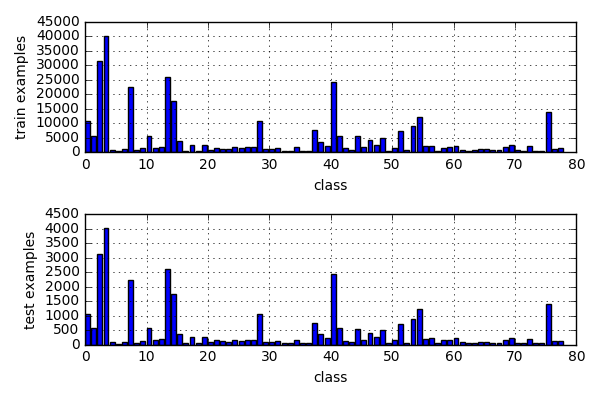
I was able to use this weighted random data sampling using @ptrblck 's code.
here is a snippet:
print('Loading data...')
train_dataset = datasets.ImageFolder(root=traindir,
transform=transform_train)
test_dataset = datasets.ImageFolder(root=valdir,
transform=transform_test)
print('Loading is Done!')
num_classes = len(train_dataset.classes)
#TODO: read class counts from the file
class_sample_counts = [10647, 5659, 31445, 40283, 800, 407, 1111, 22396, 610, 1288, 5708, 1538, 1848, 26015, 17639, 3859, 473, 2509, 579, 2636, 822, 1616, 1226, 949, 1725, 1306, 1758, 1704, 10637, 1091, 1036, 1292, 474, 569, 1682, 553, 506, 7571, 3598, 2280, 24291, 5725, 1319, 824, 5456, 1781, 4074, 2538, 5032, 503, 1623, 7251, 599, 9037, 12221, 2128, 2290, 459, 1549, 1739, 2297, 838, 469, 674, 1030, 994, 704, 672, 1690, 2442, 766, 578, 2032, 534, 552, 13934, 1138, 1372]
# compute weight for all the samples in the dataset
# samples_weights contain the probability for each example in dataset to be sampled
class_weights = 1./torch.Tensor(class_sample_counts)
train_targets = [sample[1] for sample in train_dataset.imgs]
train_samples_weight = [class_weights[class_id] for class_id in train_targets]
test_targets = [sample[1] for sample in test_dataset.imgs]
test_samples_weight = [class_weights[class_id] for class_id in test_targets]
# now lets initialize samplers
train_sampler = torch.utils.data.sampler.WeightedRandomSampler(train_samples_weight, len(train_dataset))
test_sampler = torch.utils.data.sampler.WeightedRandomSampler(test_samples_weight, len(test_dataset))
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=args.batch_size,sampler=train_sampler, **kwargs)
val_loader = torch.utils.data.DataLoader(test_dataset, batch_size=args.batch_size, sampler=test_sampler, **kwargs)