your approach is correct. Don´t think you need to change it.
Long answer
If you wanted each sentence to be a batch, then you would do it as in the first post (before editing).
Here is more information about batches and preprocessing for the tokenizer.
tokenizer(["hello i am going","to","Rome"])
However, as you mentioned before, you do NOT want this, but rather 1 Dimensional ids of multiple sentences.
If you go to the BertTokenizer and to the PreTrainedTokenizer documentation and look for the __call__ method you will see which parameters it accepts.
The most relevant for us right now are text and text_pair. Both accept the same types described below.
text + text_pair
Both sentences are merged into a 1D vector, separated with the [SEP] = 102 token.
tokenizer(text="hello i am going, to", text_pair="Rome")
# {'input_ids': [101, 7592, 1045, 2572, 2183, 1010, 2000, 102, 4199, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 1, 1], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
Parameters accepted in text / text_pair
str
This is the most simple case. You only input one str. This can be a word or a sentence.
tokenizer("hello i am going to Rome")
#{'input_ids': [101, 7592, 1045, 2572, 2183, 2000, 4199, 102], 'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1]}
List[str]
Here we define a batch of sentences to be tokenized.
tokenizer(["hello i am going","to","Rome"])
# {'input_ids': [[101, 7592, 1045, 2572, 2183, 102], [101, 2000, 102], [101, 4199, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0], [0, 0, 0], [0, 0, 0]], 'attention_mask': [[1, 1, 1, 1, 1, 1], [1, 1, 1], [1, 1, 1]]}
List[List[str]]
Now this is the case you are trying to do. However, even though it is not explicit anywhere (at least I did not find it), this list of lists is not for sequences of any length. As far as I understood, the outer list refers to the batches. However, the inner list is for a pair of sentences that will be treated like text - text_pair. If you enter more than 2 sentences in a batch, you will get an error.
Here is an example for two batches adding the special token manually.
encoded_input = tokenizer(text=[["hello i am going [SEP] to [SEP] Rome", "other sentence"], ["next", "batch"]])
print("input: ", encoded_input)
print("batch 1: ", tokenizer.decode(encoded_input["input_ids"][0]))
print("batch 2: ", tokenizer.decode(encoded_input["input_ids"][1]))
# Output:
# input: {'input_ids': [[101, 7592, 1045, 2572, 2183, 102, 2000, 102, 4199, 102, 2060, 6251, 102], [101, 2279, 102, 14108, 102]], 'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 1, 1], [0, 0, 0, 1, 1]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 1, 1, 1, 1]]}
# batch 1: [CLS] hello i am going [SEP] to [SEP] rome [SEP] other sentence [SEP]
# batch 2: [CLS] next [SEP] batch [SEP]
As you can see, the manually added special tokens are treated the same when encoding and decoding the sentence. The problem is that token_type_ids can only be 0 or 1, there are no more ids for a third sentence.
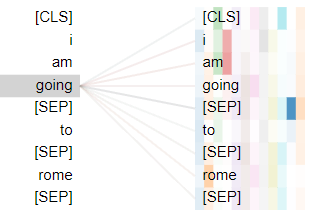
You can use a visualization tool like BertViz to see how your sentences behave and if it is your desired behavior.
going attends to to
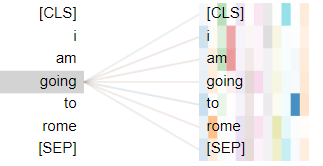
- With
[`SEP]`` token goingattends to[SEP], almost does not notice to```