class Model(nn.Module):
def __init__(self):
super().__init__()
self.f = []
for name, module in resnet50().named_children():
if name == 'conv1':
module = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
if not isinstance(module, nn.Linear) and not isinstance(module, nn.MaxPool2d):
self.f.append(module)
def forward(self, x):
x = self.f(x)
feature = torch.flatten(x, start_dim=1)
return F.normalize(feature, dim=-1)
However, the second approach converges with the loss I defined while the first approach does not. My question is what’s the difference and why does the second one work? What am I missing here?
Did you print both models and compared which submodules are registered as I would expect to see differences based on your filtering in the second approach.
Also, I don’t think the original reset implementation uses a normalization at the end of the forward pass, so this would be a difference, too.
Thanks for the reply @ptrblck.
Yes, I compared the models and as you mentioned, in the filtering, we don’t have Linear (only last layer has) and MaxPool2d (only first layer has) anymore, and also the kernel size in the first layer has been changed from 7 to 3. And you are right, the original resnet does not have a normalization, however, in the training loop, I took care of that and I applied the normalization in the forward of the bigger model.
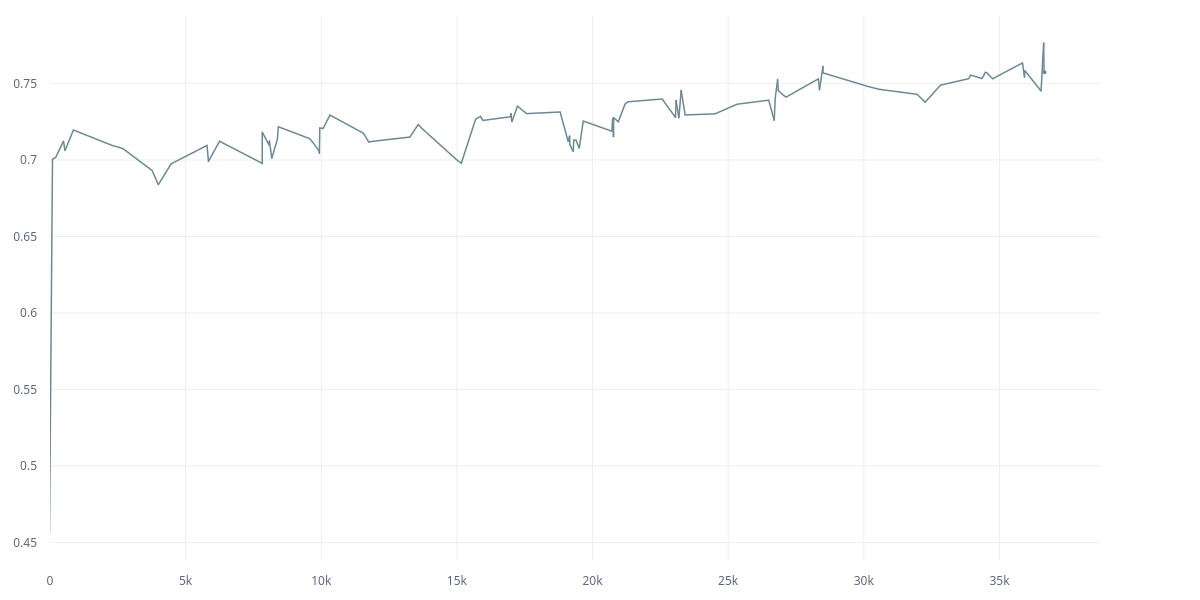
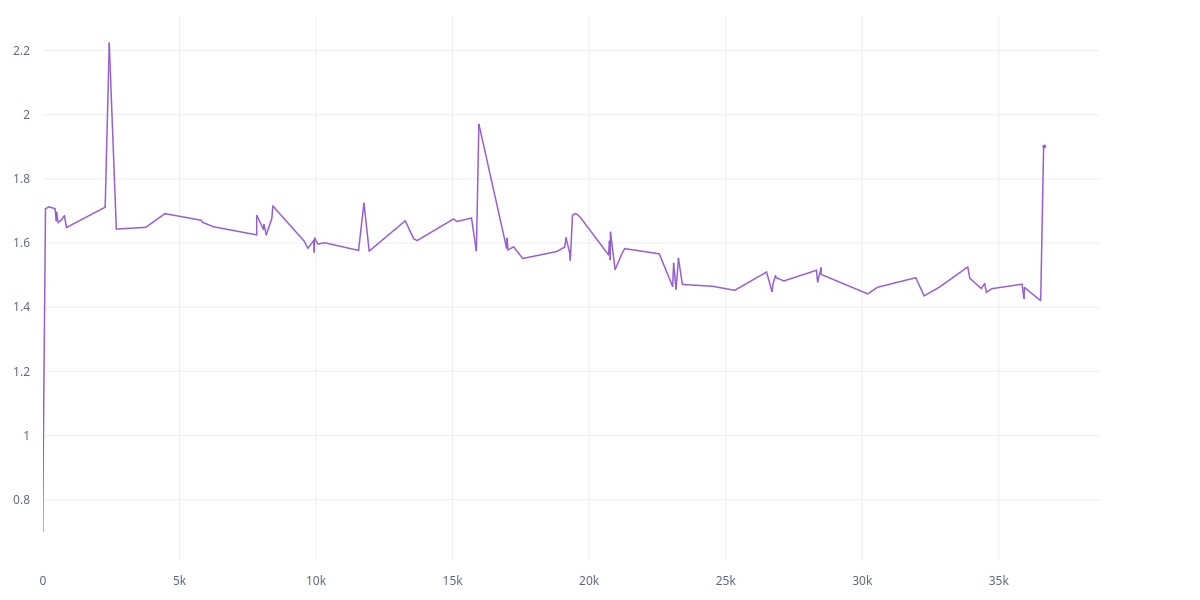
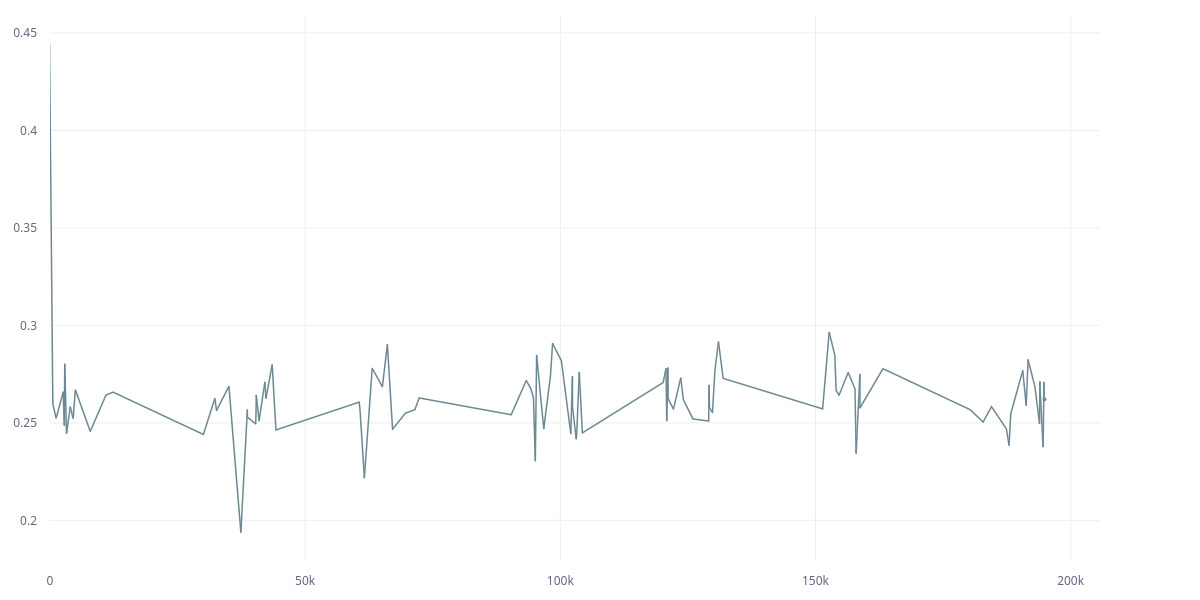
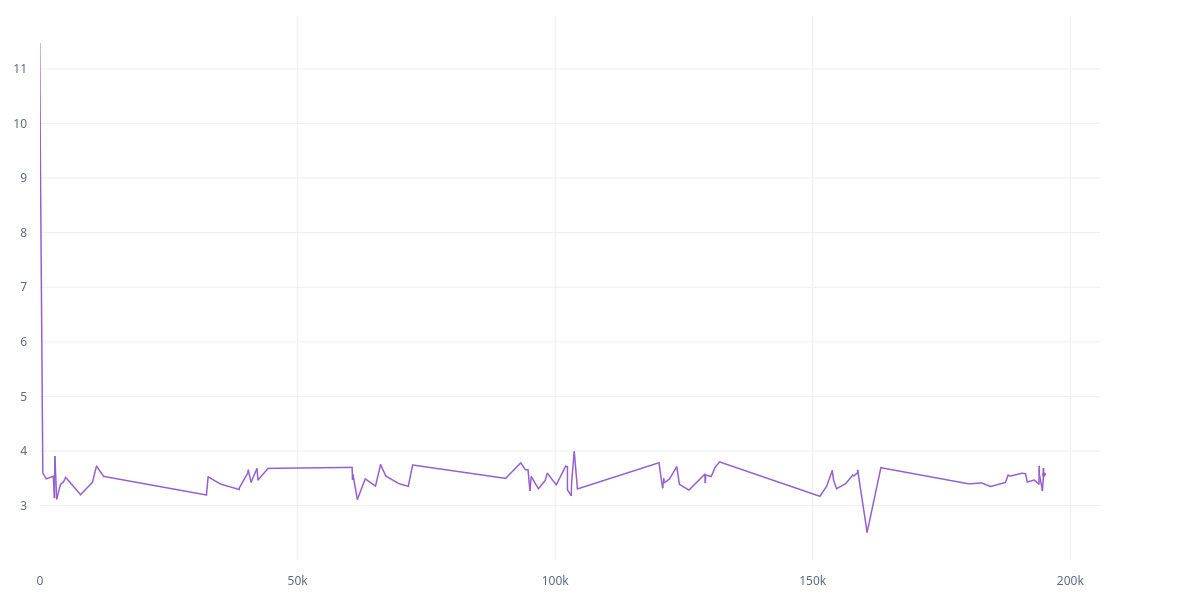
The thing is, the second approach is taken from a public repo (an SSL paper from Meta), and the first one was my implementation. Here are the L2 and cov loss between two models for the first approach (it’s an SSL model):
I don’t understand why such a huge difference in training. Is it because of removing Linear and Maxpooling? There was no mention of the effect of pooling in the paper. And what is the best approach to use Resnet? The first approach seems easier and I it was actually suggested here. Does Identity() breaks gradient backpropagation? It doesn’t seem to me to do so according to it’s source.
No, nn.Identity modules do not break the computation graph.
Based on your description it seems you are changing a lot and it might make sense to verify smaller submodules for their parity first.
I checked the changed modules (First conv kernel size, and removing the MaxPool2d) by commenting out the filters in the for loop. They didn’t affect the model’s convergence. Still, the model converged while the first approach diverged.
I couldn’t figure out the reason for the divergence in the first approach and convergence in the second approach. I’m moving forward with the second approach for now. Thanks for the help.