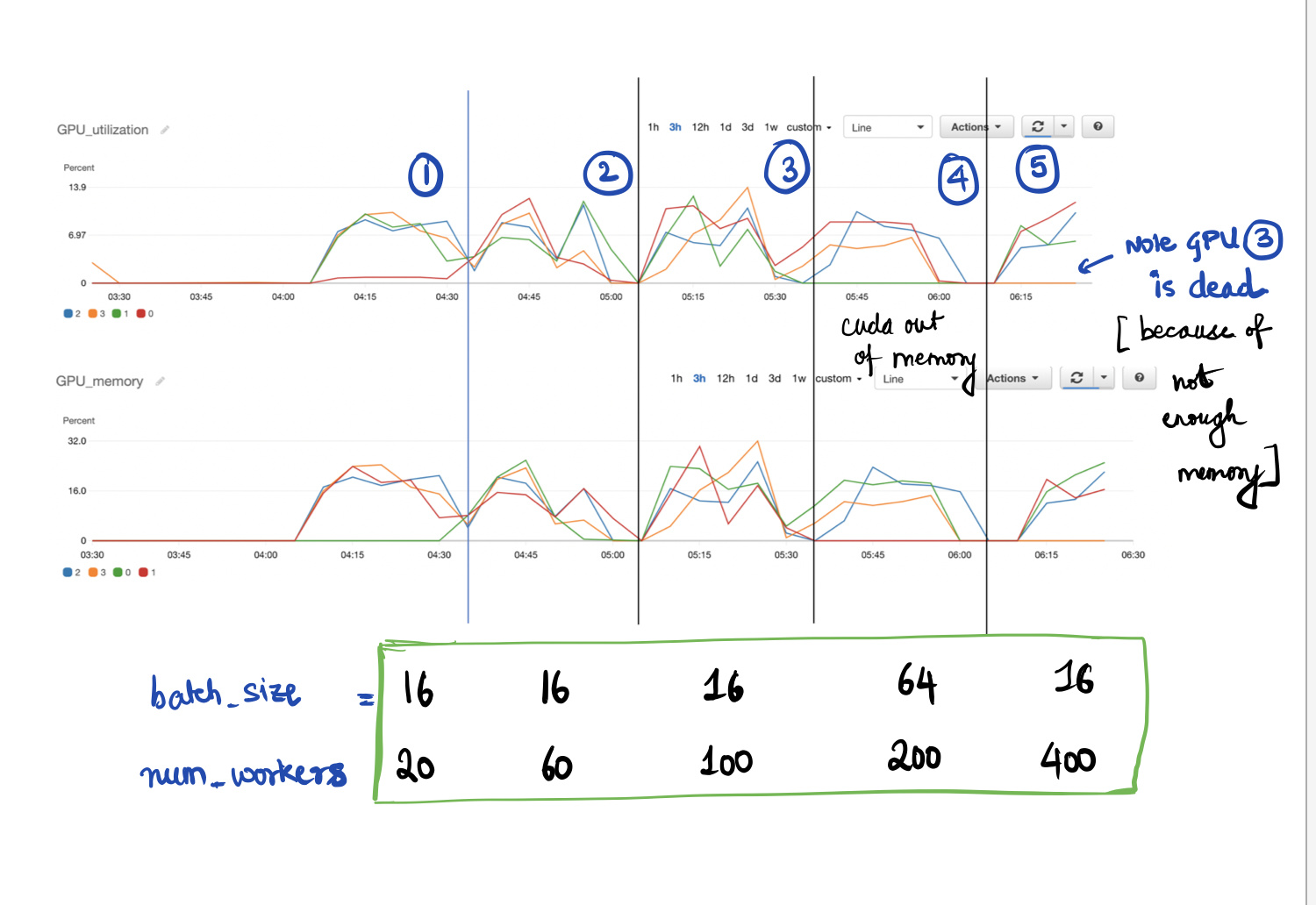
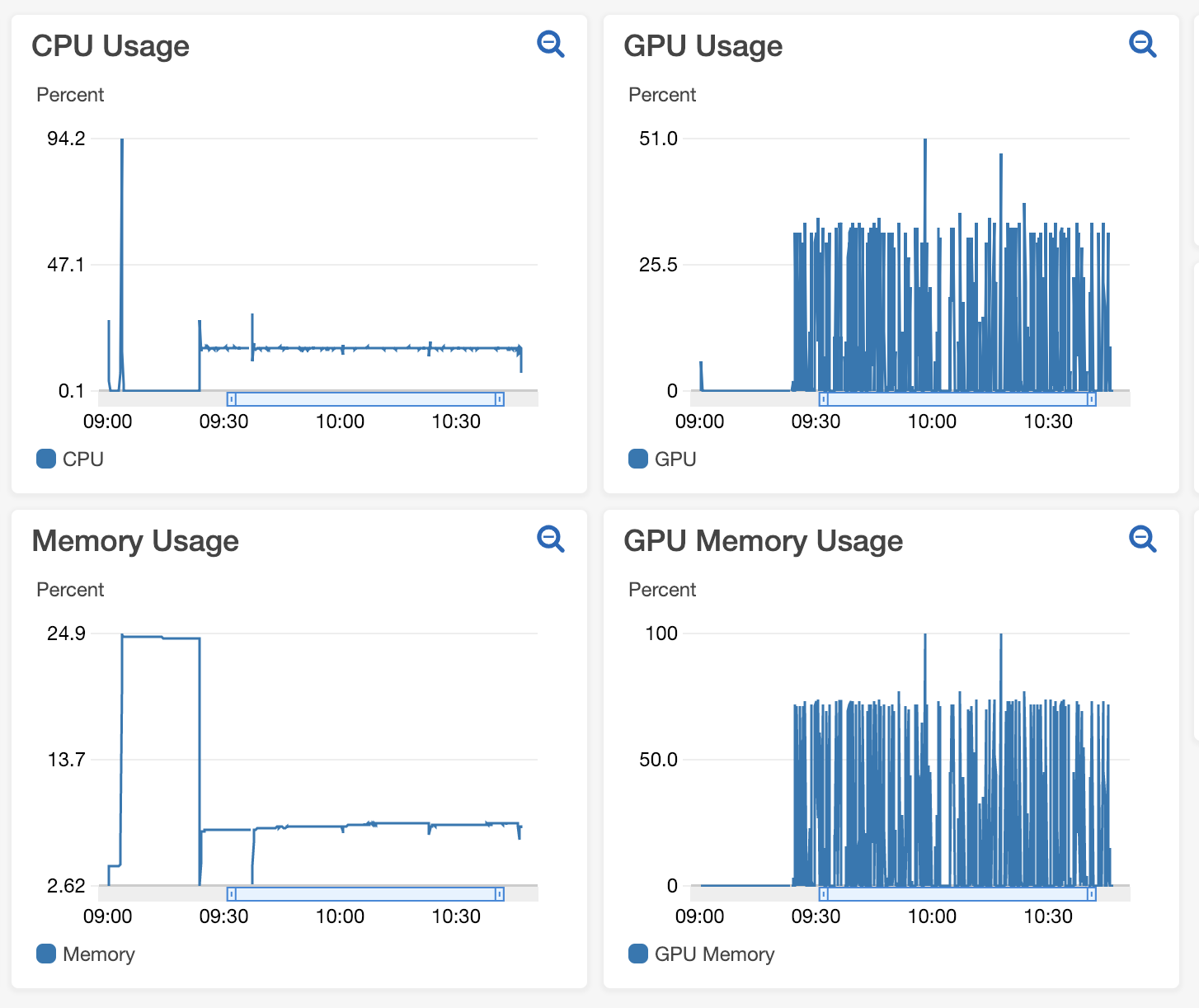
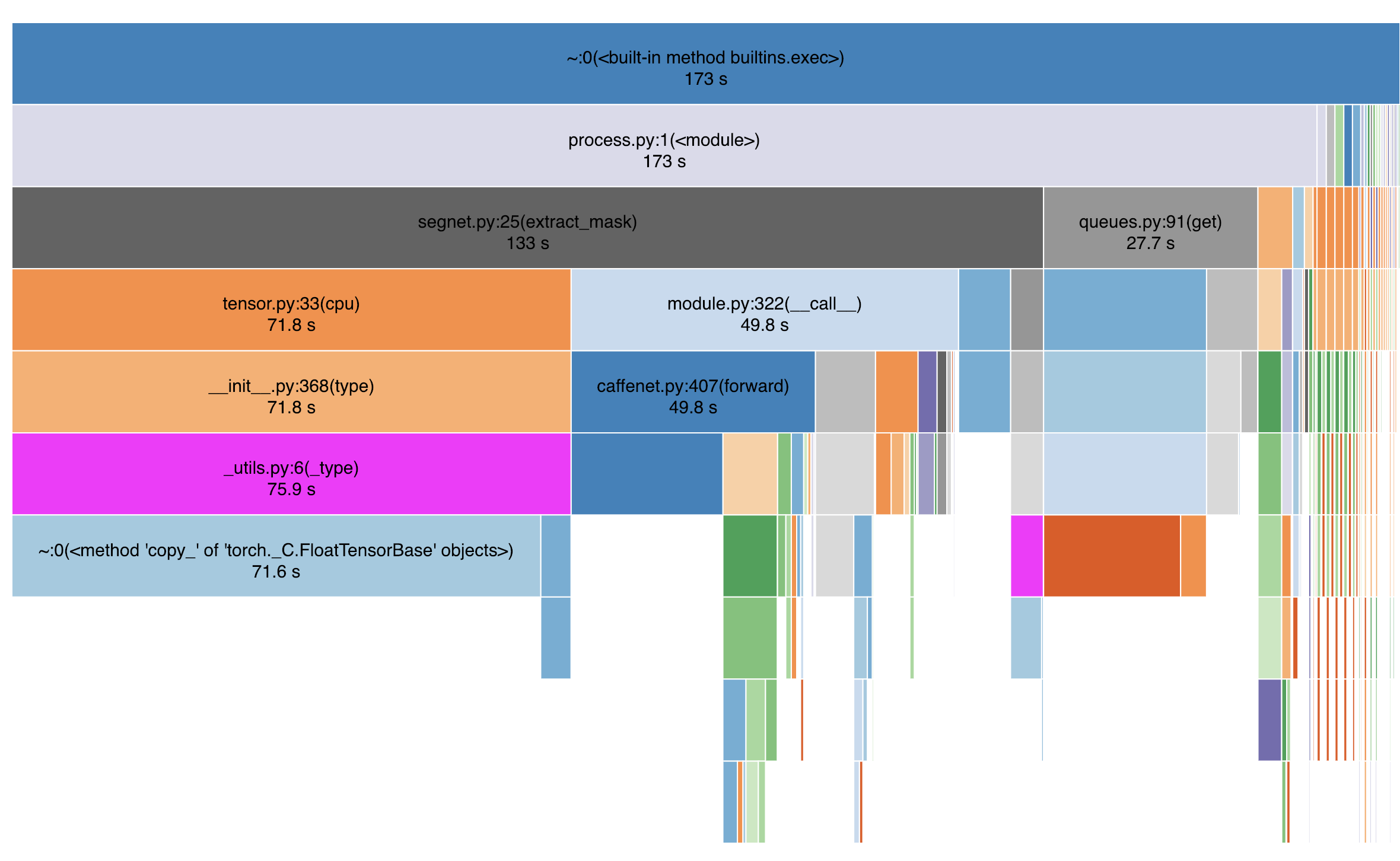
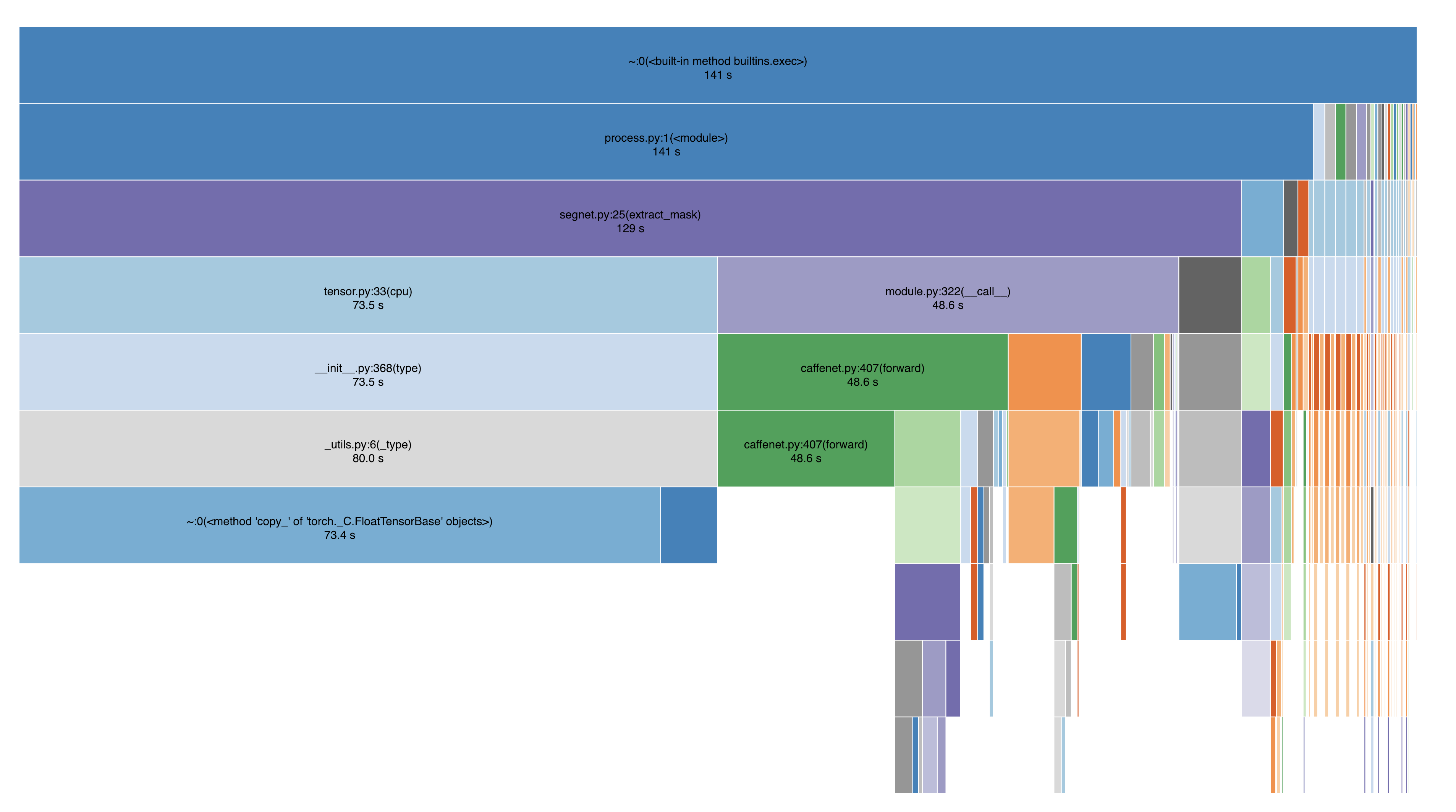
That seems like an awful lot of num_workers. I haven’t used any AWS GPUs but when I run locally I typically have the num_workers=8, which is plenty for most models to bottleneck elsewhere.
Is it possible that the code is bottlenecked elsewhere than the GPU / data reading?
Do you have a way to see if the code is bottlenecked? I ran a small experiment to track time taken by each step when processing approx 36k records with batch size of 16.
One very easy way to measure time in your program is the snakeviz package. I don’t think it can iron out all questions since it doesn’t really understand GPU stuff but is quick & easy to start with. Nvidia has GPU-profiler tool but I haven’t got it to work very well
This step initializes your dataloader but doesn’t actually read your data. It shouldn’t take 23 seconds though. Mine takes like a second but idk.
Here you are reading your data and putting it through you model. The time spend is correlated to how much data you have.
for (cids, img_batch, heatmap_batch, tag_batch) in dataloader:
output_probs = model.extract_mask(img_batch, heatmap_batch)
q.put((cids, output_probs, tag_batch))
The GPU utilization is dependant on your model & input size. Could you try number_of_workers = 8 with batch_size=16, and then batch_size=32 and report the differences?
A few clarifications, during the __init__ call of the Dataloader, I actually end up reading, decoding and resizing images. This was the reason why it took 23 seconds. I moved the read/decode/resize steps in the __getitem__ module and now, the dataloader takes just over a 1 second to initialize – where it doesn’t read data – simply loops through it to calculate the length of the dataset (each image file can be input variable number of times). (Reference : Inference Code Optimizations+ DataLoader - #2 by ptrblck)
Revisiting the dataloader’s initialization parameters here:
With, NUM_PREPROCESS_WORKERS = 8 and BATCH_SIZE = 16, subsequently varied the batch size = 32, the metrics for GPU/CPU utilization and their memory usage are shown here:
Here is a Snakeviz profiler with Batch Size = 16 and num_workers = 8, total batch inference item 164.95 seconds for 2302 batches at 224 frames per second.
Below is the Snakeviz profiler with Batch Size = 32 and num_workers = 8, total batch inference time 139 seconds for 1151 batches at 264 frames per second
Hello again! I’m out traveling so will be brief. It seems like you are doing some kind of copy in your extract_mask function that takes a long time. It seems to be on your cpu. This could be your culprit
Thanks – the copy in the extract_mask function moves the current batch of images from CPU to a GPU device. Here is the pseudo code for the function:
def extract_mask(self, image_batch):
#image_batch is the batch obtained from the dataloader.
image_var = Variable(torch.Tensor(len(image_batch), 3, 224, 224), requires_grad=False).type(self.dtype_float).cuda(device=self.gpu_id)
image_var.data.copy_(image_batch)
output = self.model(image_var).cpu().numpy()
return output
I probably should have mentioned this earlier – I am using pytorch0.3.1. Here’s a workaround which avoids the copy altogether.
def extract_mask(self, image_batch):
#image_batch is the batch obtained from the dataloader.
image_batch = Variable(torch.squeeze(image_batch), requires_grad=False).type(self.dtype_float).cuda(device=self.gpu_id)
output = self.model(image_var).cpu().numpy()
return output
I’m not sure about version 0.3 but can’t you wrap your image_batch from the loader in a variable without the extra copy? Or somehow return the needed tensor from the loader directly
Thanks for the inputs – I think your suggestions removing the explicit copy and using the Variable to wrap the tensor largely helped in speed-up, but I encountered something quite strange about the inference which I think warranted a new post here : [pytorch0.3.1] Forward pass takes 10x longer time for every 2nd batch inference