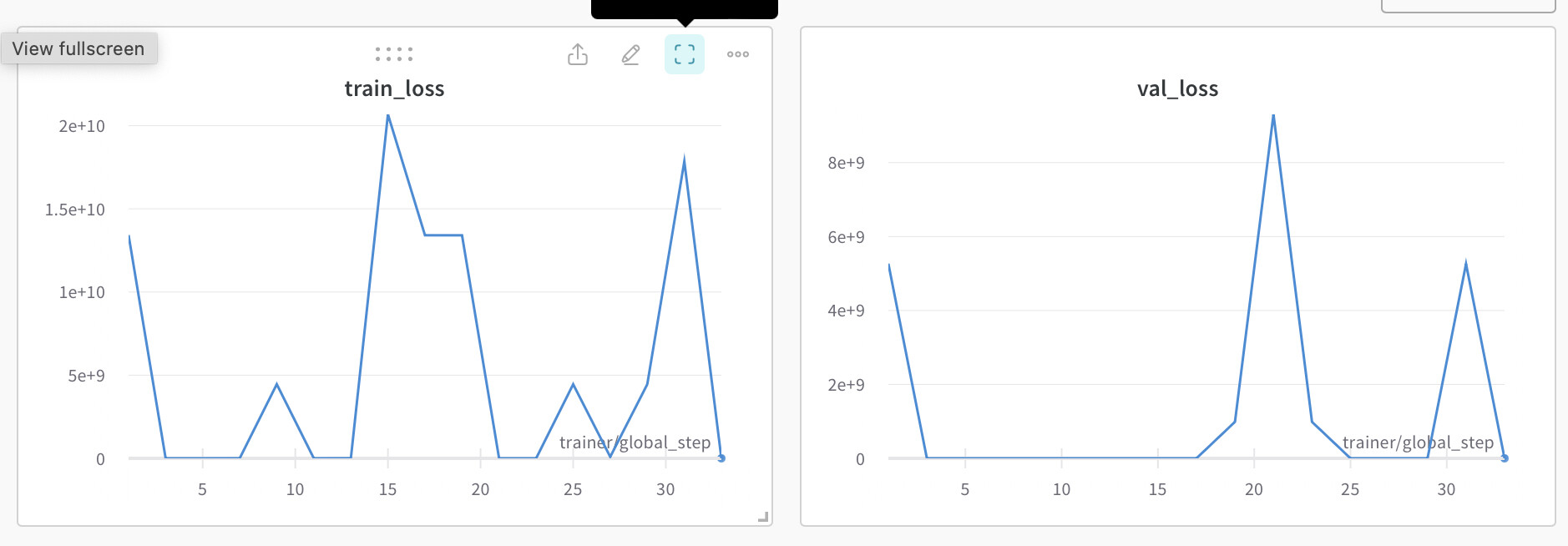
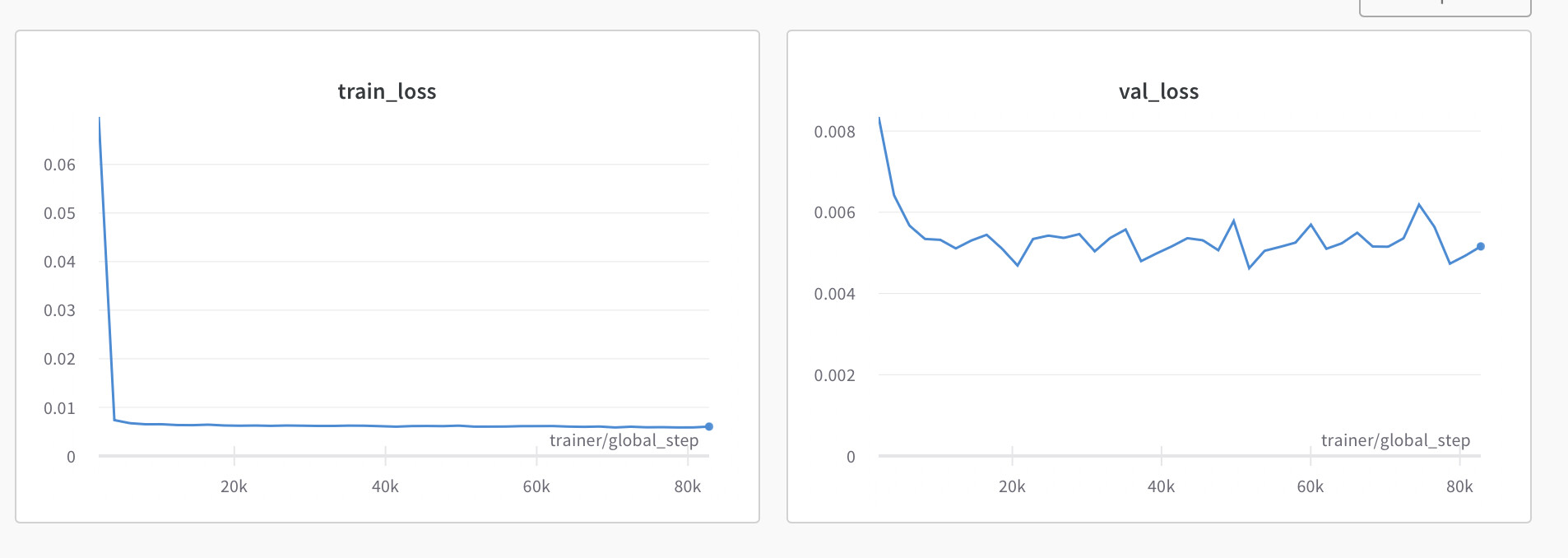
I have an MLP and trying to predict 2 values from the MLP (so i’m doing a multi task learning). these values have two losses of different scales (one is in the tens and the other is in 100,000s). so I cant simply add the losses together before back propagating. I’m currently trying to learn a weight so I can use it to balance the losses but I dont know how do go about that. Below is a brief summary of the code
class MLP(nn.Module):
def __init__(self, input_dim, output_dim):
super(MLP, self).__init__()
self.fc1 = nn.Linear(input_dim, 100)
self.out1 = nn.Linear(100, output_dim - 1)
self.out2 = nn.Linear(100, 1)
self.relu = nn.ReLU()
#create a learnable parameter that is used to weight the two losses
self.weight = nn.Parameter(torch.ones(1, requires_grad=True))
def forward(self, x):
out1 = self.out1(self.relu(self.fc1(x)))
out2 = self.out2(self.relu(self.fc1(x)))
return out1, out2, self.weight
#in train method (assume we have the target values and data)
predicted_one, predicted_two, weight = model(data)
loss_one = nn.Functional.mse_loss(predicted_one, target_one)
loss_two = nn.Functional.mse_loss(predicted_two, target_two)
total_loss = loss_one + weight * loss_two
I dont think this is how to go about it because the the weight doesn’t learn. Please Kindly assist.