A few clarifications, during the __init__ call of the Dataloader, I actually end up reading, decoding and resizing images. This was the reason why it took 23 seconds. I moved the read/decode/resize steps in the __getitem__ module and now, the dataloader takes just over a 1 second to initialize – where it doesn’t read data – simply loops through it to calculate the length of the dataset (each image file can be input variable number of times). (Reference : Inference Code Optimizations+ DataLoader - #2 by ptrblck)
Revisiting the dataloader’s initialization parameters here:
dataloader = torch.utils.data.DataLoader(dataset, batch_size=BATCH_SIZE, shuffle=False, num_workers=NUM_PREPROCESS_WORKERS, drop_last=False, collate_fn=filtered_collate_fn)
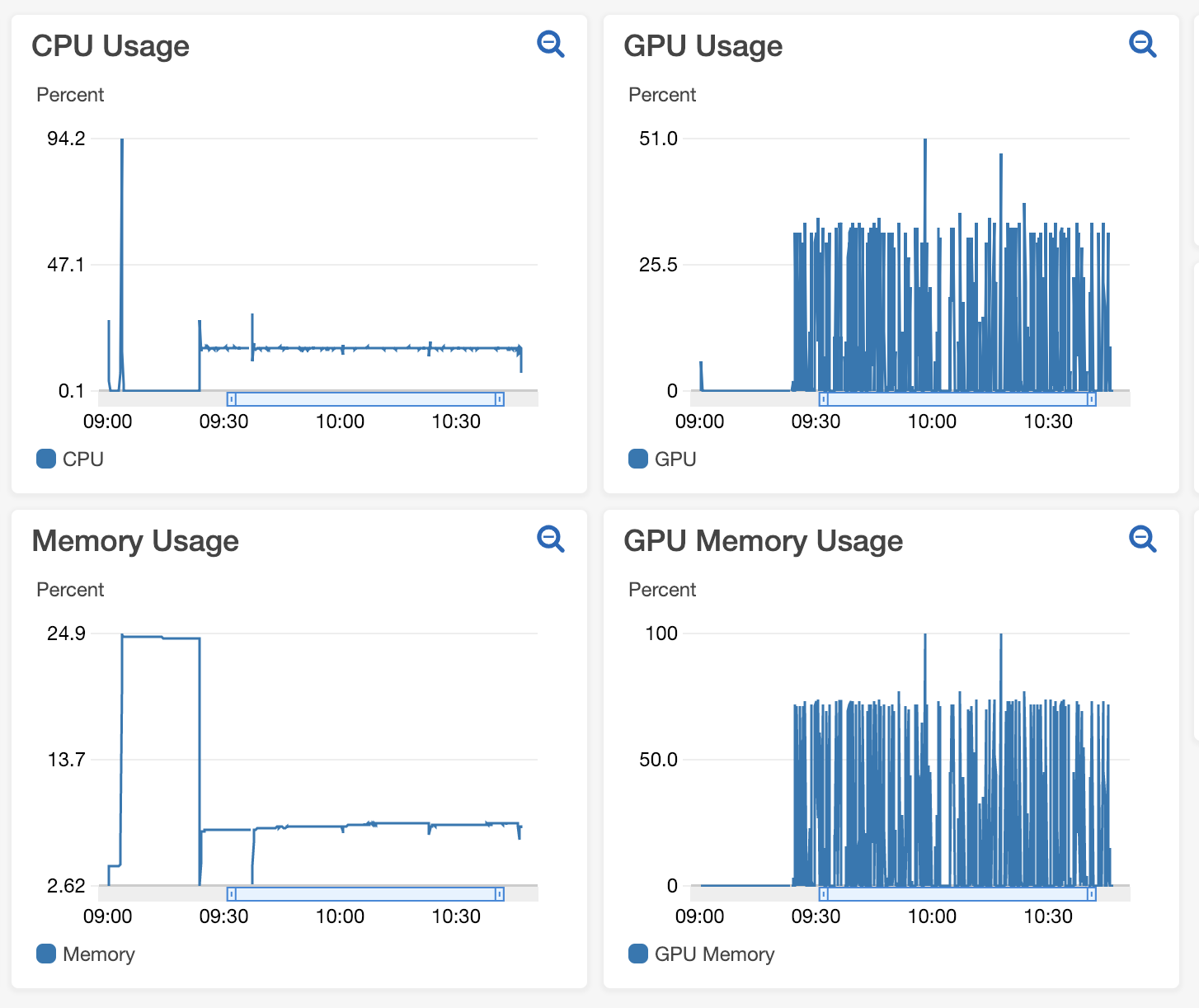
With, NUM_PREPROCESS_WORKERS = 8 and BATCH_SIZE = 16, subsequently varied the batch size = 32, the metrics for GPU/CPU utilization and their memory usage are shown here:
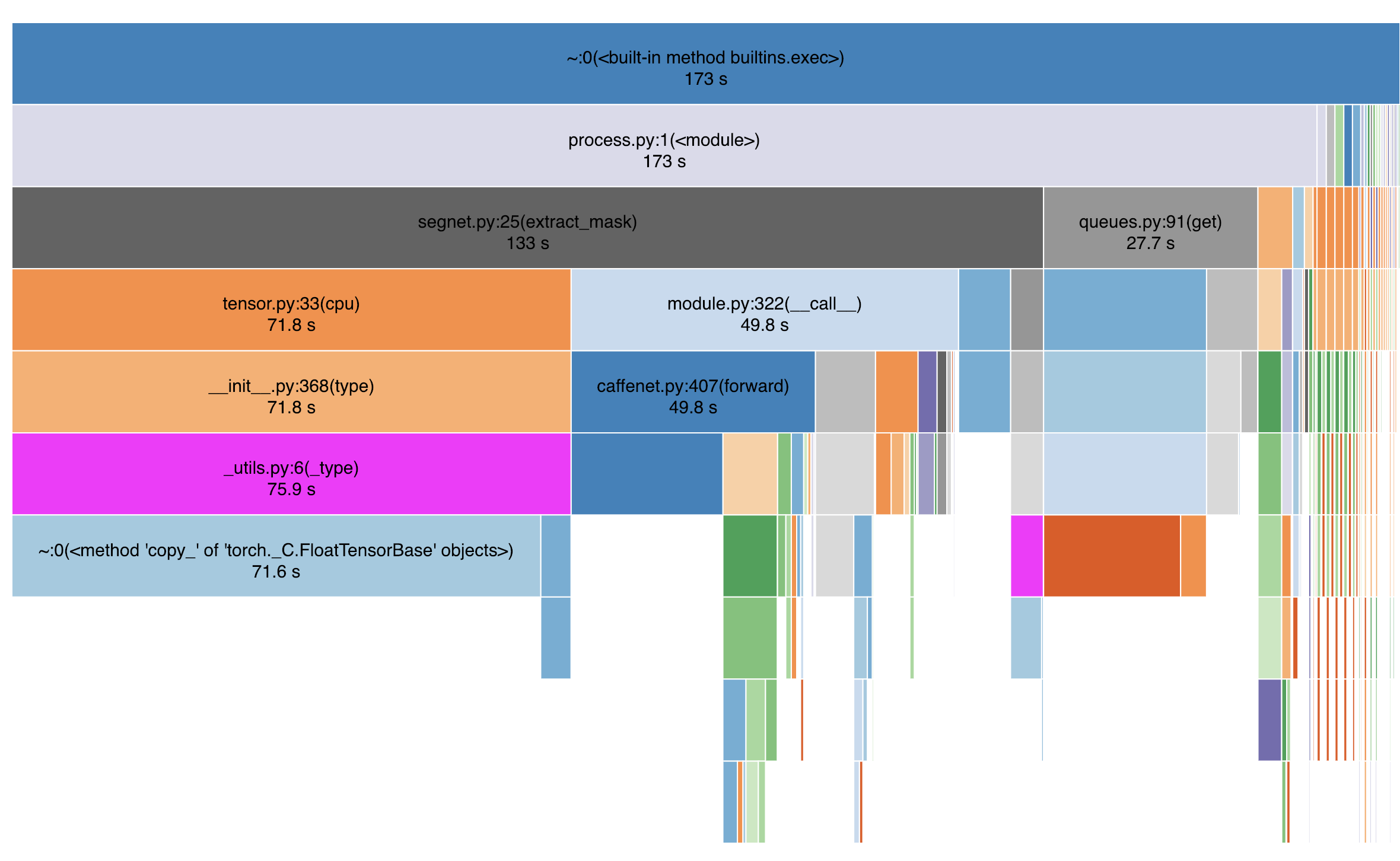
Here is a Snakeviz profiler with Batch Size = 16 and num_workers = 8, total batch inference item 164.95 seconds for 2302 batches at 224 frames per second.

Below is the Snakeviz profiler with Batch Size = 32 and num_workers = 8, total batch inference time 139 seconds for 1151 batches at 264 frames per second