I am using the excellent HuggingFace implementation of BERT in order to do some multi label classification on some text. I basically adapted his code to a Jupyter Notebook and change a little bit the BERT Sequence Classifier model in order to handle multilabel classification. However, my loss tends to diverge and my outputs are either all ones or all zeros.
There is no input in my dataset such as all labels are zeros and the labels distribution in my train dataset is :
I am using the Adam Optimizer on the BCEWithLogitsLoss and I am unable to figure out where the problem comes from? Should I add some weights in my loss function? Do I use it in a right way? Is my model wrong somewhere. I attach to this post a Notebook of my test. Maybe someone encountere the same problem before and could help me?
I artificially changed the dataset so that all my samples correspond to label 1 i.e. for every sample, the target is [1, 0, 0, 0, …, 0]. I wanted to see whether the network was able to learn this dummy case. However, it predicts the opposite for each sample i.e. the predicted output is [0, 1, 1, 1, …, 1]. Have you observed this before?
Your code looks alright, at least the parts I’ve tried to debug.
It’s probably not an issue, but I’m also cautious if you are reshaping a tensor which should already be in the right shape as is done in your loss_fct:
I had a look at it because I was also worried that the reshape would mess the data up but it doesn’t seem to be the case. I removed the .view(-1, self.num_labels) because it was indeed useless (thanks!) but it doesn’t change the problem.
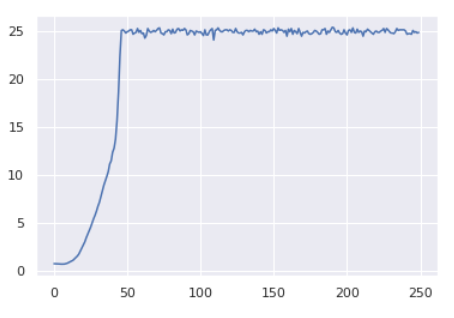
I also tried the toy example where all the target labels are [0, 0, …, 0] and the model fails as well. It predicts [1, 1, …, 1] for every sample. When I look at the evolution of the loss, I saw that it decreased during the first few steps within the first epoch and then it goes up.