Hi all,
I’m trying to balance a multilabel data set with WeightedRandomSampler.
So in the first place, all the examples are separated.
temp_dict = train_set[‘cls’].value_counts().to_dict() // Here I’m counting the classes
print(temp_dict) → {0: 10814, 1: 2407, 2: 387}
train_set[‘sample_w’] = [1/temp_dict[i] for i in train_set[‘cls’]] // making a column where each example gets the inverse of the class proportion: {0: 1/10814, 1: 1/2407, 2: 1/387}
And now is the tricky part, the dataset contains few objects for every image, so I’m using groupby the path of the image, so the the class column has attributes like: [0,0,0] or [0,1] or [0,0,2] etc… :
train_set.groupby(‘path’,as_index=False).agg({‘cls’: lambda x: list(x), ‘sample_w’:lambda x: np.mean(x)})
For the weights columns, I’m using the mean of the weights I calculated before, but I’m not sure if this is the right way to balance the data in a way that the neural net will see each class at the same amount.
This is how the dataset looks like at the end:
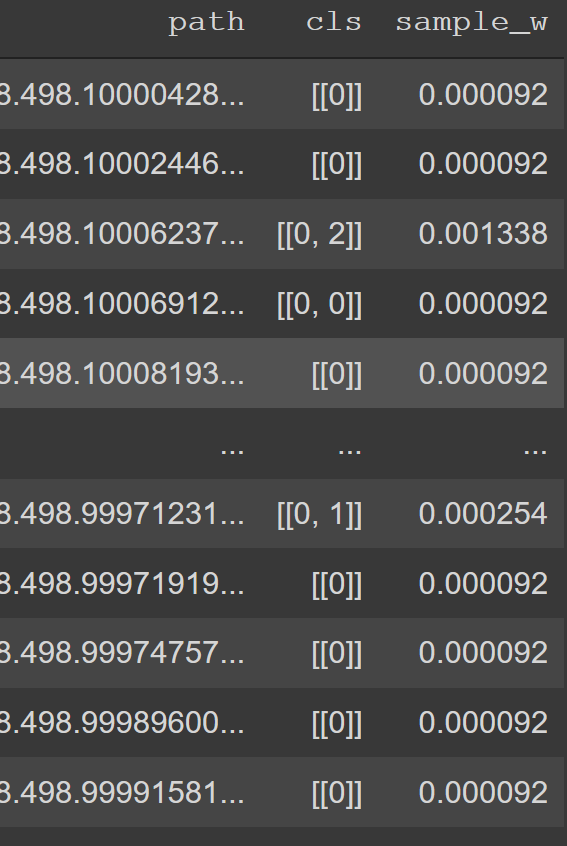
But when I use WeightedRandomSampler and dataloder and count the classes that I get, I’m still getting imbalanced classes:
0: 100, 1: 26, 2: 19
Hope I made myself clear enough, what am I doing wrong??
Thanks