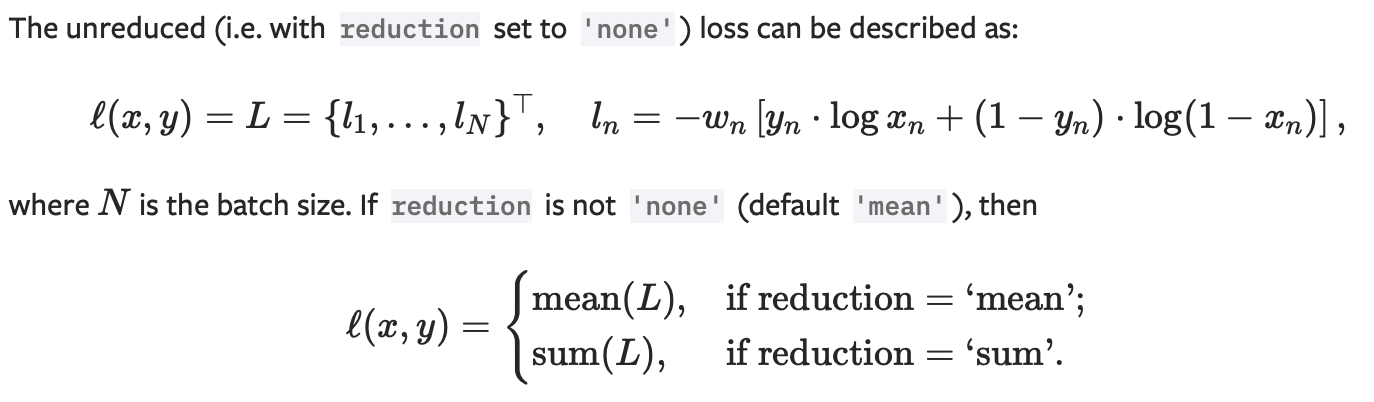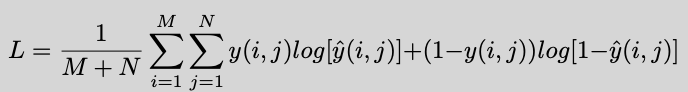Let’s say my target size is [1* 1 * 10 * 10] - B,C,H,W
The output from my network is also [1* 1 * 10 * 10] - B,C,H,W
In this case N = 1. Thus, according to the formula listed above, we should have following:
l(x,y) = L = { l1 } = -[ y1 log( x1 ) + (1 - y1) log(1 - x1)]
Question:
This problem have a target image, and output image instead of a particular scalar for target and output values. In such case how is l1 computed? Will it be computed pixel by pixel (10*10) and mean is taken to get l1?
The definition says mean can be used for batch N. So if I have {l1, l2,…,lN}, it makes sense to compute L using mean formula, but nothing is said above how is l1 computed in the case of images?
quite interesting, I haven’t found anything specific about it either.
I assume, you want to do binary image segmentation. Then, it should be nothing different to having a bunch of single binary classification cases and therefore it should be handled as ‘batch size’. At least that would make sense to me. Please correct me, if I’m wrong.
As an aside, you should use BCEWithLogitsLoss rather than BCELoss
for reasons of numerical stability.
To answer your question, the documentation is a little imperfect on this
point. BCELoss simply computes the loss for each pair of matching
elements of the output and target tensors, and then computes the
mean (if that is what you have chosen for the reduction). It doesn’t
care how the dimensions are divvied up into B, C, H, W.
Thank you Unity05, I think you are correct. The way I understand this now is you compute the loss value for all channel or batches whatever it be (pixel by pixel) and take a mean of it if reduction is “mean”. Example if I have [1 * 1* 10* 10] for output and target. It computes loss pixel by pixel per channels. And at the end take the mean if the reduction is mean.
So, given target of [1 * 1 * 10 * 10] and output from the network as [ 1 * 1 * 10 * 10]. I understood the loss would be given by (assuming the reduction is mean):
Where M and N are the height (value of 10) and width (value of 10) in our case. Am I correct in this regard?