I’m new to PyTorch and machine learning.
I’m trying to perform a regression task to predict 16 output values based on data from 8 sensors, each providing 1400 values.
So my input shape is (8 × 1400), and I intend to use Conv1D for feature extraction.
This structure is able to learn but is really slow. I am aware that most convolutional network use batch norm and/or adaptive pooling but when i change the structure, the network do not learn anymore and seems to predict random result.
1 - any advice, opinion on this architecture ?
2 - any idea why pooling might destroy signal or feature extraction ?
Could you provide a little information about your use case – the meaning and approximate
ranges of your input and output values and what your sensors are? How many training samples
do you have?
How slow is slow?
What optimization scheme are you using? My general advice is to start with plain-vanilla SGD with a fairly small learning rate, just to make sure you can train stably. Increase the
learning rate rather aggressively, but not so much that training becomes unstable. Then try
turning on momentum. Values like 0.9 or 0.95 often make sense. Sometimes to keep
training stable, it helps to back off a little on the learning rate a little when you increase the
momentum.
If you can get things to train stably with SGD – even if not as fast as you would like – you
could try other optimizers, especially Adam (but be aware that there is some lore that the
faster training seen with Adam might be illusory).
I would suggest looking to see what architectures others have used to good effect for use
cases similar to yours. (Having said that, your architecture doesn’t look outlandish.)
You might consider making your network, in part, a residual network by adding some “short-cut”
connections. This has been shown to speed training (in deeper, more complicates networks).
As you noted, it is quite common to use pooling layers in a convolutional network such as
yours. Without knowing your use case, it’s hard to tell, but I would think pooling could help
and, at least, would be unlikely to break things fully.
Assuming that your kernel size is not atypically large (let’s say it’s 3), then most points in your
length-1400 input vectors don’t communicate at all with one another until your first Linear
layer. It’s very common in convolutional architectures to use successive pooling layers to
shrink the convolutional dimension(s) down to something on the order of one while encoding
that information into an increasing number of “features” (the channels dimension). This lets
distant parts of the convolution dimension(s) start communicating with one another – so that
the network can learn about the whole input, rather than just nearby “pixels” – way before the
final Linear layers.
I don’t know why pooling hasn’t worked for you. I would recommend that you try max-pooling
or average-pooling. (It’s not clear to me why you chose adaptive-pooling in particular.)
A couple of minor comments:
Try getting rid of your final ReLU. As a general rule, you don’t want a non-linear “activation”
after your final Linear layer.
It looks like your convolutions are trimming just one element off of your input vector. This
suggests to me that you are padding only on one side. With a kernel size of three and no
padding, your vector length would shrink by two with each convolution and with (two-sided)
padding, it wouldn’t shrink at all. This will hardly matter – it just looked a little odd to me.
Like @KFrank pointed out, your convnet section of the model is barely distilling anything. Try this to resolve:
First apply a higher kernel size, like 3 to 7. The initial input can have a bigger kernel size, like 7, while latter conv layers should just be 3.
Integrate maxpool1d between each conv1d layer. Kernel size of 2 to 4. That will cut the size on the 3rd dim in half to a fourth each pass.
Ideally, you want your convnet to reach 1 on the 3rd dim. That means maximal feature extraction and conversion into embeddings. From there, your fully connected section of the model(i.e. linear layers) can get maximum traction on the data.
So just to recap, the goal of the convnet is to extract all features that are temporally/spacially related. Then your fully connected section is to interpret those features into meaningful predictions.
My sensors do not return time intervals; instead, they provide signals across 1,400 frequency bins. When i train my model sensors are in the channel dim of CONV1D (Nbatch,C,L).
Each sensor is calibrated in the same way, so if channel 800 shows a high signal, it’s very likely that the other seven sensors also contain important information for that channel (like an echo).
It’s also important for my model to capture correlations between channels within the same sensor.
The input data ranges from 0 to 1e4, while the output data can range up from 0 to 1e8.
At the moment i have 10000 samples. it takes 20 hours for training (30 epocs with LR of 0.003 and Adam for optimization)
i use a kernel_size=2, stride=1, since larger kernel seems to prevent my model from learning
When training my model, I do not scale or normalize the data because it feels counterintuitive to normalize for a regression task (it feels like my data will be biaised). Is normalization or scaling considered standard practice even for regression models ?
“ It’s very common in convolutional architectures to use successive pooling layers to
shrink the convolutional dimension(s) down to something on the order of one while encoding
that information into an increasing number of “features” (the channels dimension).” If i look a Unet for 2D image segmentation tasks, i see that channels represent colors which is not as “meaning full” as shape for segmentation tasks. In my case sensors are “stored” in the channel dimension, can this trouble my model learning phase when conv1D computes the cross-correlation ?
The one question you need to ask yourself to determine whether convolutions are beneficial for your data is “Does order matter?”
If order doesn’t matter, Linear works just fine. Think tangential data points: age, gender, hair color, height. There’s nothing meaningful in the order of those.
If order does matter, then convolutions will extract more information. Think sequential data like pixels in a photo, time series, DNA sequencing, music, etc. Scrambling the order would lose important information.
Sounds like the frequency pool dim (1,400) is definitely sequential. But I’m wondering if the sensors(8) are, too. Does the order of the sensor data matter? I.e. are the physically placed near each other that there is some correlation between their locations? If so, you might be better off using conv2d layers in your convnet part of the model.
As a side comment – and just a long shot – you might consider taking the Fourier transform
of your frequency bins and appending those as eight more channels along the channels
dimension.
If your data has temporal structure that is useful for your predictions, doing so could help
make such structure more explicit. Even though the information in the time-domain channels
will be duplicative of your original frequency bins, it’s difficult for a network to “learn” to
perform a Fourier transform, so performing the Fourier transform explicitly could make
the time-domain information more accessible to your network.
I’m confused by your terminology. I thought your 1400 frequency bins comprised your “length”
(L) dimension and your eight sensors formed your “channels” (C) dimension.
So when you say “capture correlations between channels within the same sensor,” I imagine
that you are talking about the correlation between two frequency bins from the same sensor.
Is this correct?
Also, you still haven’t told us what your sensors are. What do they measure? As J asked,
are your sensors ordered in any sense sequentially? To phase it a little differently, does
sensor 1 have a closer relationship to sensor 2 than it does to sensors 4 and 5?
You also haven’t told us what your target / output values mean. What are you trying to
predict? What loss criterion are you using?
It would make sense to normalize your input and target data. (See below.)
It would probably make sense to try training for considerably longer even at the cost of much
greater run time. Depending on how “hard” your problem is, 30 epochs, even with 10,000
training samples, could well not be enough.
This just doesn’t make sense to me.
First, as J emphasized, with such a small kernel (and no pooling / downsampling), your
frequency bins never get to talk to one another until the final Linear layers. And using
a larger kernel (and / or downsampling) shouldn’t break learning. So something fishy is
going on here – maybe just not enough training to see any actual learning.
Yes, normalization is very much standard practice. When you start with a randomly-initialized
model (with default or otherwise typical initialization), the weights are initialized with values
that are, morally speaking, of order one, and will therefore be appropriate for inputs of order
one. Similarly, your output predictions – even though essentially random because your model
hasn’t been trained yet – will also be of order one.
So normalize both your input and target data. A good choice will be to normalize them to
have mean zero and standard deviation one.
When you train a model (such as U-Net), the convolution kernels “learn” what the channels
mean. (And I would say that the RGB colors of individual pixels can be highly relevant to
segmentation.)
Again, the kernels should learn what your channels mean and how they are related to one
another. (Just to be clear, I am interpreting your use of “channel dimension” in the sense of
the in_channels constructor argument of Conv1d.)
My recommendations – to be done one after the other rather than all at once:
Normalize your data and get rid of the final ReLU. Highly unnormalized input and target
data can really slow learning down.
Significantly increase your kernel size. J’s suggestion of 7 could be a good starting point.
Add pooling layers.
As J said, you really do want your frequency-bin (length) dimension to get down to order
one by the end of your convolutional layers (with the information getting “distilled” into the
channels (“features”) dimension).
Train longer – potentially much longer.
Are you tracking your loss criterion and accuracy (or other figure of merit) for both your
training and validation datasets? Do they more or less track one another?
Try overfitting on a small subset of your training data. You should be able to train down to
a small loss value on a small subset. You’ll be overfitting, of course, and you won’t do well
on your validation dataset, but if you can’t overfit, you won’t be able to train effectively on
your full training datatset.
I.e. are the physically placed near each other that there is some correlation between their locations? If so, you might be better off using conv2d layers in your convnet part of the model.
@J Yes, totally order matters. In fact, sensors are spatially related, they are located in a precise way to try to identify where the signal comes from. Output regression try to locate and evaluate several base signals.
I will try to replace my 1D by 2D see if there is any improvements.
I’m confused by your terminology. I thought your 1400 frequency bins comprised your “length” (L) dimension and your eight sensors formed your “channels” (C) dimension.
You are absolutely right, i used the wrong term, my bad. My conv1D is fed by (batch, 8, 1400).
I’m using a MSE criterion for the loss.
Try overfitting on a small subset of your training data. You should be able to train down to
a small loss value on a small subset. You’ll be overfitting, of course, and you won’t do well
on your validation dataset, but if you can’t overfit, you won’t be able to train effectively on
your full training datatset.
Well i have a lot to experiment !
First thing to dig in is normalization.
When i normalize my 8*1400 train dataset with normalize, my model learn from the normalized data.
When i want to perform the test part, how can i normalize it the same way without introducing any scale biases ? Is there an easy way to apply the “train dataset normalization” on the test dataset ?
Take (a representative sub-sample of) your training data and compute its mean and
standard deviation. (It would make sense to do this on a per-sensor, per-frequency-bin
basis if the statistics differ significantly across sensors and / or frequency bins.) Then
normalize each input datum as x' = (x - mean) / stdev. Your x' values will now
have a mean of zero and a standard deviation of one. Do the same for your target values.
(It won’t matter much in practice, but a purist will insist that you not use validation or
test data to compute the normalization statistics.)
Train your model using the normalized input and target data.
For inference (validation, test, real-world application), normalize your input data using the
training-data normalization statistics. For evaluation, I would also normalize the target
values using the mean and standard deviation you computed from your training-data target
values (but you could also unnormalize your predicted values and then compare them with
the unnormalized target values).
For real-world inference (where you have no a priori target values), whether you should
unnormalize your predictions is really a matter of convenience. If your users think in terms
of the units of the raw, unnormalized target values – or if these units have some clear
physical meaning – then you might prefer to unnormalize the predictions. But if the
normalized predictions – that is, the predictions that come out of model that was trained
on the normalized target values – have a more convenient scale or lend themselves
to a more intuitive understanding, then simply provide your users with the normalized
predictions.
You might (or might not) want to use batch normalization. But this is a distinctly different
computation for a distinctly different purpose than normalizing your input and target data.
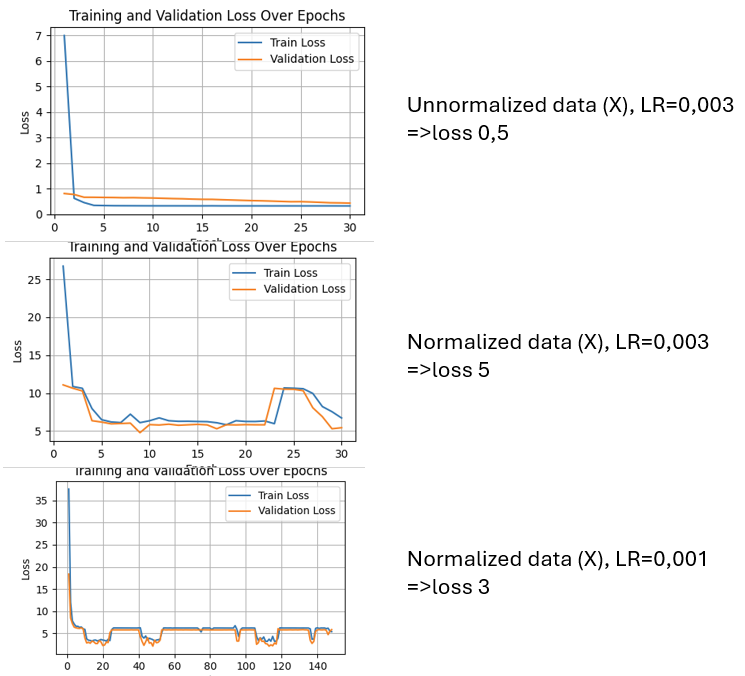
i am really concern about the shape of the last curve, i have a hard time understanding why the network seems to learn until epoc 20 and then, starts to “plateau” for 15 epoc, then learn again and go back to the same plateau. Is it finding a “wrong” local minima ?
It seems that my normalization is not a good optimization for my use case, maybe i can try another one like minmax scaler.
If it doesnt work, i will spend more time trying to model it with a conv2D model like J_Johnson suggested.