y_test shape: (2250, 2)
Tensor Size: ==============================
torch.Size([10500, 2]) torch.Size([10500, 150, 6])
torch.Size([2250, 2]) torch.Size([2250, 150, 6])
torch.Size([2250, 2]) torch.Size([2250, 150, 6])