Hi everyone,
I am having issues with batch norm for a while now. What happens is essentially that the exponential moving averages of mean and variance get corrupted at some point and do not represent the batch statistics anymore for whatever reason. This results in a stark increase in validation loss and bad predictions overall. When I run the validation with network.train() instead of eval() then everything stays normal (but is of course impractical for inference). (That’s how I know the moving averages must be at fault because that’s the only difference between train() and eval() in this model).
Here is some additional detail to maybe help you understand what is going on:
I am training a ResNet 50 on an image classification problem. The particular implementation of resnet is custom but I have had the same issues with the torchvision implementation. I am using Adam with an initial learning rate of 3e-4 and reduce the lr by a factor of 5 whenever the train loss has not improved in the last 30 epochs (ReduceLROnPlateau lr scheduler). The loss is the sum of BCE and F1 loss. BatchNorm parameters are all on default.
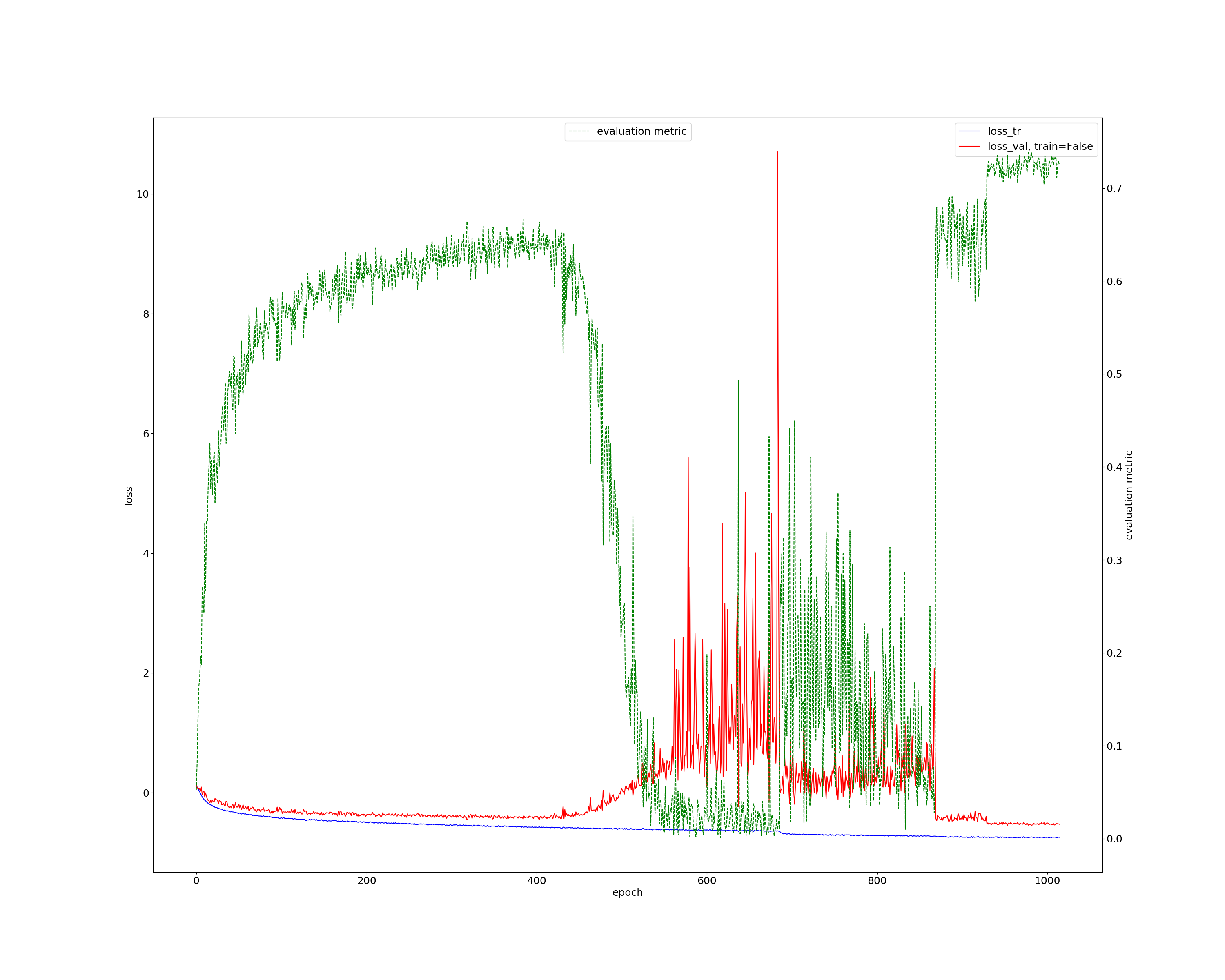
I have attached a typical training curve down below. blue = train loss, red = val loss (both use the y axis on the left). green is evaluation metric (f1 score in this case; uses right axis).
Interestingly the problem seems to solve itself as the learning rate decreases (see around epoch 850). Also interestingly, it is not easy to reproduce this problem. Sometimes it happens, other times it doesn’t.
Do you have any idea what could cause this kind of behavior?
Thank you so much!
Fabian
That’s an interesting observation.
Did you have a look at the running stats before the loss exploded and during this issue?
Are you shuffling the Dataset in each epoch?
Have you tried to freeze the BatchNorm layers after a while? Currently I cannot imagine why the running stats should get that worse, if your model has already been trained for more than 400 epochs successfully.
Hi ptrblck, thanks for getting back to me.
I should say that my use of the term epoch is a little off. What I am effectively doing is defining an epoch as iterating over 250 training batches (batch size 40). I have about 80k training images total. Each batch is either sampled randomly or with some probability for each training example from those 80k (there is some class imbalance and I am tackling that by oversampling rare classes).
I will definitely check the numerical values of the running stats before, at and after the collapse. Right now I am not at home though (will have to wait until tomorrow). I will post them asap.
One of my most recent experiments started giving nan values for validation loss. This is typically an indication that some activations are pushed to inf. Interesting. Maybe eps is doing something it shouldn’t?
Best,
Fabian
Thanks for the info.
The strange loss behavior might be also related to your sampling strategy or the input in general.
Could you check all inputs for NaNs or Infs in your training loop or beforehand?
torch.isnan or torch.isinf might be helpful here.
Hi,
all my inputs are normalized. I compute the mean and standard deviation over the dataset and normalize all images with that. There are no nans or infs in the data.
How could this issue be related to my sampling strategy? Oversampling some cases may skew the running stats but not to an extend where everything collapses and especially the models recovering back to normal towards the end of the training (when the lr gets lower) contradicts that.
I don’t quite know how the learning rate interacts with batch norm layers. As far as I remember, the gradient is not stopped for mean and var computation (via something like detach()). Maybe there is something there?
Best,
Fabian
I don’t think the oversampling strategy is bad at all, sorry for the misunderstanding.
Since your current issue occurs randomly, I thought that maybe some batches, which are sampled randomly at a later epoch, might have invalid or very high/low values, thus throwing your running stats off.
If you check the running stats in your training loop, could you also print the min/max/mean/std of the current batch?
Maybe it’s not related to the running stats at all, but to other parameters which might suffer from potentially bad input.
As you see, I’m currently trying to collect all your information and think about some useful debug approaches. 
Hi, yes I will provide those stats as soon as I can. Thank you so much again! I still don’t believe the input has invalid numbers as these are basically uint8 images that are normalized with some mean and std computed over the whole dataset (no infs or nans there). But better safe than sorry, right?
I will also look at the batch norm running stats from different epochs (before, t, after the breakdown). What layer would you recommend I look at for those (it’s a resnet 50)?
Best,
Fabian
Yeah, I think the same. Even if the inputs should be fine, it doesn’t hurt to check them too.
I would suggest to have a look at the BatchNorm layers close to the input. It’s just a feeling, but I guess if something goes wrong it should be somewhere at the beginning of the forward pass.
Hi there,
I could finally look at the network. I used epoch 300, 700 and final for before, during and after the breakdown.
Interestingly I don’t see any weirdness in the batch norm moving stats at the first bn layer:
epoch 300:
In [9]: self.network.bn1.running_mean
Out[9]:
tensor([ 0.0265, -0.1110, -0.1160, 0.0190, 0.1058, -0.0179, -0.0286, 0.0524,
-0.0180, -0.1844, 0.0287, 0.2987, 0.0370, -0.6230, 0.0031, 0.0256,
-0.0679, 0.1194, -0.2744, 0.0251, -0.0909, 0.0986, -0.0009, -0.2132,
0.0537, 0.1174, -0.0971, -0.0125, -0.0445, -0.0024, -0.3101, -0.0073],
device=‘cuda:0’)In [10]: self.network.bn1.running_var
Out[10]:
tensor([ 1.2123, 1.7482, 2.6450, 1.9762, 1.9177, 4.5315, 0.4663, 1.5161,
1.1491, 6.9815, 1.1021, 9.3386, 1.2492, 29.5786, 1.1680, 0.4657,
4.0417, 2.0542, 16.2966, 2.7019, 2.1935, 1.9766, 0.9401, 5.6444,
1.5645, 1.7632, 6.9528, 1.8997, 1.1977, 1.5128, 20.3052, 0.8678],
device=‘cuda:0’)In [11]:
epoch 700:
In [12]: self.network.bn1.running_mean
Out[12]:
tensor([ 0.0273, -0.1171, -0.0941, 0.0393, 0.1386, 0.0285, -0.0054, 0.0831,
-0.0080, -0.1630, 0.0332, 0.3122, 0.0628, -0.4963, -0.0061, 0.0065,
-0.1043, 0.1000, -0.2297, 0.0593, -0.0857, 0.0967, 0.0244, -0.1920,
0.0275, 0.0837, -0.2192, 0.0217, -0.0661, -0.0337, -0.4571, -0.0109],
device=‘cuda:0’)In [13]: self.network.bn1.running_var
Out[13]:
tensor([ 1.1938, 2.7972, 4.3059, 3.4096, 2.8702, 5.8498, 0.5527, 2.3203,
1.7257, 10.2496, 1.3604, 15.1904, 2.0068, 42.5539, 1.6873, 0.5314,
6.4726, 3.1628, 22.7749, 4.3518, 2.8136, 2.8452, 1.9811, 7.4680,
2.3911, 2.3746, 18.5319, 3.0089, 1.7593, 2.4780, 40.4268, 1.4430],
device=‘cuda:0’)In [14]:
final:
In [15]: self.network.bn1.running_mean
Out[15]:
tensor([ 0.0027, -0.1487, -0.1678, 0.0462, 0.1889, 0.0641, 0.0002, 0.0834,
-0.0166, -0.1836, 0.0333, 0.4439, 0.0763, -0.7683, 0.0203, 0.0281,
-0.1092, 0.1382, -0.2974, 0.0031, -0.0821, 0.1381, 0.0201, -0.2344,
0.0412, 0.1326, -0.2208, 0.0218, -0.0966, -0.0137, -0.5406, -0.0126],
device=‘cuda:0’)In [16]: self.network.bn1.running_var
Out[16]:
tensor([ 1.1598, 3.0503, 4.5197, 3.4007, 3.1393, 5.8271, 0.5361, 2.2878,
1.7715, 10.5495, 1.2760, 15.2090, 1.9926, 43.3876, 1.8111, 0.5640,
5.4958, 3.2575, 22.9858, 4.0293, 2.7336, 3.1246, 2.0181, 7.6566,
2.3407, 2.4714, 17.4709, 2.9588, 1.6889, 2.3654, 37.0451, 1.4181],
device=‘cuda:0’)
Here are some descriptive statistics of the running mean and var of the last bn layer (the one that comes after the last convolution in the very last residual block. It has 1024 entries which is why I am providing stats only here)
epoch 300:
In [33]: self.network.layers[-1][-1].bn2.running_mean.max()
Out[33]: tensor(0.2174, device=‘cuda:0’)In [34]: self.network.layers[-1][-1].bn2.running_mean.min()
Out[34]: tensor(-0.6384, device=‘cuda:0’)In [35]: self.network.layers[-1][-1].bn2.running_mean.mean()
Out[35]: tensor(-0.1016, device=‘cuda:0’)In [36]: self.network.layers[-1][-1].bn2.running_mean.var()
Out[36]: tensor(0.0184, device=‘cuda:0’)In [39]: self.network.layers[-1][-1].bn2.running_var.max()
Out[39]: tensor(0.8339, device=‘cuda:0’)In [40]: self.network.layers[-1][-1].bn2.running_var.min()
Out[40]: tensor(4.8037e-34, device=‘cuda:0’)In [41]: self.network.layers[-1][-1].bn2.running_var.mean()
Out[41]: tensor(0.0686, device=‘cuda:0’)In [42]: self.network.layers[-1][-1].bn2.running_var.var()
Out[42]: tensor(0.0122, device=‘cuda:0’)epoch 700:
In [48]: self.network.layers[-1][-1].bn2.running_mean.max()
Out[48]: tensor(0.1805, device=‘cuda:0’)In [49]: self.network.layers[-1][-1].bn2.running_mean.min()
Out[49]: tensor(-0.4298, device=‘cuda:0’)In [50]: self.network.layers[-1][-1].bn2.running_mean.mean()
Out[50]: tensor(-0.0727, device=‘cuda:0’)In [51]: self.network.layers[-1][-1].bn2.running_mean.var()
Out[51]: tensor(0.0118, device=‘cuda:0’)In [44]: self.network.layers[-1][-1].bn2.running_var.max()
Out[44]: tensor(0.2591, device=‘cuda:0’)In [45]: self.network.layers[-1][-1].bn2.running_var.min()
Out[45]: tensor(5.6052e-45, device=‘cuda:0’)In [46]: self.network.layers[-1][-1].bn2.running_var.mean()
Out[46]: tensor(0.0242, device=‘cuda:0’)In [47]: self.network.layers[-1][-1].bn2.running_var.var()
Out[47]: tensor(0.0016, device=‘cuda:0’)final:
In [53]: self.network.layers[-1][-1].bn2.running_mean.max()
Out[53]: tensor(0.0899, device=‘cuda:0’)In [54]: self.network.layers[-1][-1].bn2.running_mean.min()
Out[54]: tensor(-0.4327, device=‘cuda:0’)In [55]: self.network.layers[-1][-1].bn2.running_mean.mean()
Out[55]: tensor(-0.0624, device=‘cuda:0’)In [56]: self.network.layers[-1][-1].bn2.running_mean.var()
Out[56]: tensor(0.0093, device=‘cuda:0’)In [57]: self.network.layers[-1][-1].bn2.running_var.max()
Out[57]: tensor(0.1923, device=‘cuda:0’)In [58]: self.network.layers[-1][-1].bn2.running_var.min()
Out[58]: tensor(5.6052e-45, device=‘cuda:0’)In [59]: self.network.layers[-1][-1].bn2.running_var.mean()
Out[59]: tensor(0.0170, device=‘cuda:0’)In [60]: self.network.layers[-1][-1].bn2.running_var.var()
Out[60]: tensor(0.0009, device=‘cuda:0’)
Batch norm statistics look normal-ish to me although I think running variances of 1e-45 are dangerous (almost division by zero). How can that happen?
I will plot batch statistics in my next post
Here I am showing both training batch statistics as well as statistics of feature maps activations right before the classification layer. Again I use epochs 300, 700 and final (1015) for before, during and after the breakdown. For each epoch, I draw 5 batches and show the aforementioned statistics for training, validation (network.train = False) and validation with network.train = True (I am including the latter to demonstrate that the problem must be the running stats as feature map activations for train=False are off while they are OK for train=Tru). As you can see, input data statistics are consistent for all batches and epochs, so no surprise here. For epoch 300 and final, feature maps statistics are consistent-ish for train, validation (train=False) and validation (train=True). For epoch 700 however (which is where the network breaks down), the feature map activations match between train and val (train=True) but don’t match for validation (train=False; this is where the running stats are applied).
I am also printing the loss for all epochs and phases (train. val, …). Don’t worry about the loss being negative. That is because the F1 loss ranges from 0 to -1 while the BCE is [0, inf] (total loss is the sum and thus ranges from [-1, inf]). In epochs 300 and final the loss between train and validations is basically identical (with some overfitting) while in epoch 700 the loss for validation (train=False) is way too high.
epoch: 300
training: (network is train=True and samples are drawn from training DataLoader)
Input data: max: 8.606085 min: -0.7775649 mean: 0.11011692 var: 1.1633884
Features before classification: max: 17.142632 min: 0.0 mean: 0.24466729 var: 0.29341334Input data: max: 8.5557785 min: -0.7629295 mean: 0.04259184 var: 1.0552053
Features before classification: max: 18.69158 min: 0.0 mean: 0.24318185 var: 0.29009783Input data: max: 8.638606 min: -0.7287697 mean: 0.10248642 var: 1.160278
Features before classification: max: 22.366526 min: 0.0 mean: 0.24295413 var: 0.29546708Input data: max: 8.53746 min: -0.76369715 mean: 0.14483288 var: 1.2324796
Features before classification: max: 15.086981 min: 0.0 mean: 0.24739826 var: 0.28974423Input data: max: 8.563448 min: -0.7089811 mean: 0.08948848 var: 1.133431
Features before classification: max: 32.820637 min: 0.0 mean: 0.24512042 var: 0.28797802
train loss : -0.5370validation: (network is train=False and samples are drawn from validation DataLoader)
Input data: max: 8.53746 min: -0.6521306 mean: 0.07451663 var: 1.0982525
Features before classification: max: 19.99752 min: 0.0 mean: 0.24418607 var: 0.2950879Input data: max: 8.53746 min: -0.6521306 mean: 0.06573128 var: 1.0647457
Features before classification: max: 21.51592 min: 0.0 mean: 0.23669797 var: 0.2616221Input data: max: 8.53746 min: -0.6521306 mean: 0.07230965 var: 1.1099536
Features before classification: max: 34.280563 min: 0.0 mean: 0.26418424 var: 0.3719333Input data: max: 8.53746 min: -0.6521306 mean: 0.16783251 var: 1.3045272
Features before classification: max: 26.123634 min: 0.0 mean: 0.25989175 var: 0.37081867Input data: max: 8.53746 min: -0.6521306 mean: 0.110146575 var: 1.2274413
Features before classification: max: 26.462603 min: 0.0 mean: 0.22915748 var: 0.25221625
val loss (train=False): -0.4176validation (train=True): (network is train=True and samples are drawn from validation DataLoader)
Input data: max: 8.53746 min: -0.6521306 mean: 0.041268155 var: 1.1999401
Features before classification: max: 21.246727 min: 0.0 mean: 0.24235177 var: 0.2917685Input data: max: 8.53746 min: -0.6521306 mean: 0.1290773 var: 1.2299877
Features before classification: max: 23.499233 min: 0.0 mean: 0.2495341 var: 0.28842986Input data: max: 8.53746 min: -0.6521306 mean: 0.077322766 var: 1.0789642
Features before classification: max: 20.976784 min: 0.0 mean: 0.24999543 var: 0.28809312Input data: max: 8.53746 min: -0.6521306 mean: 0.12412989 var: 1.2118222
Features before classification: max: 20.250025 min: 0.0 mean: 0.25311542 var: 0.28560916Input data: max: 8.53746 min: -0.6521306 mean: 0.058781143 var: 1.1097133
Features before classification: max: 16.501434 min: 0.0 mean: 0.2545616 var: 0.28281626
val loss (train=True): -0.5057epoch: 700
training: (network is train=True and samples are drawn from training DataLoader)
Input data: max: 8.55883 min: -0.77725536 mean: 0.11748674 var: 1.1631266
Features before classification: max: 15.908981 min: 0.0 mean: 0.2101385 var: 0.21815181Input data: max: 8.53746 min: -0.7591846 mean: 0.16579734 var: 1.1916564
Features before classification: max: 16.09063 min: 0.0 mean: 0.21404302 var: 0.21558203Input data: max: 8.555547 min: -0.6906217 mean: 0.101644285 var: 1.1464278
Features before classification: max: 17.098934 min: 0.0 mean: 0.2126852 var: 0.21343498Input data: max: 8.594714 min: -0.74816304 mean: 0.10817674 var: 1.1627903
Features before classification: max: 17.051395 min: 0.0 mean: 0.20846856 var: 0.21932985Input data: max: 8.563169 min: -0.78391445 mean: 0.051834863 var: 1.0531709
Features before classification: max: 18.298471 min: 0.0 mean: 0.20677677 var: 0.21607172
train loss : -0.6972validation: (network is train=False and samples are drawn from validation DataLoader)
Input data: max: 8.53746 min: -0.6521306 mean: 0.13776894 var: 1.1895192
Features before classification: max: 9.838846 min: 0.0 mean: 0.14135005 var: 0.07449843Input data: max: 8.53746 min: -0.6521306 mean: 0.16435458 var: 1.2554524
Features before classification: max: 10.988285 min: 0.0 mean: 0.1407173 var: 0.0791312Input data: max: 8.53746 min: -0.6521306 mean: -0.014078559 var: 0.9748203
Features before classification: max: 11.078625 min: 0.0 mean: 0.13703124 var: 0.0729197Input data: max: 8.53746 min: -0.6521306 mean: 0.07416497 var: 1.1208515
Features before classification: max: 26.292133 min: 0.0 mean: 0.14437278 var: 0.093446925Input data: max: 8.53746 min: -0.6521306 mean: 0.06462406 var: 1.1092615
Features before classification: max: 10.157297 min: 0.0 mean: 0.14090487 var: 0.08402736
val loss (train=False): 0.1353validation (train=True): (network is train=True and samples are drawn from validation DataLoader)
Input data: max: 8.53746 min: -0.6521306 mean: 0.10422288 var: 1.2318301
Features before classification: max: 16.510902 min: 0.0 mean: 0.20996732 var: 0.21453643Input data: max: 8.53746 min: -0.6521306 mean: 0.058634315 var: 1.1580375
Features before classification: max: 20.746746 min: 0.0 mean: 0.20406458 var: 0.21710423Input data: max: 8.53746 min: -0.6521306 mean: 0.096261665 var: 1.1046003
Features before classification: max: 20.254076 min: 0.0 mean: 0.20849131 var: 0.21499783Input data: max: 8.53746 min: -0.6521306 mean: 0.124039836 var: 1.2028973
Features before classification: max: 19.05787 min: 0.0 mean: 0.2078148 var: 0.2171791Input data: max: 8.53746 min: -0.6521306 mean: 0.13756868 var: 1.1901097
Features before classification: max: 17.98934 min: 0.0 mean: 0.21233286 var: 0.21371831
val loss (train=True): -0.4974epoch: 1015
training: (network is train=True and samples are drawn from training DataLoader)
Input data: max: 8.591203 min: -0.744614 mean: 0.12869895 var: 1.2715969
Features before classification: max: 15.38456 min: 0.0 mean: 0.22904472 var: 0.23167339Input data: max: 8.543597 min: -0.75908107 mean: 0.04424698 var: 1.0194602
Features before classification: max: 20.93504 min: 0.0 mean: 0.22539279 var: 0.22878553Input data: max: 8.600206 min: -0.7582485 mean: 0.08429426 var: 1.2217238
Features before classification: max: 16.953554 min: 0.0 mean: 0.22585449 var: 0.23169553Input data: max: 8.589985 min: -0.74655396 mean: 0.009551339 var: 0.94260657
Features before classification: max: 15.600396 min: 0.0 mean: 0.22332579 var: 0.22921476Input data: max: 8.6038065 min: -0.75667745 mean: 0.11769733 var: 1.1169093
Features before classification: max: 21.059433 min: 0.0 mean: 0.22816601 var: 0.23191863
train loss : -0.7191validation: (network is train=False and samples are drawn from validation DataLoader)
Input data: max: 8.53746 min: -0.6521306 mean: 0.057770584 var: 1.0422962
Features before classification: max: 18.795538 min: 0.0 mean: 0.21927223 var: 0.20996067Input data: max: 8.53746 min: -0.6521306 mean: 0.03980498 var: 1.0491408
Features before classification: max: 19.233257 min: 0.0 mean: 0.2139626 var: 0.1971896Input data: max: 8.53746 min: -0.6521306 mean: 0.05019422 var: 1.0788214
Features before classification: max: 22.418144 min: 0.0 mean: 0.23339844 var: 0.25270167Input data: max: 8.53746 min: -0.6521306 mean: 0.12727928 var: 1.2005315
Features before classification: max: 18.214798 min: 0.0 mean: 0.23262215 var: 0.25595525Input data: max: 8.53746 min: -0.6521306 mean: 0.09293718 var: 1.1846416
Features before classification: max: 18.957647 min: 0.0 mean: 0.22007352 var: 0.21793382
val loss (train=False): -0.5545validation (train=True): (network is train=True and samples are drawn from validation DataLoader)
Input data: max: 8.53746 min: -0.6521306 mean: 0.121076666 var: 1.3058403
Features before classification: max: 19.245342 min: 0.0 mean: 0.23451522 var: 0.22419384Input data: max: 8.53746 min: -0.6521306 mean: 0.15040742 var: 1.227032
Features before classification: max: 19.016422 min: 0.0 mean: 0.23178016 var: 0.2272836Input data: max: 8.53746 min: -0.6521306 mean: 0.18541424 var: 1.3306359
Features before classification: max: 18.303911 min: 0.0 mean: 0.2370149 var: 0.22376394Input data: max: 8.53746 min: -0.6521306 mean: 0.036099356 var: 0.971277
Features before classification: max: 21.868843 min: 0.0 mean: 0.23125803 var: 0.22653475Input data: max: 8.53746 min: -0.6521306 mean: 0.07943766 var: 1.2029198
Features before classification: max: 23.589802 min: 0.0 mean: 0.23089185 var: 0.22577839
val loss (train=True): -0.5044
If you need anything else please let me know!
Best,
Fabian
Thanks for the detailed debugging!
I’m currently not sure what’s going on and try to thing about a sane way to debug this issue.
No worries. I very much appreciate that you are willing to spend some of your valuable time to figure this out!
I found out that by setting the initial learning rate to 6e-5 instead of 3e-4 (reduced by factor 5) will make this problem go away. So I am not in a hurry to figure this out right now. Still I think it would be interesting to understand what is going on, because I am definitely not getting divergence (training loss is very smooth and behaves as expected).
Here are some more observations that may help understand the issue:
- Training with instance norm (track_running_stats=False) or group norm will never exhibit the behavior shown above.
- Deeper architectures may be more robust to the problem mentioned here (this is a Resnet 50, Resnet 152 is stable, but interestingly Resnet 101 breaks completely and will not recover. Note that I am reducing the batch size when training larger models to accommodate everything on my GPU (patch size is 512x512))
- The issue might be related to the loss function. My gut feeling is that running BCE loss only (no F1 loss) is less likely to run into this issue. F1 loss is not as nicely defined as BCE and I believe it may send very high gradients from time to time (I would need to check this though)
Best,
Fabian
Thanks for the detailed information!
I think I was a bit mislead by the strange behavior and assumed some invalid inputs/updates/running estimates etc. Based on your description it seems the training setup is just creating this issue. I’m not sure if it’s possible or worth “debugging” it, as you already found some workarounds. 
I am facing the same problem, and I guess that the reason is due to for some batches and some layers, the inputs are all negative before relu and thus become zero, for depthwise layers. These will make the running stats gradually become very small values, and thus making the weights very large. Large weights typically will cause overfitting issue, and this is the reason why the training loss is small but validation loss is huge. I checked it and as the running_var is 5.6052e-45, the ratio between weight and bn std (which will become 3.162e-3, i.e. sqrt(1e-5) as bn.eps is 1e-5) will be around thousands. I wonder what will be the proper way if for some batch all inputs are zero. I tried to set bn.eps to 0.1 but although the weight are not huge, there is still strong overfitting (because in this case the BN might not work properly as the running stats are not collected correctly). BTW, I did not apply weight decay for depthwise conv weights.