Good morning!
I am working on a customized BERT-based model (pytorch framework) for multiclass classification, on GoEmotions dataset (over 200K+ dataset samples, sentiment labels are one hot encoded).
I’ve followed several tutorials, guides, viewed many notebooks, yet something bothers me: my model unexplainably achieves very low performance metrics despite it may seem to me that everything is set up fine.
My main concern: I’m afraid I’m doing something wrong with the backpropagation of the gradient.
I’m pasting here my code and results.
- Texts are lower cased, using bert-base-uncased.
labels = pd.DataFrame(ds.sentiment.values.tolist()).values
sentences = ds.text.map(lambda x: x.lower()).values
# labels[:4]
array([[1, 0, 0],
[0, 1, 0],
[0, 0, 1],
[0, 1, 0]])
-
Labels distribution for sentiment labels:
[1, 0 , 0] → negative
[0, 1, 0] → neutral
[0, 0, 1] → positive
I find it quite acceptable as I’ve seen worse unbalanced datasets achieving an accuracy of 88% or more.
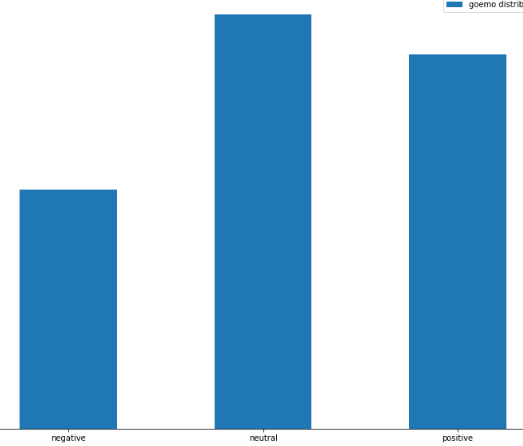
-
Metrics achieved
train accuracy val accuracy train recall val recall train precision val precision train f1 val f1
class 0 0.66667 0.56250 0.66667 0.56250 0.66667 0.56250 0.66667 0.56250
class 1 0.33333 0.12500 0.33333 0.12500 0.33333 0.12500 0.33333 0.12500
class 2 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000 0.00000
Train accuracy: 0.33333 Evaluation accuracy: 0.22917 Train loss: 1.10356 Eval loss: 1.10048
And here are the relevant parts of my code.
# training-test split
X_train, X_val, y_train, y_val = train_test_split(sentences, labels, test_size=0.25)
X_val, X_test, y_val, y_test = train_test_split(X_val, y_val, test_size=0.5)
class CustomDataLoader(Dataset):
def __init__(self, sentences, labels, tokenizer: BertTokenizer, max_length: int = 512):
sentences = sentences if type(sentences) is list else list(sentences)
targets = labels if type(labels) is list else list(labels)
self.tokenizer = tokenizer
self.sentences = sentences
self.targets = labels
self.max_length = max_length
def __len__(self):
return len(self.sentences)
def __getitem__(self, index):
s = str(self.sentences[index])
inputs = self.tokenizer.encode_plus(
s,
add_special_tokens=True,
max_length=self.max_length,
padding="max_length",
truncation=True,
return_attention_mask=True,
return_tensors="pt",
return_token_type_ids=True,
)
ids = inputs["input_ids"]
mask = inputs["attention_mask"]
token_type_ids = inputs["token_type_ids"]
targets = self.targets[index]
return {
"input_ids": ids.flatten(),
"attention_mask": mask.flatten(),
"token_type_ids": token_type_ids.flatten(),
"targets": torch.FloatTensor(targets),
}
training_set = CustomDataLoader(X_train, y_train, tokenizer, MAX_LENGTH)
validation_set = CustomDataLoader(X_val, y_val, tokenizer, MAX_LENGTH)
test_set = CustomDataLoader(X_test, y_test, tokenizer, MAX_LENGTH)
BS = 1
N_WORKERS = 2
train_sampler = RandomSampler(training_set)
training_set = DataLoader(training_set, batch_size=BS, num_workers=N_WORKERS, sampler=train_sampler)
validation_set = DataLoader(validation_set, batch_size=BS, shuffle=True, num_workers=N_WORKERS)
test_set = DataLoader(test_set, batch_size=BS, shuffle=True,num_workers=N_WORKERS,)
# ...
N_LABELS = 3
bert_config = BertConfig.from_pretrained("bert-base-uncased",
hidden_dropout_prob=.3,
num_labels = N_LABELS,
)
class BertForMulticlassClassification(BertPreTrainedModel):
def __init__(self, config: BertConfig, freeze_params = True):
super().__init__(config)
num_labels = config.num_labels
# model architecture
self.bert = BertModel(config)
self.classifier = nn.Sequential(
nn.Dropout(config.hidden_dropout_prob),
nn.Linear(config.hidden_size, config.hidden_size//16),
nn.Dropout(config.hidden_dropout_prob),
nn.Linear(config.hidden_size//16, num_labels)
)
self.loss_fct = nn.CrossEntropyLoss()
self.init_weights()
if freeze_params:
for param in self.bert.parameters():
param.requires_grad = False
def forward(self, input_ids, attention_mask, token_type_ids, labels=None, **args):
position_ids = args.get("position_ids", None)
head_mask = args.get("head_mask", None)
inputs_embeds = args.get("inputs_embeds", None)
""" Outputs of the bert model: https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertModel
The forward method of the base BertModel return a tuple of 3 values
- outputs[0] = last_hidden_state: Sequence of hidden-states at the output of the last layer of the model
- outputs[1] = pooler_output: last layer output, i.e. returns the classificatio token after passing through a linear layer and a tanh activation function
- outputs[2] = hidden_states: another tuple containing the output of the embeddings together with the output of each hidden state """
outputs = self.bert(input_ids, attention_mask=attention_mask, token_type_ids=token_type_ids, position_ids=position_ids, head_mask=head_mask, inputs_embeds=inputs_embeds)
# get the pooled_output
pooled_output = outputs[1]
# classify the instances
logits = self.classifier(pooled_output)
# build the outputs to return: concatenate in a tuple the predicted logits and the hidden states
outputs = (logits,) + outputs[2:]
if labels is not None:
loss = self.loss_fct(logits, labels)
outputs = (loss,) + outputs # concatenate in a tuple the loss, logits, hidden states and attentions
return outputs # (loss), logits, (hidden_states), (attentions)
model = BertForMulticlassClassification(bert_config)
model.to(device)
# optimizer
LEARNING_RATE = 1e-05
EPS = 1e-7
optimizer = optim.AdamW(params=model.parameters(), lr=LEARNING_RATE)
# scheduler
N_EPOCHS = 20
num_training_steps = N_EPOCHS * len(training_set)
lr_scheduler = get_scheduler(
name="linear", optimizer=optimizer, num_warmup_steps=3, num_training_steps=num_training_steps
)
# training step function
def train(model, optimizer, training_loader, device="cuda", verbose=True, **args):
# put model in train mode
model.train()
lr_scheduler = args.get('lr_scheduler', None)
num_classes = training_loader.dataset.targets.shape[1]
n_train_batches = len(training_loader)
epoch_train_loss = 0
epoch_train_acc = torch.zeros((num_classes), device=device)
epoch_train_recall = torch.zeros((num_classes), device=device)
epoch_train_precision = torch.zeros((num_classes), device=device)
epoch_train_f1 = torch.zeros((num_classes), device=device)
train_batch_steps = 1
for batch in training_loader:
ids = batch["input_ids"].to(device)
mask = batch["attention_mask"].to(device)
token_type_ids = batch["token_type_ids"].to(device)
targets = batch["targets"].to(device)
inputs = {
"input_ids": ids,
"attention_mask": mask,
"token_type_ids": token_type_ids,
"labels": targets,
}
# cast prediction probabilities
outputs = model(**inputs)
# compute loss and backpropagate it
loss = outputs[0]
epoch_train_loss += loss.item()
# compute accuracy
logits = outputs[1]
predicted_proba = F.softmax(logits, dim=1)
#acc = (predicted_proba.argmax(dim=1) == targets.argmax(dim=1)).sum().item() / targets.shape[0]
#total_acc += acc
# compute labels of prediction for metrics
predicted_labels = torch.zeros(predicted_proba.shape, device=device)
for row, pos in enumerate(predicted_proba.argmax(dim=1)):
predicted_labels[row, pos] = 1
# compute per class metrics
metrics = [
MulticlassRecall(num_classes=num_classes, average=None).to(device),
MulticlassAccuracy(num_classes=num_classes, average=None).to(device),
MulticlassPrecision(num_classes=num_classes, average=None).to(device),
MulticlassF1Score(num_classes=num_classes, average=None).to(device)
]
epoch_train_recall += metrics[0](predicted_labels, targets)
epoch_train_acc += metrics[1](predicted_labels, targets)
epoch_train_precision += metrics[2](predicted_labels, targets)
epoch_train_f1 += metrics[3](predicted_labels, targets)
# clear previously calculated gradients, update parameters
loss.backward()
model.zero_grad()
optimizer.step()
if lr_scheduler is not None:
lr_scheduler.step()
optimizer.zero_grad()
# clip the the gradients to 1.0. It helps in preventing the exploding gradient problem
#nn.utils.clip_grad_norm_(model.parameters(), 1.0)
# logging info
print_steps = {
int(n_train_batches * 0.2): f"||| [{train_batch_steps}/{n_train_batches}]",
int(n_train_batches * 0.4): f"|||||| [{train_batch_steps}/{n_train_batches}]",
int(n_train_batches * 0.60): f"||||||||| [{train_batch_steps}/{n_train_batches}]",
int(n_train_batches * 0.80): f"|||||||||||| [{train_batch_steps}/{n_train_batches}]",
n_train_batches: f"||||||||||||||| [{train_batch_steps}/{n_train_batches}]",
}
if train_batch_steps in print_steps:
verbosity(verbose, f"Batch training loss: {loss.item():.8f} {print_steps[train_batch_steps]}")
train_batch_steps += 1
return epoch_train_loss/n_train_batches, epoch_train_acc/n_train_batches, \
epoch_train_recall/n_train_batches, epoch_train_precision/n_train_batches, epoch_train_f1/n_train_batches
# eval step function
def evaluate(model, evaluation_loader, device="cuda", verbose=True):
# put model in evaluation mode
model.eval()
num_classes = evaluation_loader.dataset.targets.shape[1]
n_eval_batches = len(evaluation_loader)
epoch_eval_loss = 0
epoch_eval_acc = torch.zeros((num_classes), device=device)
epoch_eval_recall = torch.zeros((num_classes), device=device)
epoch_eval_precision = torch.zeros((num_classes), device=device)
epoch_eval_f1 = torch.zeros((num_classes), device=device)
eval_batch_steps = 1
for batch in evaluation_loader:
with torch.no_grad():
ids = batch["input_ids"].to(device)
mask = batch["attention_mask"].to(device)
token_type_ids = batch["token_type_ids"].to(device)
targets = batch["targets"].to(device)
inputs = {
"input_ids": ids,
"attention_mask": mask,
"token_type_ids": token_type_ids,
"labels": targets,
}
outputs = model(**inputs)
# Take computed loss and predicted labels
eval_loss, logits = outputs[:2]
predicted_proba = F.softmax(logits, dim=1)
#acc = (predicted_proba.argmax(dim=1) == targets.argmax(dim=1)).sum().item() / targets.shape[0] # freq / batch_size
#total_acc += acc
# compute labels of prediction for metrics
predicted_labels = torch.zeros(predicted_proba.shape, device=device)
for row, pos in enumerate(predicted_proba.argmax(dim=1)):
predicted_labels[row, pos] = 1
# compute per class metrics
metrics = [
MulticlassRecall(num_classes=num_classes, average=None).to(device),
MulticlassAccuracy(num_classes=num_classes, average=None).to(device),
MulticlassPrecision(num_classes=num_classes, average=None).to(device),
MulticlassF1Score(num_classes=num_classes, average=None).to(device)
]
epoch_eval_recall += metrics[0](predicted_labels, targets)
epoch_eval_acc += metrics[1](predicted_labels, targets)
epoch_eval_precision += metrics[2](predicted_labels, targets)
epoch_eval_f1 += metrics[3](predicted_labels, targets)
# update current validation loss
epoch_eval_loss += eval_loss.item()
# logging info
print_steps = {
int(n_eval_batches * 0.2): f"||| [{eval_batch_steps}/{n_eval_batches}]",
int(n_eval_batches * 0.4): f"|||||| [{eval_batch_steps}/{n_eval_batches}]",
int(n_eval_batches * 0.60): f"||||||||| [{eval_batch_steps}/{n_eval_batches}]",
int(n_eval_batches * 0.80): f"|||||||||||| [{eval_batch_steps}/{n_eval_batches}]",
n_eval_batches: f"||||||||||||||| [{eval_batch_steps}/{n_eval_batches}]",
}
if eval_batch_steps in print_steps:
verbosity(verbose, f"Batch evaluation loss: {eval_loss.item():.8f} {print_steps[eval_batch_steps]}")
eval_batch_steps += 1
return epoch_eval_loss/n_eval_batches, epoch_eval_acc/n_eval_batches, \
epoch_eval_recall/n_eval_batches, epoch_eval_precision/n_eval_batches, epoch_eval_f1/n_eval_batches
# train loop
def train_cycle(training_loader, validation_loader, model, optimizer, n_epochs=5, verbose=True, **args):
# get device
try:
global device
except:
device = "cuda" if torch.cuda.is_available() else "cpu"
s = f"###### Initializing training process on {device} ######"
msgs = [
"",
"#"*len(s),
s,
"#"*len(s),
f""]
for msg in msgs:
verbosity(verbose, msg)
export_params = {"export_path": "./models/", "model_name": "model"}
for k, v in args.items():
if k in export_params.keys():
export_params[k] = v
if not os.path.exists(export_params["export_path"]):
os.mkdir(export_params["export_path"])
# target validation loss to minimize
val_min_loss = args.get("val_min_loss", np.Inf)
best_val_acc = 0
# define epochs iterable
start_from_epoch = args.get("start_from_epoch", None)
epochs_iters = range(1, n_epochs + 1) if start_from_epoch is None else range(start_from_epoch, start_from_epoch + n_epochs)
# early stopping
monitor = None
early_stopping = args.get("early_stopping", None)
if early_stopping is not None:
monitor = args.get("monitor", "val_loss")
monitor = monitor if monitor in ["val_loss", "val_acc", "train_loss"] else "val_loss"
msgs = [f"Early stopping callback succesfully set: monitoring '{monitor}' with tolerance = {early_stopping.tolerance} epochs and min_delta = {early_stopping.min_delta}", ""]
for msg in msgs:
verbosity(verbose, msg)
lr_scheduler = args.get('lr_scheduler', None)
# variable to story history
history = {"train": {}, "val": {}}
for epoch in epochs_iters:
start_at = datetime.now()
msgs = [f"{' '*25}Epoch {epoch}", "-" * 60]
for msg in msgs:
verbosity(verbose, msg)
# model training
train_loss, train_acc, train_recall, train_precision, train_f1 = train(model, optimizer, training_loader, device, verbose, lr_scheduler=lr_scheduler)
avg_train_acc = np.mean(train_acc.detach().cpu().numpy())
msgs = [f"", "Starting validation..."]
for msg in msgs:
verbosity(verbose, msg)
# model evaluation
val_loss, val_acc, val_recall, val_precision, val_f1 = evaluate(model, validation_loader, device, verbose)
avg_val_acc = np.mean(val_acc.detach().cpu().numpy())
# print metrics
msgs = [
f"",
f"{'':<10}{'train accuracy':<17}{'val accuracy':<15}{'train recall':<15}{'val recall':<15}{'train precision':<18}{'val precision':<15}{'train f1':<12}{'val f1':<12}",
'\n'.join([f"{f'class {i}':<10}{train_acc[i]:<17.5f}{val_acc[i]:<15.5f}{train_recall[i]:<15.5f}{val_recall[i]:<15.5f}{train_precision[i]:<18.5f}" \
f"{val_precision[i]:<15.5f}{train_f1[i]:<12.5f}{val_f1[i]:<12.5f}" for i in range(train_acc.shape[0])]),
f"Train accuracy: {avg_train_acc:.5f} Evaluation accuracy: {avg_val_acc:.5f} Train loss: {train_loss:.5f} Eval loss: {val_loss:.5f}",
f"",
f"Epoch {epoch} took: {datetime.now() - start_at}",
f"",
]
for msg in msgs:
verbosity(verbose, msg)
history['train'][f"epoch{epoch}"] = {
'accuracy': avg_train_acc,
'loss': train_loss
}
history['val'][f"epoch{epoch}"] = {
'accuracy': avg_val_acc,
'loss': val_loss
}
# save the model if validation loss has decreased
if val_loss < val_min_loss and avg_val_acc >= best_val_acc:
# create checkpoint variable
checkpoint = {
"min_val_loss": val_loss,
"best_val_acc": avg_val_acc,
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
"history": history,
}
# save checkpoint as best model
model_name = f"{export_params['model_name']}-e{epoch}.pt"
save_ckpt(checkpoint, f"{export_params['export_path']}{model_name}")
msgs = [
f"Validation loss decreased from {val_min_loss:.8f} to {val_loss:.8f}, whereas validation accuracy increased from {best_val_acc:.8f} to {avg_val_acc:.8f}",
f"Model has been saved in directory '{export_params['export_path']}' as '{model_name}'",
f""
]
for msg in msgs:
verbosity(verbose, msg)
# update minimum loss with new values
val_min_loss = val_loss
best_val_acc = avg_val_acc
# early stopping callback
mntr, metric = monitor.split("_")
if early_stopping is not None and monitor is not None and len(history[mntr].keys()) > 1:
previous_step_metric = history[mntr][f"epoch{epoch-1}"][metric]
metric1 = train_loss if monitor == "train_loss" else (avg_val_acc if monitor == "val_acc" else val_loss)
early_stopping(metric1, previous_step_metric)
if early_stopping.stop:
msgs = [f"Maximum EarlyStopping tolerance ({early_stopping.tolerance} epochs) has been exceeded, stopping algorithm", ""]
for msg in msgs:
verbosity(verbose, msg)
break
# calling the loop
train_cycle(
training_set,
validation_set,
model,
optimizer,
verbose=True,
export_path=checkpoint_path,
model_name=model_prefix,
n_epochs=N_EPOCHS,
early_stopping=early_stopper,
lr_scheduler=lr_scheduler
)
I would be so thankful if someone could help me out, I've been trying for more than a week already.
Cheers,
David