I am aware that there are several other topics about slow computation on multi GPU - none of them seems to fit to the behaviour I am facing.
I have a model that utilizes Huggingface BERT and has a total of 111,450,730 params. When I set BERTs requires_grad to False, the model has 2,369,386 params. Apart from the number of parameters, the problematic behaviour is the same: BCE Loss computation is up to three times as expensive when switching to Dataparallel using two instead of one GPU (also changing the batch size does not have any effect).
My model is pretty much standard, however F.binary_cross_entropy(pred, target) takes ~50 ms in single GPU mode and ~150 ms when training on two GPUs.
def update_model_for_trainer(batch):
model.train()
optimizer.zero_grad()
input, target = batch
pred = model(input)
loss = F.binary_cross_entropy(pred, target) # 50 ms without and 150 ms with Dataparallel
loss.backward()
optimizer.step()
return loss.item()
Things tried so far:
Explicitely moving prediction and target to cuda:0
Integrating the loss calculation into the model, after that I used sum(loss).backwards(); had no effect
I would be really thankful for some tips what to do next to investigate the problem.
CUDA operations are asynchronous, so you have to synchronize the code before starting and stopping the timer via torch.cuda.synchronize().
Could you add it to your code and profile the operations again, please?
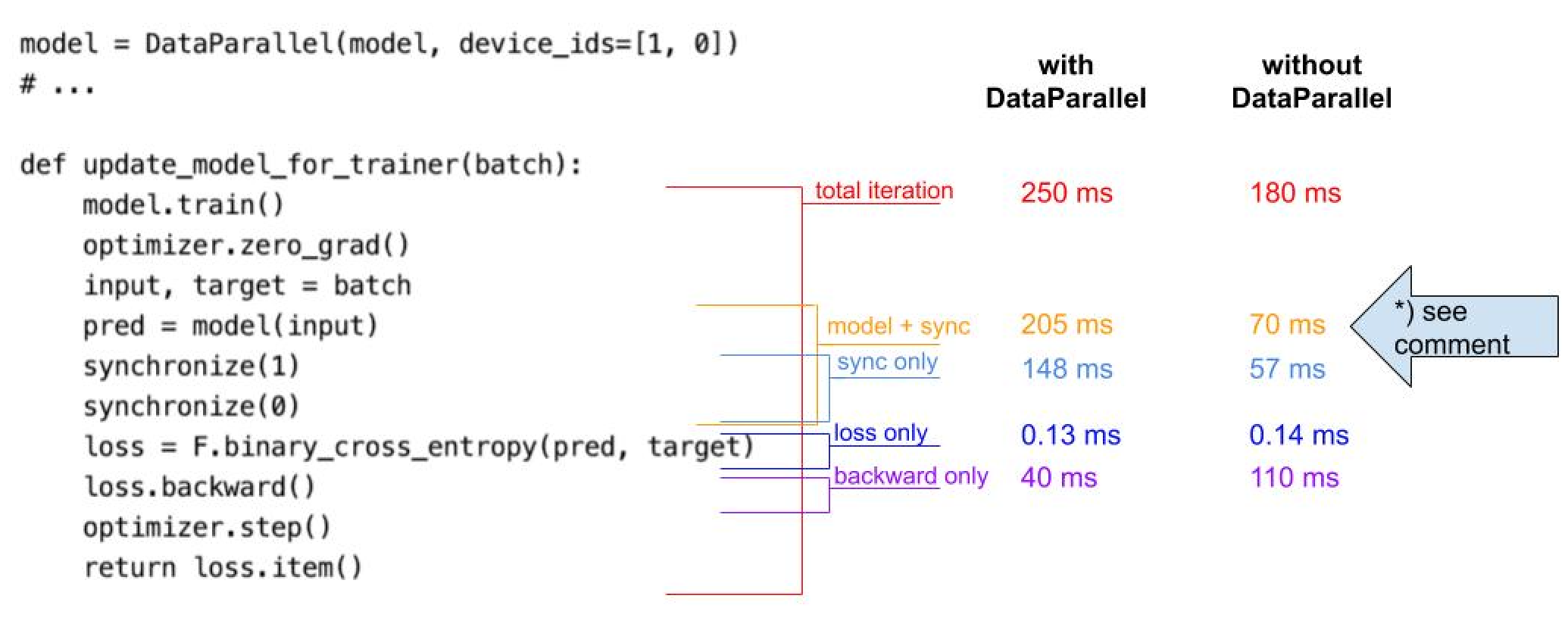
Following your advice, the situation changed. Please look at the following picture, which summarizes the average computation times of the train function:
It turns out that the loss computation indeed can be ignored. Regarding the model + sync:
*) When in DP mode, on both devices model.forward(...) is entered and left at nearly identical ms timestamps. The difference is max 5 ms (which is ok I guess). The average time diff between entering and leaving model.forward(...) is constant at ~20-40 ms depending on using DP or not.
Is the conclusion correct that the problem is, that the cudas are out of sync?
Since the batches contain data of different lengths, could this be the origin of the problem?
Greetings
Thomas
edit: @ptrblck this was supposed to be an answer to you - missed the reply button
Thanks for the update! The profiling looks better now.
That could be a possible reason.
However, we generally recommend to use DistributedDataParallel with a single process per GPU to avoid the scatter and gather of the model in each iteration, which might add some overhead.