Hi,
I am new to pytorch and machine learning.
I have created a model and I want to print the classification report.
I am somewhat certain that the first argument of the classification report is incorrect.
I was wondering it i could get some guidance on what should be added instead.
I have used this link: PyTorch [Tabular] —Multiclass Classification | by Akshaj Verma | Towards Data Science
The dataset files are saved on my google drive and accessed from there.
from __future__ import print_function
from __future__ import division
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import torchvision
from torchvision import datasets, models, transforms
import matplotlib.pyplot as plt
import time
import os
import copy
print("PyTorch Version: ",torch.__version__)
print("Torchvision Version: ",torchvision.__version__)
#from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.ticker as plticker
import os
import pprint
import itertools
from collections import defaultdict
#from collections import OrderedDict
# generate random integer values
from random import seed
from random import randint
import numpy as np
#from pylab import array
from random import sample
from random import shuffle
import math
import torch
from torch.utils.data import Dataset, DataLoader, IterableDataset
from torchvision import transforms, utils, models
from torch import nn, optim
from torchvision import datasets, transforms
#from torchvision.utils import make_grid
from PIL import Image
from google.colab import drive
drive.mount('/content/drive/')
#import csv
from time import time
import sys
sys.path.append('/content/drive/MyDrive')
#!cp -r "/content/gdrive/MyDrive/ColabNotebooks/Square_Data_Set_Generation.ipynb" '/content/'
import square_data_set_generation1
#import triangles_pieces_dataset
from torch.utils.tensorboard import SummaryWriter
from sklearn.metrics import accuracy_score
from sklearn.metrics import confusion_matrix
from sklearn.metrics import f1_score
from sklearn.metrics import classification_report
os.environ['MY_ROOT_DIR'] = '/content/drive/MyDrive/DATASET/train'
os.environ['MY_VAL_DIR'] = '/content/drive/MyDrive/DATASET/val'
os.environ['MY_TEST_DIR']='/content/drive/MyDrive/DATASET/test'
#https://pytorch.org/tutorials/beginner/finetuning_torchvision_models_tutorial.html
def retireve_the_dataset_input():
puzzle_piece_dim = int(input("Enter puzzle_piece_dim "))
size_of_buffer = int(input("Enter size_of_shuffle_buffer "))
model_dim = int(input("Enter model_dim "))
batch_size = int(input("Enter batch_size "))
return sq_puzzle_piece_dim, size_of_buffer, model_dim, batch_size
def set_the_dataset_input(default=True):
if default:
puzzle_piece_dim=100
size_of_buffer = 1000
model_dim = 224
batch_size = 20
else:
puzzle_piece_dim, size_of_buffer, model_dim, batch_size = retireve_the_dataset_input()
return puzzle_piece_dim, size_of_buffer, model_dim, batch_size
def initialse_dataloader(root_dir,val_dir,test_dir,puzzle_piece_dim,size_of_buffer, model_dim,batch_size):
##ADD YOUR OWN DATASETS
training_dataset=square_data_set_generation1.AdjacencyDataset(root_dir,puzzle_piece_dim, size_of_buffer, model_dim)
#triangles_pieces_dataset.triangle_pieces_generator(root_dir,puzzle_piece_dim,size_of_buffer, model_dim)
print(root_dir)
print(puzzle_piece_dim)
#square_data_set_generation.AdjacencyDataset(root_dir,puzzle_piece_dim, size_of_buffer, model_dim)
##Load the data using data loader
train_dataset_dataloader = DataLoader(training_dataset, batch_size)
##Validation Data set
validation_dataset=square_data_set_generation1.AdjacencyDataset(val_dir,puzzle_piece_dim, size_of_buffer, model_dim)
#square_data_set_generation.AdjacencyDataset(val_dir,puzzle_piece_dim, size_of_buffer, model_dim)
validation_dataset_dataloader = DataLoader(validation_dataset, batch_size)
##Add in testing dataset
testing_dataset=square_data_set_generation1.AdjacencyDataset(test_dir,puzzle_piece_dim, size_of_buffer, model_dim)
test_dataset_dataloader = DataLoader(testing_dataset, batch_size)
allTheDataloaders={'Training':train_dataset_dataloader , 'Validation': validation_dataset_dataloader,'Testing':test_dataset_dataloader}
return allTheDataloaders
#https://pytorch.org/tutorials/beginner/saving_loading_models.html
#https://pytorch.org/tutorials/recipes/recipes/saving_and_loading_a_general_checkpoint.html
#https://towardsdatascience.com/how-to-save-and-load-a-model-in-pytorch-with-a-complete-example-c2920e617dee
def save_the_models_at_the_best_checkpoint(check_point_save,is_best,checkpoint_path,best_model_path):
new_path=checkpoint_path
torch.save(check_point_save,new_path)
if is_best:
torch.save(check_point_save, best_model_path)
else:
torch.save(check_point_save, checkpoint_path)
def load_the_models_at_the_best_checkpoint(new_path, model, optimizer):
# load check point
checkpoint = torch.load(new_path)
# initialize state_dict from checkpoint to model
model.load_state_dict(checkpoint['state_dict'])
# initialize optimizer from checkpoint to optimizer
optimizer.load_state_dict(checkpoint['optimizer'])
# initialize valid_loss_min from checkpoint to valid_loss_min
valid_loss_min = checkpoint['valid_loss_min']
# return model, optimizer, epoch value, min validation loss
return model, optimizer, checkpoint['epoch'], valid_loss_min.item()
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
##Initialise the model
def initialise_the_model(model,numOfClasses,feature_extract,use_pretrained=True):
if model=='densenet':
model = models.densenet121(pretrained=use_pretrained)
set_parameter_requires_grad(model_ft, feature_extract)
num_ftrs = model_ft.classifier.in_features
model.classifier = nn.Linear(num_ftrs, numOfClasses)
input_size = 224
return model
def create_optimizer(given_model_parameters, learning_rate, momentum):
optimizer = optim.SGD(given_model_parameters, lr = learning_rate, momentum = momentum)
return optimizer
model_names = ["Densenet"]
def get_model_details():
i = int(input("Press 0 for Densenet "))
model_name = model_names[i]
if i==1:
j = int(input("Press 0 for FineTuning and 1 for FeatureExtracting "))
feature_extracting=(j==1)
else:
feature_extracting=False
print("************")
print(f"Using {model_name}")
print(f"feature_extracting : {feature_extracting}")
return model_name, feature_extracting
def set_parameter_requires_grad(model, feature_extracting):
if feature_extracting:
for param in model.parameters():
param.requires_grad = False
def reshape_denseNet(no_of_classes, feature_extract, use_pretrained=True):
model_dense = None
input_size = 0
model_dense = models.densenet161(pretrained=True)
set_parameter_requires_grad(model_dense, feature_extract)
no_of_features = model_dense.classifier.in_features #CHANGE
model_dense.classifier = nn.Linear(no_of_features, no_of_classes)
#nn.Linear(1024, num_classes) = nn.Linear(no_of_features, no_of_classes) #CHANGE TO CLASSIFER
return model_dense
def parameters_to_update(model_name, model, feature_extract=False):
params = list(model.parameters())
if model_name=="Densenet":#check with the model name created
if feature_extract:
print("Feature extracting from Densenet - Expect less number of parameters to learn!")
params = []
for name,param in model.named_parameters():
if param.requires_grad == True:
params.append(param)
print("\t",name)
else:
print("Fine tuning Densenet - Expect more number of parameters to learn!")
for name,param in model.named_parameters():
if param.requires_grad == True:
print("\t",name)
print(f"No_of_parameters to learn : {len(params)}")
return params
def make_loss_criterion(model_name):
# if model_name=="Densenet":
loss_criterions = nn.CrossEntropyLoss()
return loss_criterions
##CREATE A PARAMATERS UPTO DATE FUNCTION
def make_model_lc_optimizer(model,learning_rate, momentum,
feature_extract=False,no_of_classes=2):
model =reshape_denseNet(no_of_classes, feature_extract, use_pretrained=True)
params_to_update = parameters_to_update(model, model, feature_extract)
loss_criterion = make_loss_criterion(model)
optimizer = create_optimizer(params_to_update, learning_rate, momentum)
return model, loss_criterion, optimizer
def get_hyperparameters(default=True):
if default:
learning_rate=0.001
momentum = 0.9
else:
learning_rate = float(input("Enter learning rate "))
momentum = float(input("Enter momentum "))
return learning_rate, momentum
def train_it(no_of_epochs, starting_epoch,
model_name,model,loss_criterion, optimizer,
batch_size, allTheDataloaders,board_writer,device,batches_per_epoch=100,
is_best=False,min_validation_loss=math.inf):
last_checkpoint_path = f"./last_checkpoint_for_{model_name}.pt"
best_model_path=f"./best_model_for_{model_name}.pt"
for epoch in range(starting_epoch,starting_epoch+no_of_epochs):
print(f"Epoch : {epoch}")
start_time = time()
model.train()
print("Training")
train_loss_in_this_epoch = 0
no_of_batches_in_this_epoch = 0
train_correct_in_this_epoch = 0
for train_batch_data, train_batch_labels in allTheDataloaders["Training"]:
train_batch_data, train_batch_labels = train_batch_data.to(device), train_batch_labels.to(device)
no_of_batches_in_this_epoch+= 1
optimizer.zero_grad()
train_batch_outputs = model(train_batch_data)
#Compute loss for this batch
train_batch_loss = loss_criterion(train_batch_outputs, train_batch_labels)
train_loss_in_this_batch = train_batch_loss.item()
train_loss_in_this_epoch += train_loss_in_this_batch
train_batch_loss.backward()
optimizer.step()
with torch.no_grad():
new_pred=torch.max(train_batch_outputs, axis = 1)
train_score, train_predictions = torch.max(train_batch_outputs, axis = 1)
train_correct_in_this_batch = torch.sum(train_predictions == train_batch_labels.data).item()
train_correct_in_this_epoch += train_correct_in_this_batch
train_batch_labels = train_batch_labels.detach().cpu().numpy()
train_score = train_score.detach().cpu().numpy()
if (no_of_batches_in_this_epoch % (batches_per_epoch//10)) == 0:
print(f"Training #{no_of_batches_in_this_epoch} Batch Acc : {train_correct_in_this_batch}/{batch_size}, Batch Loss: {train_loss_in_this_batch}")
if no_of_batches_in_this_epoch == batches_per_epoch:
print(f"Epoch : {epoch}, Training Batch: {no_of_batches_in_this_epoch}")
break
board_writer.add_scalar(f'Training/Loss/Average', train_loss_in_this_epoch/no_of_batches_in_this_epoch, epoch)
board_writer.add_scalar(f'Training/Accuracy/Average', train_correct_in_this_epoch/(no_of_batches_in_this_epoch*batch_size), epoch)
board_writer.add_scalar(f'Training/TimeTakenInMinutes', (time()-start_time)/60, epoch)
board_writer.flush()
print(f"Training average accuracy : {train_correct_in_this_epoch/(no_of_batches_in_this_epoch*batch_size)}")
print(f"Training average loss : {train_loss_in_this_epoch/no_of_batches_in_this_epoch}")
#create f measure
model.eval()
print("Validation")
val_loss_in_this_epoch = 0
no_of_batches_in_this_epoch = 0
val_correct_in_this_epoch = 0
with torch.no_grad():
for val_batch_data, val_batch_labels in allTheDataloaders["Validation"]:
val_batch_data, val_batch_labels = val_batch_data.to(device), val_batch_labels.to(device)
no_of_batches_in_this_epoch+= 1
val_batch_outputs = model(val_batch_data)
#Compute loss for this batch
val_batch_loss = loss_criterion(val_batch_outputs, val_batch_labels)
val_loss_in_this_batch = val_batch_loss.item()
val_loss_in_this_epoch += val_loss_in_this_batch
val_score, val_predictions = torch.max(val_batch_outputs, axis = 1)
val_correct_in_this_batch = torch.sum(val_predictions == val_batch_labels.data).item()
val_correct_in_this_epoch += val_correct_in_this_batch
if (no_of_batches_in_this_epoch % (batches_per_epoch//10)) == 0:
print(f"Validation #{no_of_batches_in_this_epoch} Batch Acc : {val_correct_in_this_batch}/{batch_size}, Batch Loss: {val_loss_in_this_batch}")
if no_of_batches_in_this_epoch == batches_per_epoch:
print(f"Epoch : {epoch}, Validation Batch: {no_of_batches_in_this_epoch}")
break
board_writer.add_scalar(f'Validation/Loss/Average', val_loss_in_this_epoch/no_of_batches_in_this_epoch, epoch)
board_writer.add_scalar(f'Validation/Accuracy/Average', val_correct_in_this_epoch/(no_of_batches_in_this_epoch*batch_size), epoch)
board_writer.add_scalar(f'Validation/TimeTakenInMinutes', (time()-start_time)/60, epoch)
board_writer.flush()
print(f"Validation average accuracy : {val_correct_in_this_epoch/(no_of_batches_in_this_epoch*batch_size)}")
print(f"Validation average loss : {val_loss_in_this_epoch/no_of_batches_in_this_epoch}")
if min_validation_loss >= val_loss_in_this_epoch:
is_best = True
min_validation_loss = min(min_validation_loss,val_loss_in_this_epoch)
checkpoint = {
'epoch': epoch + 1,
'min_validation_loss': min_validation_loss,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
}
save_the_models_at_the_best_checkpoint(checkpoint, is_best, last_checkpoint_path, best_model_path)
print(f"In epoch number {epoch}, average validation loss decreased to {val_loss_in_this_epoch/no_of_batches_in_this_epoch}")
load_the_models_at_the_best_checkpoint = {
'epoch': epoch + 1,
'min_validation_loss': min_validation_loss,
'state_dict': model.state_dict(),
'optimizer': optimizer.state_dict(),
}
save_the_models_at_the_best_checkpoint(load_the_models_at_the_best_checkpoint, False, last_checkpoint_path, best_model_path)
board_writer.close()
#from sklearn.metrics import classification_report, confusion_matrix, accuracy_score
# print(confusion_matrix(t_labels,t_predicitions))
#print(classification_report(t_labels,scores))
# print(metrics.classification_report (t_labels, t_predicitions))
# print(accuracy_score(t_labels, t_predicitions))
t_labels=[]
t_predicitions=[]
with torch.no_grad():
model.eval()
for test_batch_data,test_batch_labels in allTheDataloaders["Testing"]:
test_batch_data, test_batch_labels = test_batch_data.to(device), test_batch_labels.to(device)
y_test_pred=model(test_batch_data)
_, y_pred_targets = torch.max(y_test_pred, dim = 1)
t_predicitions.append(y_pred_targets.cpu().numpy())
t_predicitions=[t.squeeze().tolist() for t in t_predicitions]
print(classification_report(test_batch_data, t_predicitions))
##Add in classification report to this section and check if it works https://stackabuse.com/introduction-to-pytorch-for-classification/
##Variables
root_dir = os.getenv("MY_ROOT_DIR")
val_dir = os.getenv("MY_VAL_DIR")
test_dir=os.getenv("MY_TEST_DIR")
#Change this to False if you want to set the variables instead of using default
default_setting_for_dataset = True
puzzle_piece_dim,size_of_buffer,model_dim,batch_size = set_the_dataset_input(default_setting_for_dataset)
print(f"my_puzzle_piece_dim = {puzzle_piece_dim}")
print(f"my_size_of_buffer = {size_of_buffer}")
print(f"my_model_dim = {model_dim}")
print(f"my_batch_size = {batch_size}")
my_dataloaders = initialse_dataloader(root_dir,val_dir,test_dir, puzzle_piece_dim,size_of_buffer, model_dim,batch_size)
model_name, feature_extract = get_model_details()
default_setting_for_hyperparameters = True
learning_rate,momentum = get_hyperparameters(default_setting_for_hyperparameters)
#Change the number
epoch=3
model,loss_criterion,optimizer=make_model_lc_optimizer(model_name,learning_rate, momentum,feature_extract)
if torch.cuda.is_available():
device = torch.device("cuda:0")
print("Running on the GPU")
#putting model on gpu
model.to(device)
else:
device = torch.device("cpu")
print("Running on the CPU")
tensorboard_dir=f"Training_{model_name}"
board_writer = SummaryWriter(tensorboard_dir)
train_it(epoch, 0,
model_name,model,loss_criterion, optimizer,
batch_size,
my_dataloaders,
board_writer,
device,
batches_per_epoch=500)
/%load_ext tensorboard
%tensorboard --logdir="$tensorboard_dir"
I have placed test_batch_data but I know it should not be there as I got the following error.
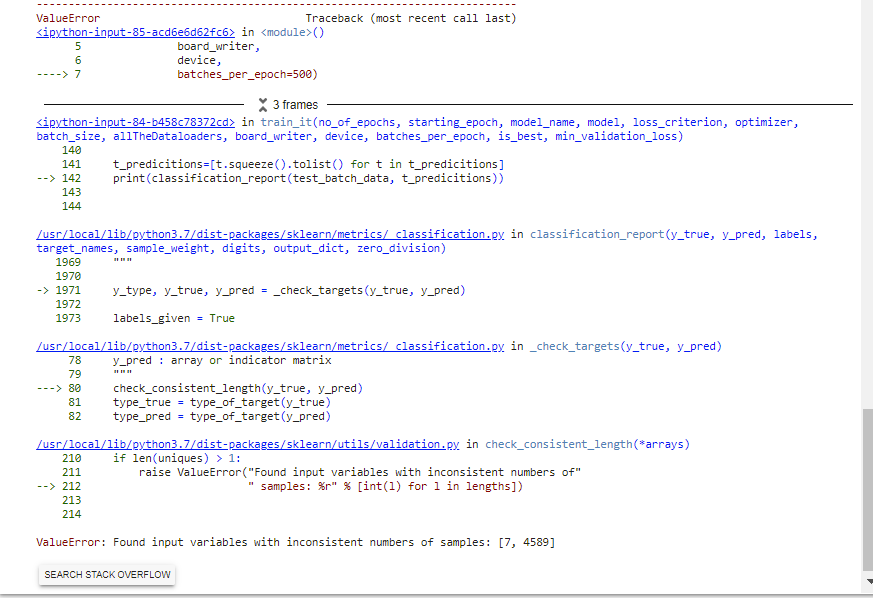
Any guidance would be appreciated as I am a bit lost.