Hello. I often have problem with BatchNorm, in that the performance in eval mode would sometime be same as training, but sometime really terrible.
I am trying to figure out why. My intuition is that this is due to my dataset being skewed: all the images have a black background, but some of them have a more whiteish one.
The distribution of the mean and the distribution of the std are these: (means are the lefty ones)
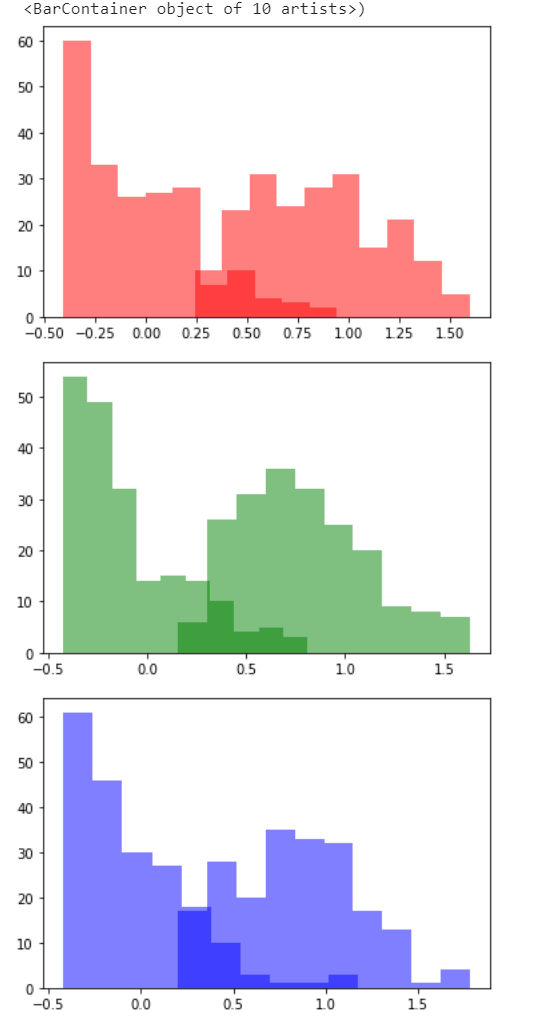
In trying to understand this problem, I noticed that for the network with poor performance in eval mode, the value of the variances were much higher than for “good” networks.
Here are some values (the first is mean, the second is the var).
For the first BN (just after the first Conv2d):
NET BAD
tensor([ -29.7781, 12.2391, 23.6753, -104.0024, 41.8766, 2.4002,
-55.7226, -74.3893, -6.8605, -5.5303, -48.4950, -29.0208,
-48.0712, -4.6871, 34.7236, -81.7126])
tensor([1168.8204, 1333.6073, 1443.5244, 1555.0339, 4267.8091, 2111.3704,
3346.2190, 532.1592, 2811.8247, 1326.7656, 637.5374, 2931.4590,
5801.2495, 304.0882, 1355.9142, 1533.3816])
NET OK
tensor([ -6.3274, -6.1664, -10.3942, -28.1151, -32.2096, -26.3078,
-10.4175, 24.2008, 9.8370, -28.2507, -11.6322, -103.5681,
-17.6847, -96.9272, -49.0244, 63.0846])
tensor([ 337.0145, 1712.8109, 828.4286, 2091.9353, 633.8458, 708.2406,
2287.5337, 573.3295, 542.3098, 674.4161, 57.8019, 472.7914,
657.8156, 737.7748, 2858.6477, 1976.5887])
that’s the third one:
NET BAD
tensor([ -10.8050, -10.0810, -22.0457, -82.5262, -21.4268, -9.6424,
-10.5871, -33.9720, -84.1516, 73.2415, -8.3528, -110.5475,
7.6087, 2.2641, 11.9220, 76.5386, -10.3947, 3.2418,
-6.6089, -88.2742, -87.0283, -7.2630, 13.3461, 32.5284,
3.8708, 45.4371, -168.6165, 21.6379, 3.0647, 9.7506,
14.0491, -9.1878])
tensor([1866.1067, 989.6725, 1440.4335, 965.3045, 1072.2700, 571.4302,
1800.5798, 1263.7515, 4106.1826, 2058.5813, 471.3941, 1957.0736,
429.0413, 883.9999, 447.6416, 1816.3220, 456.4415, 627.9471,
1309.5115, 3057.8555, 1091.8715, 356.6866, 1954.8237, 2371.0234,
335.0525, 1099.3934, 2290.0330, 2312.5876, 416.2901, 291.2235,
3787.5928, 453.0023])
NET OK
tensor([-26.5261, -69.3727, -30.0037, -3.9418, -28.6060, 38.6399, -45.1631,
11.0785, -1.1198, -26.1849, 9.6592, -3.4503, -3.4043, 11.4427,
-28.9705, -3.3149, -52.3700, -3.3219, 12.2578, -23.9428, -19.1247,
-12.7559, -9.2799, 8.2808, -3.2020, 2.8411, -24.3510, -3.1824,
-18.1458, -41.0777, -27.6033, 8.5813])
tensor([125.9260, 212.6366, 233.6038, 147.7983, 275.0836, 200.1759, 367.1238,
211.6418, 150.5029, 214.7287, 129.6201, 350.4520, 60.3252, 138.1244,
130.3971, 179.9324, 236.7250, 192.1243, 176.6954, 239.2098, 111.9044,
213.8963, 192.9032, 102.0731, 131.3873, 183.7588, 193.3373, 272.2289,
135.4212, 202.1502, 193.4987, 94.3308])
I also discovered that using a momentum of 0.9 does get rid of the problem and the performance is great on both train and eval. But why would that be the case? Whatever the momentum, the BN should soon-ish converge to the same value, whereas in my case the performance is more or less equally bad throughout many epochs.
Anyway, I got the solution (momentum) but I am really unsatisfied as I don’t understand what’s going on here.
Can anyone provide any insight? Thanks! ![]()