Hello
I’ve been trying to use a Faster RCNN in training a model on multispectral imagery (4 or more colour channels) for identifying vessels within the imagery. I’m currently utilizing a very slightly modified version of a ResNet50 FPN Model as a backbone (I used this particular bit of code taken from a kaggle notebook as a starting point). However when I’ve been trying to train the model, I’ve been having mixed results even after a high epoch
As an example of what my results look like (blue green red channels represented as red green blue if the colour seems off).
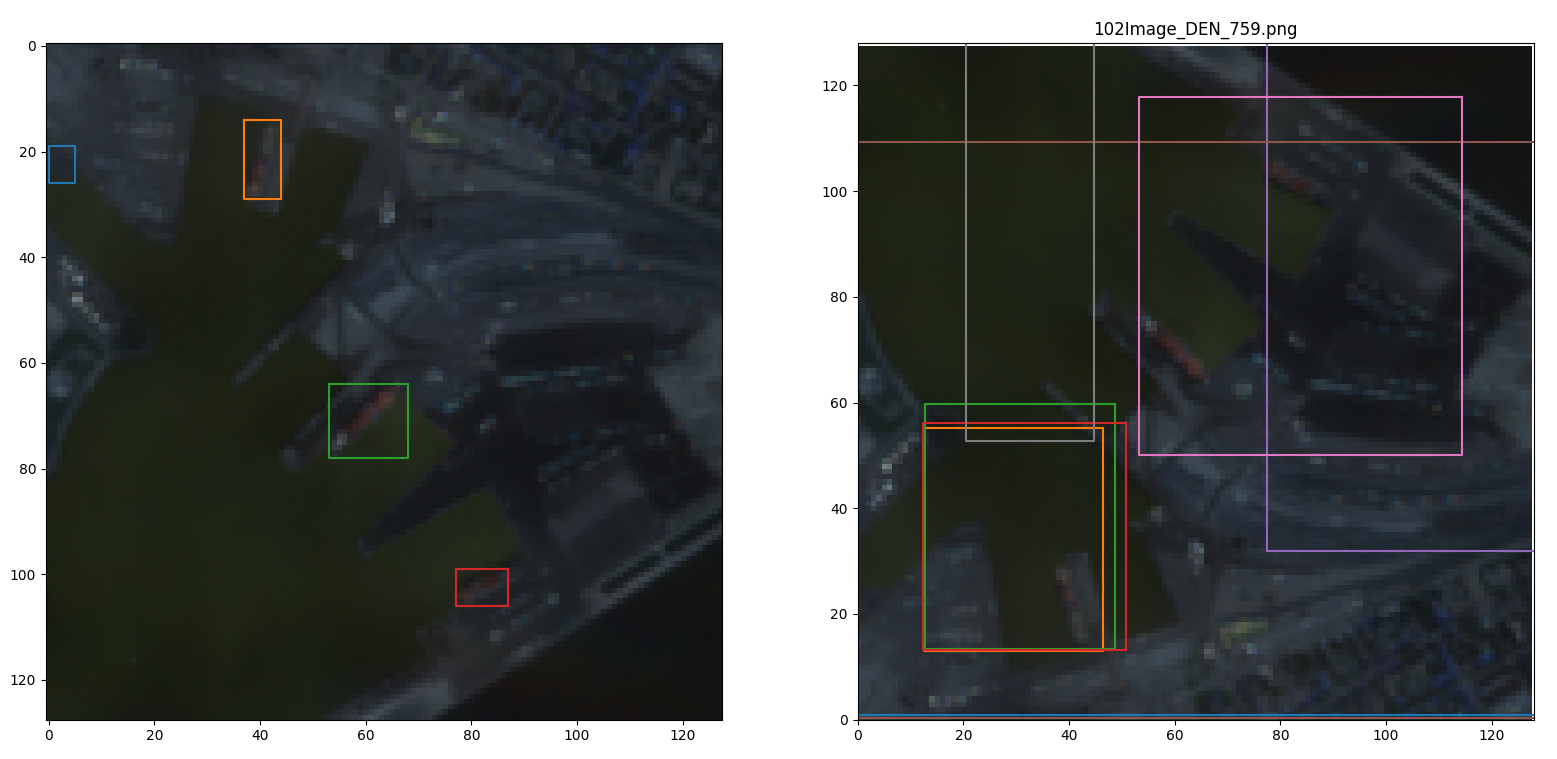
With the numerical results for this particular result being (Trained on RTX 3090)
{'boxes': tensor([[0.0000e+00, 7.0580e-03, 4.5089e+00, 3.4324e+00],
[3.6286e-01, 4.3109e-01, 9.7545e-02, 1.0113e-01],
[3.8097e-01, 4.6612e-01, 9.9756e-02, 1.0369e-01],
[3.9624e-01, 4.3783e-01, 9.7002e-02, 1.0255e-01],
[6.0473e-01, 2.4947e-01, 1.5833e+00, 1.4847e+00],
[0.0000e+00, 2.9449e-03, 6.8887e+00, 8.5387e-01],
[8.9358e-01, 9.2008e-01, 4.1534e-01, 3.9130e-01],
[3.4877e-01, 2.5463e+00, 1.6075e-01, 4.1155e-01]]),
'labels': tensor([1, 1, 1, 1, 1, 1, 1, 1]),
'scores': tensor([0.6883, 0.6401, 0.6320, 0.6276, 0.5587, 0.2847, 0.2674, 0.1132])}
Which, besides not really fiting the image, also seem to be placing boxes beyond the size of the image (which are 128 by 128 pixel images).
My gut is that I’ve done something wrong during the intialization of the FasterRCNN model and the anchors, but I’ve confused myself enough that I’m feeling out of my depth. The code where I create the model looks like:
import torchvision
from torchvision.models.detection import FasterRCNN
from torchvision.models.detection.anchor_utils import AnchorGenerator
import ResModelsFPN
def create_model(bands, num_classes=2):
backbone_v6_fpn = ResModelsFPN.resnet50_fpn_backbone(bands, num_classes)
anchor_sizes = ((2,), (4,), (8,), (16,), (32,))
anchor_generator_v4 = AnchorGenerator(sizes=anchor_sizes, aspect_ratios=((0.125, 0.25, 0.5, 1.0, 2.0),) * len(anchor_sizes))
roi_pooler = torchvision.ops.MultiScaleRoIAlign(featmap_names=['0'], output_size=7, sampling_ratio=2)
image_std = (0.3, 0.3, 0.3)
image_mean = (0.4, 0.4, 0.4)
model = FasterRCNN(backbone_v6_fpn, min_size=128, max_size=128, image_mean=image_mean, image_std=image_std,
num_classes=2, rpn_anchor_generator=anchor_generator_v4, box_roi_pool=roi_pooler)
return model
Does anyone see anything obviously wrong with this before I start digging deeper/posting more sections of the code. I particularly feel that I may have screwed on on the anchor generation, as this is my first time tackling object detection with pytorch’s faster rcnn.
I appreciate any help anyone is able to give me.