Hi!
I followed the DCGAN tutorial that is shared in the webpage here DCGAN Tutorial — PyTorch Tutorials 2.2.0+cu121 documentation (including reading the papers and other materials).
After checking my implementation again and again im pretty sure there are no errors or problems, however, when it comes to training both the error of the the discriminator is always zero and the network doesnt get trained.
For example printing how the network evolve i get this:
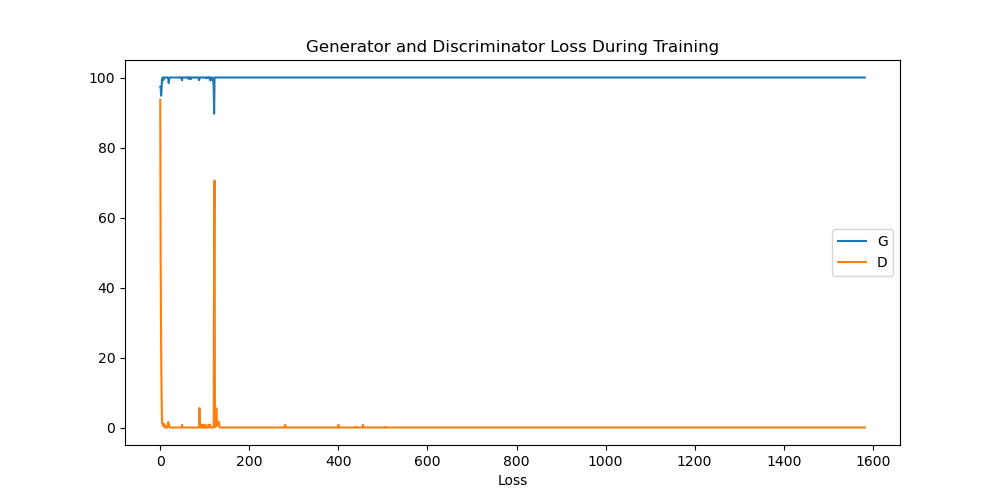
And this is part of the log output in Pycharm:
| [0/0][950/1583] | Loss_D: 0.0000 | Loss_G: 100.0000 | D(x): 1.0000 | D(G(z)): 0.0000 / 0.0000 |
|---|---|---|---|---|
| [0/0][1000/1583] | Loss_D: 0.0000 | Loss_G: 100.0000 | D(x): 1.0000 | D(G(z)): 0.0000 / 0.0000 |
(the forum doesnt let me upload more than one picture).
If you plot the faces is just noise
Im pretty sure is something that my lack of experience is not letting me debug correctly, i would appreciate any help.
Find below the script im using, if you need to test you need (as the tutorial requires) to have the celeba collection in the root folder.
#%matplotlib inline
import argparse
import os
import random
import torch
import torch.nn as nn
import torch.nn.parallel
import torch.optim as optim
import torch.utils.data
import torchvision.datasets as dset
import torchvision.transforms as transforms
import torchvision.utils as vutils
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.animation as animation
from IPython.display import HTML
def weights_init(m):
classname = m.__class__.__name__
if classname.find('Conv') != -1:
nn.init.normal_(m.weight.data, 0.0, 0.02)
elif classname.find('BatchNorm') != -1:
nn.init.normal_(m.weight.data, 1.0, 0.02)
nn.init.constant_(m.bias.data, 0.0)
class Generator(nn.Module):
def __init__(self, ngpu, nz, ngf, nc):
super(Generator, self).__init__()
self.ngpu = ngpu
self.generator = nn.Sequential(
nn.ConvTranspose2d(nz, ngf*8, 4, 1, 0, bias = False),
nn.BatchNorm2d(ngf*8),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 8, ngf * 4, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 4),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 4, ngf * 2, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf * 2),
nn.ReLU(True),
nn.ConvTranspose2d(ngf * 2, ngf, 4, 2, 1, bias=False),
nn.BatchNorm2d(ngf),
nn.ReLU(True),
nn.ConvTranspose2d(ngf, nc, 4, 2, 1, bias=False),
nn.Tanh(),
)
def forward(self, input):
return self.generator(input)
class Discriminator(nn.Module):
def __init__(self, ngpu, nc, ndf):
super(Discriminator, self).__init__()
self.ngpu = ngpu
self.discriminator = nn.Sequential(
nn.Conv2d(nc, ndf, 4, 2, 1, bias = False),
nn.LeakyReLU(0.2, inplace = True),
nn.Conv2d(ndf, ndf*2, 4,2,1, bias = False),
nn.BatchNorm2d(ndf*2),
nn.LeakyReLU(0.2, inplace = True),
nn.Conv2d(ndf*2, ndf*4, 4,2, 1, bias = False),
nn.BatchNorm2d(ndf*4),
nn.LeakyReLU(0.2, inplace = True),
nn.Conv2d(ndf*4, ndf*8, 4, 2, 1, bias = False),
nn.BatchNorm2d(ndf*8),
nn.LeakyReLU(ndf*8),
nn.LeakyReLU(0.2, inplace = True),
nn.Conv2d(ndf*8,1, 4, 1, 0, bias= False),
nn.Sigmoid()
)
def forward(self, input):
return self.discriminator(input)
def main():
data_path = os.getcwd()
#images_path = os.path.join(data_path, 'celeba').replace('\\', '/')
images_path = 'celeba'
#print(images_path)
manual_seed = 42
random.seed(manual_seed)
torch.manual_seed(manual_seed)
torch.use_deterministic_algorithms(True)
workers = 2
batch_size = 128
image_size = 64
nc = 3
nz = 100
ngf = 64
ndf = 64
epochs = 1
lr = 0.0002
beta1 = 0.5
ngpu = 1
data_transforms = transforms.Compose([transforms.Resize(size=image_size), transforms.CenterCrop(image_size),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
dataset = dset.ImageFolder(root=images_path, transform=data_transforms)
data_loader = torch.utils.data.DataLoader(dataset, batch_size=batch_size, shuffle=True, num_workers=workers)
device = torch.device('cuda:0' if (torch.cuda.is_available() and ngpu > 0) else 'cpu')
#-- Test plotting
"""
real_batch = next(iter(data_loader))
plt.figure(figsize=(8, 8))
plt.axis('off')
plt.title('Training Images')
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding=2, normalize=True).cpu(), (1, 2, 0)))
plt.show()
"""
#-- Apply Generator
netG = Generator(ngpu, nz, ngf, nc).to(device)
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
netG.apply(weights_init)
netD = Discriminator(ngpu, nc, ndf).to(device)
if (device.type == 'cuda') and (ngpu > 1):
netG = nn.DataParallel(netG, list(range(ngpu)))
netD.apply(weights_init)
#print(netG)
#print(netD)
criterion = nn.BCELoss()
fixed_noise = torch.randn(64, nz, 1, 1, device = device)
real_label = 1
fake_label = 0
optimizerD = optim.Adam(netD.parameters(), lr = lr, betas = (beta1, 0.999))
optimizerG = optim.Adam(netG.parameters(), lr=lr, betas=(beta1, 0.999))
#print(optimizerD)
#print(optimizerG)
img_list = []
G_losses = []
D_losses = []
iters = 0
print('Starting Training Loop...')
for epoch in range(epochs):
for i, data in enumerate(data_loader, 0):
netD.zero_grad()
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype = torch.float, device = device)
output = netD(real_cpu).view(-1)
errD_real = criterion(output, label)
errD_real.backward()
D_x = output.mean().item()
noise = torch.randn(b_size, nz, 1, 1, device = device)
fake = netG(noise)
label.fill_(fake_label)
output = netD(fake.detach()).view(-1)
errD_fake = criterion(output, label)
errD_fake.backward()
D_G_z1 = output.mean().item()
errD = errD_real + errD_fake
optimizerD.step()
#print('{} {} {} '.format(errD_real, errD_fake, errD))
###############################################
###############################################
netG.zero_grad()
label.fill_(real_label)
output = netD(fake).view(-1)
errG = criterion(output, label)
errG.backward()
D_G_z2 = output.mean().item()
optimizerG.step()
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, epochs - 1, i, len(data_loader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
G_losses.append(errG.item())
D_losses.append(errD.item())
if (iters % 500 == 0) or ((epoch == epochs-1) and (i == len(data_loader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(vutils.make_grid(fake, padding = 2, normalize = True))
iters += 1
plt.figure(figsize=(10,5))
plt.title("Generator and Discriminator Loss During Training")
plt.plot(G_losses, label = 'G')
plt.plot(D_losses, label='D')
plt.xlabel("iterations")
plt.xlabel("Loss")
plt.legend()
plt.show()
"""
real_batch = next(iter(data_loader))
plt.figure(figsize = (15,15))
plt.subplot(1, 2, 1)
plt.axis('off')
plt.title('Real Images')
plt.imshow(np.transpose(vutils.make_grid(real_batch[0].to(device)[:64], padding = 5, normalize= True).cpu(),
(1, 2, 0)))
plt.subplot(1, 2, 2)
plt.axis('off')
plt.title('Fake Images')
plt.imshow(np.transpose(img_list[-1], (1, 2, 0)))
plt.show()
"""
if __name__ == '__main__':
main()