I used random_split() to divide my data into train and test and I observed that if random split is done after the dataloader is created, batch size is missing when getting a batch of data from the dataloader.
import torch
from torchvision import transforms, datasets
from torch.utils.data import random_split
# Normalize the data
transform_image = transforms.Compose([transforms.Resize((240, 320)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
data = '/data/imgs/train'
def load_dataset():
data_path = data
main_dataset = datasets.ImageFolder(
root = data_path,
transform = transform_image
)
loader = torch.utils.data.DataLoader(
dataset = main_dataset,
batch_size= 64,
num_workers = 0,
shuffle= True
)
# Dataset has 22424 data points
trainloader, testloader = random_split(loader.dataset, [21000, 1424])
return trainloader, testloader
trainloader, testloader = load_dataset()
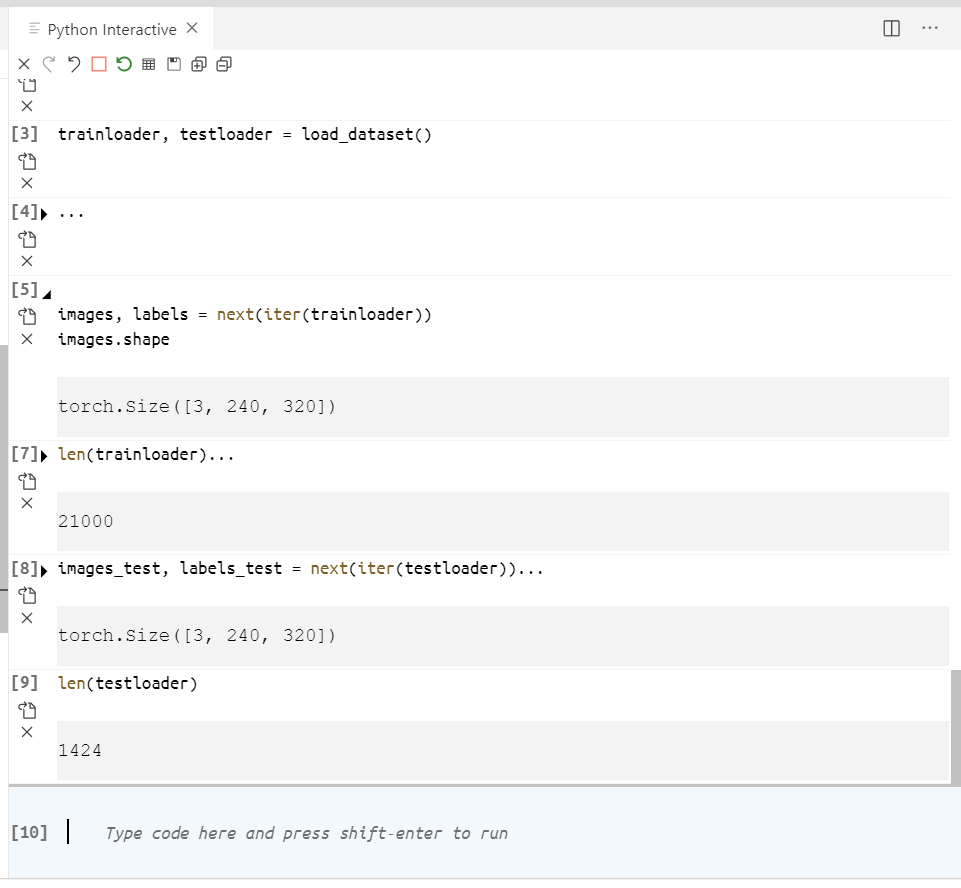
Now to get a single batch of images from the train and test loaders:
images, labels = next(iter(trainloader))
images.shape
# %%
len(trainloader)
# %%
images_test, labels_test = next(iter(testloader))
images_test.shape
# %%
len(testloader)
The output that I get is does not have the batch size for train or test batches. Teh output dims should be [batch x channel x H x W] but I get [channel x H x W].
Output:
But if I create the split from the dataset and then make two data loaders using the splits, I get the batchsize in the output.
def load_dataset():
data_path = data
main_dataset = datasets.ImageFolder(
root = data_path,
transform = transform_image
)
# Dataset has 22424 data points
train_data, test_data = random_split(main_dataset, [21000, 1424])
trainloader = torch.utils.data.DataLoader(
dataset = train_data,
batch_size= 64,
num_workers = 0,
shuffle= True
)
testloader = torch.utils.data.DataLoader(
dataset = test_data,
batch_size= 64,
num_workers= 0,
shuffle= True
)
return trainloader, testloader
trainloader, testloader = load_dataset()
On running the same 4 commands to get a single train and test batch:
images, labels = next(iter(trainloader))
images.shape
# %%
len(trainloader)
# %%
images_test, labels_test = next(iter(testloader))
images_test.shape
# %%
len(testloader)
Output:
>>> images, labels = next(iter(trainloader))
>>> images.shape
torch.Size([64, 3, 240, 320])
>>> len(trainloader)
329
>>> images_test, labels_test = next(iter(testloader))
>>> images_test.shape
torch.Size([64, 3, 240, 320])
len(testloader)
>> 23
Is the first approach wrong? Although the length shows that the data has been split. So why do I not see the batch size?