Hi eqy,
I now ran:
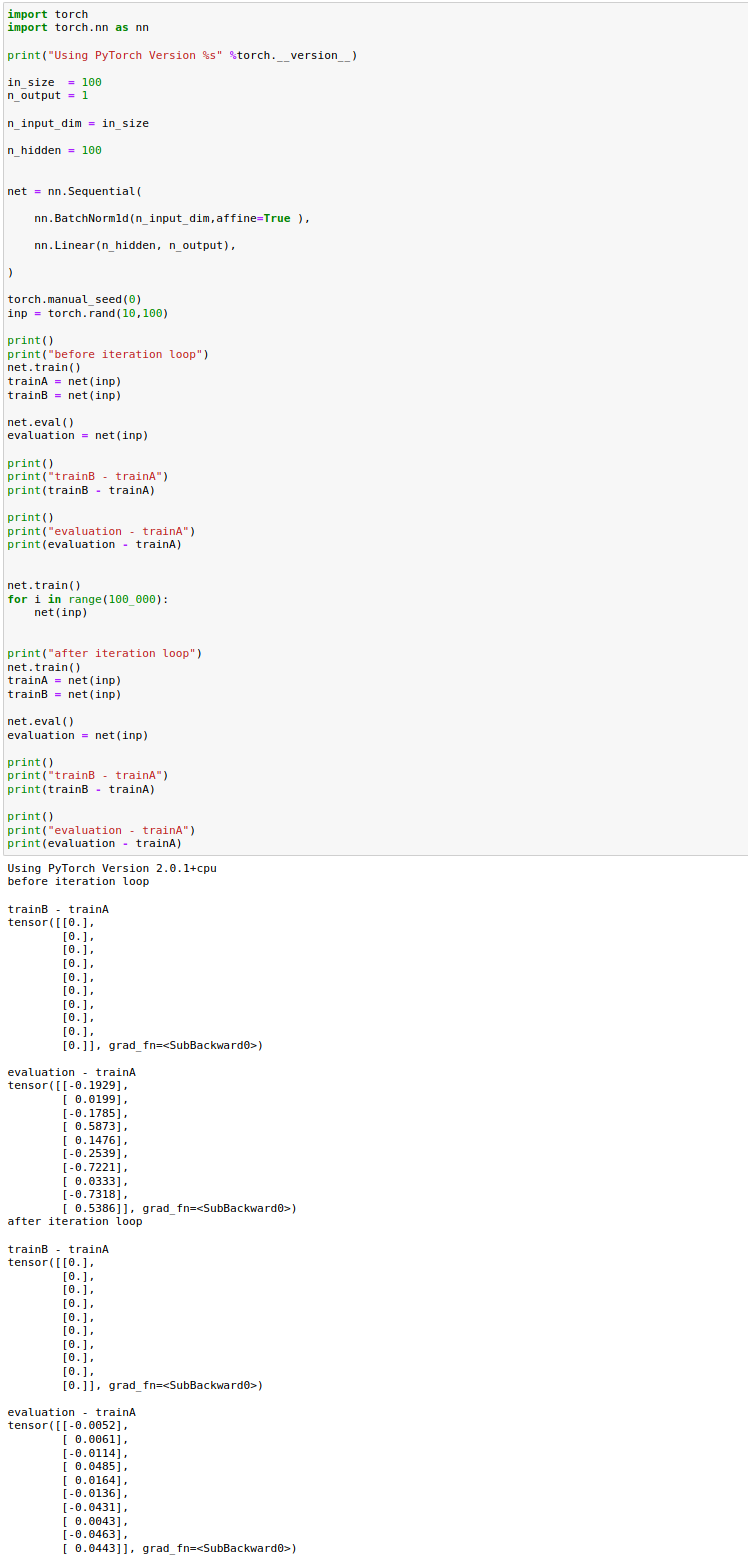
“”"
import torch
import torch.nn as nn
print("Using PyTorch Version %s" %torch.__version__)
in_size = 100
n_output = 1
n_input_dim = in_size
n_hidden = 100
net = nn.Sequential(
nn.BatchNorm1d(n_input_dim,affine=True ,momentum = 0.9),
nn.Linear(n_hidden, n_output),
)
torch.manual_seed(0)
inp = torch.rand(10,100)
print()
print("before iteration loop")
net.train()
trainA = net(inp)
trainB = net(inp)
net.eval()
evaluation = net(inp)
print()
print("trainB - trainA")
print(trainB - trainA)
print()
print("evaluation - trainA")
print(evaluation - trainA)
net.train()
for i in range(100_000):
net(inp)
print("running_mean")
print( net.state_dict()["0.running_mean"] )
print("running_var")
print( net.state_dict()["0.running_var"] )
for i in range(10_000_000):
net(inp)
print("running_mean")
print( net.state_dict()["0.running_mean"] )
print("running_var")
print( net.state_dict()["0.running_var"] )
print("after iteration loop")
net.train()
trainA = net(inp)
trainB = net(inp)
net.eval()
evaluation = net(inp)
print()
print("trainB - trainA")
print(trainB - trainA)
print()
print("evaluation - trainA")
print(evaluation - trainA)
"""
with the result:
“”"
Using PyTorch Version 2.0.1+cpu
before iteration loop
trainB - trainA
tensor([[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.]], grad_fn=<SubBackward0>)
evaluation - trainA
tensor([[-0.0313],
[ 0.0118],
[-0.0051],
[ 0.0899],
[ 0.0310],
[-0.0294],
[-0.1170],
[ 0.0252],
[-0.1052],
[ 0.0898]], grad_fn=<SubBackward0>)
running_mean
tensor([0.5088, 0.6670, 0.3810, 0.5606, 0.4588, 0.4557, 0.5589, 0.5949, 0.4525,
0.5722, 0.3712, 0.4629, 0.4938, 0.3754, 0.6282, 0.5713, 0.3683, 0.5272,
0.6635, 0.5736, 0.6476, 0.5023, 0.4490, 0.4922, 0.4125, 0.3985, 0.6730,
0.2649, 0.4704, 0.3969, 0.5462, 0.6128, 0.4573, 0.5381, 0.4119, 0.4991,
0.5438, 0.3370, 0.5581, 0.5255, 0.4137, 0.4987, 0.5979, 0.5043, 0.3674,
0.6004, 0.5504, 0.5365, 0.3826, 0.4306, 0.3937, 0.5267, 0.6587, 0.4738,
0.5307, 0.4332, 0.4600, 0.5151, 0.3925, 0.3587, 0.3423, 0.5201, 0.4529,
0.4896, 0.5712, 0.5956, 0.5171, 0.4880, 0.4438, 0.6315, 0.5038, 0.5011,
0.5118, 0.5845, 0.4569, 0.5135, 0.6359, 0.4807, 0.5716, 0.5164, 0.4200,
0.3237, 0.4433, 0.6070, 0.5800, 0.6215, 0.4976, 0.4250, 0.5063, 0.6422,
0.5114, 0.5958, 0.5699, 0.5832, 0.4281, 0.4176, 0.4490, 0.4129, 0.5347,
0.5866])
running_var
tensor([0.1170, 0.0552, 0.1209, 0.1130, 0.0925, 0.0819, 0.0968, 0.1087, 0.0262,
0.0297, 0.0328, 0.0522, 0.1047, 0.0707, 0.0713, 0.0651, 0.0528, 0.0545,
0.0546, 0.0703, 0.0448, 0.1295, 0.0633, 0.0918, 0.0917, 0.0963, 0.0891,
0.0287, 0.0784, 0.0363, 0.1142, 0.1252, 0.1155, 0.0732, 0.1299, 0.0803,
0.0495, 0.1242, 0.0754, 0.1059, 0.0840, 0.0896, 0.0642, 0.0593, 0.0876,
0.1371, 0.1110, 0.1040, 0.0339, 0.0738, 0.1149, 0.1198, 0.1107, 0.0914,
0.0784, 0.0942, 0.0482, 0.1069, 0.0771, 0.0470, 0.0809, 0.0950, 0.1216,
0.1473, 0.0880, 0.0943, 0.0451, 0.0964, 0.1160, 0.0544, 0.1133, 0.0884,
0.1439, 0.0576, 0.1036, 0.1378, 0.0962, 0.1441, 0.1185, 0.1162, 0.1056,
0.1019, 0.1086, 0.0990, 0.0285, 0.0959, 0.0521, 0.0896, 0.0557, 0.0582,
0.0470, 0.0891, 0.1031, 0.0864, 0.0999, 0.0762, 0.1290, 0.0753, 0.0914,
0.0715])
running_mean
tensor([0.5088, 0.6670, 0.3810, 0.5606, 0.4588, 0.4557, 0.5589, 0.5949, 0.4525,
0.5722, 0.3712, 0.4629, 0.4938, 0.3754, 0.6282, 0.5713, 0.3683, 0.5272,
0.6635, 0.5736, 0.6476, 0.5023, 0.4490, 0.4922, 0.4125, 0.3985, 0.6730,
0.2649, 0.4704, 0.3969, 0.5462, 0.6128, 0.4573, 0.5381, 0.4119, 0.4991,
0.5438, 0.3370, 0.5581, 0.5255, 0.4137, 0.4987, 0.5979, 0.5043, 0.3674,
0.6004, 0.5504, 0.5365, 0.3826, 0.4306, 0.3937, 0.5267, 0.6587, 0.4738,
0.5307, 0.4332, 0.4600, 0.5151, 0.3925, 0.3587, 0.3423, 0.5201, 0.4529,
0.4896, 0.5712, 0.5956, 0.5171, 0.4880, 0.4438, 0.6315, 0.5038, 0.5011,
0.5118, 0.5845, 0.4569, 0.5135, 0.6359, 0.4807, 0.5716, 0.5164, 0.4200,
0.3237, 0.4433, 0.6070, 0.5800, 0.6215, 0.4976, 0.4250, 0.5063, 0.6422,
0.5114, 0.5958, 0.5699, 0.5832, 0.4281, 0.4176, 0.4490, 0.4129, 0.5347,
0.5866])
running_var
tensor([0.1170, 0.0552, 0.1209, 0.1130, 0.0925, 0.0819, 0.0968, 0.1087, 0.0262,
0.0297, 0.0328, 0.0522, 0.1047, 0.0707, 0.0713, 0.0651, 0.0528, 0.0545,
0.0546, 0.0703, 0.0448, 0.1295, 0.0633, 0.0918, 0.0917, 0.0963, 0.0891,
0.0287, 0.0784, 0.0363, 0.1142, 0.1252, 0.1155, 0.0732, 0.1299, 0.0803,
0.0495, 0.1242, 0.0754, 0.1059, 0.0840, 0.0896, 0.0642, 0.0593, 0.0876,
0.1371, 0.1110, 0.1040, 0.0339, 0.0738, 0.1149, 0.1198, 0.1107, 0.0914,
0.0784, 0.0942, 0.0482, 0.1069, 0.0771, 0.0470, 0.0809, 0.0950, 0.1216,
0.1473, 0.0880, 0.0943, 0.0451, 0.0964, 0.1160, 0.0544, 0.1133, 0.0884,
0.1439, 0.0576, 0.1036, 0.1378, 0.0962, 0.1441, 0.1185, 0.1162, 0.1056,
0.1019, 0.1086, 0.0990, 0.0285, 0.0959, 0.0521, 0.0896, 0.0557, 0.0582,
0.0470, 0.0891, 0.1031, 0.0864, 0.0999, 0.0762, 0.1290, 0.0753, 0.0914,
0.0715])
after iteration loop
trainB - trainA
tensor([[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.]], grad_fn=<SubBackward0>)
evaluation - trainA
tensor([[-0.0052],
[ 0.0061],
[-0.0114],
[ 0.0485],
[ 0.0164],
[-0.0136],
[-0.0431],
[ 0.0044],
[-0.0463],
[ 0.0443]], grad_fn=<SubBackward0>)
"""
so the evaluation model is still not as good as the training model.
Could you please try to run my program yourself, to see if you can reproduce the issue.
And if so, try to modify it so that it the evaluation model is as good as the training model.
Best Regards,
asc