Thanks for the reply @ptrblck.
Yes, I compared the models and as you mentioned, in the filtering, we don’t have Linear (only last layer has) and MaxPool2d (only first layer has) anymore, and also the kernel size in the first layer has been changed from 7 to 3. And you are right, the original resnet does not have a normalization, however, in the training loop, I took care of that and I applied the normalization in the forward of the bigger model.
The thing is, the second approach is taken from a public repo (an SSL paper from Meta), and the first one was my implementation. Here are the L2 and cov loss between two models for the first approach (it’s an SSL model):
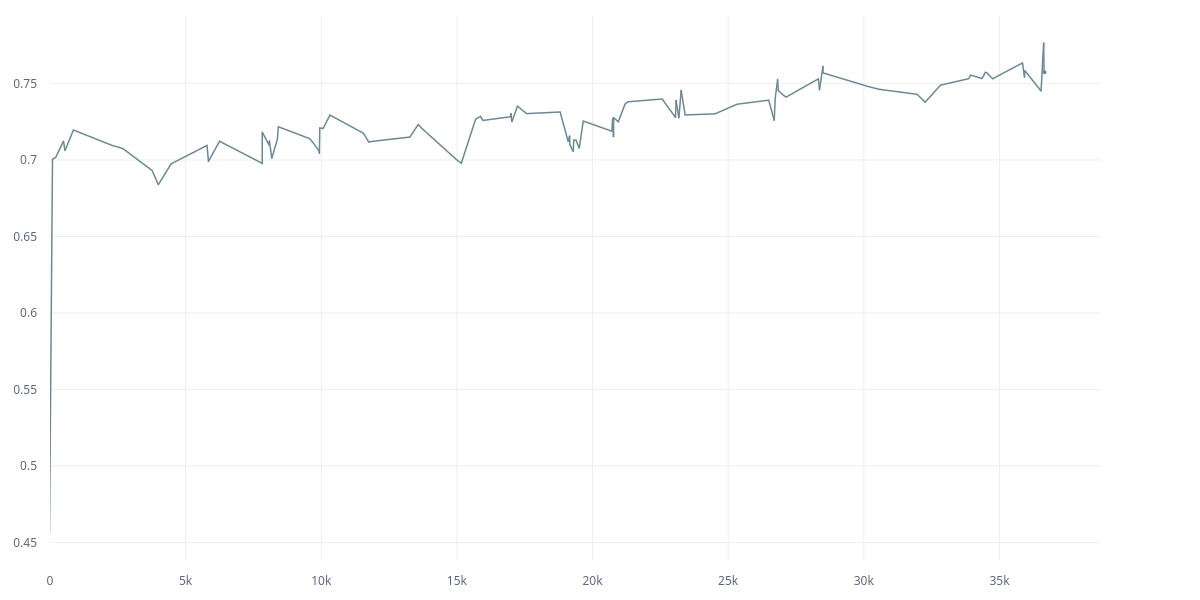
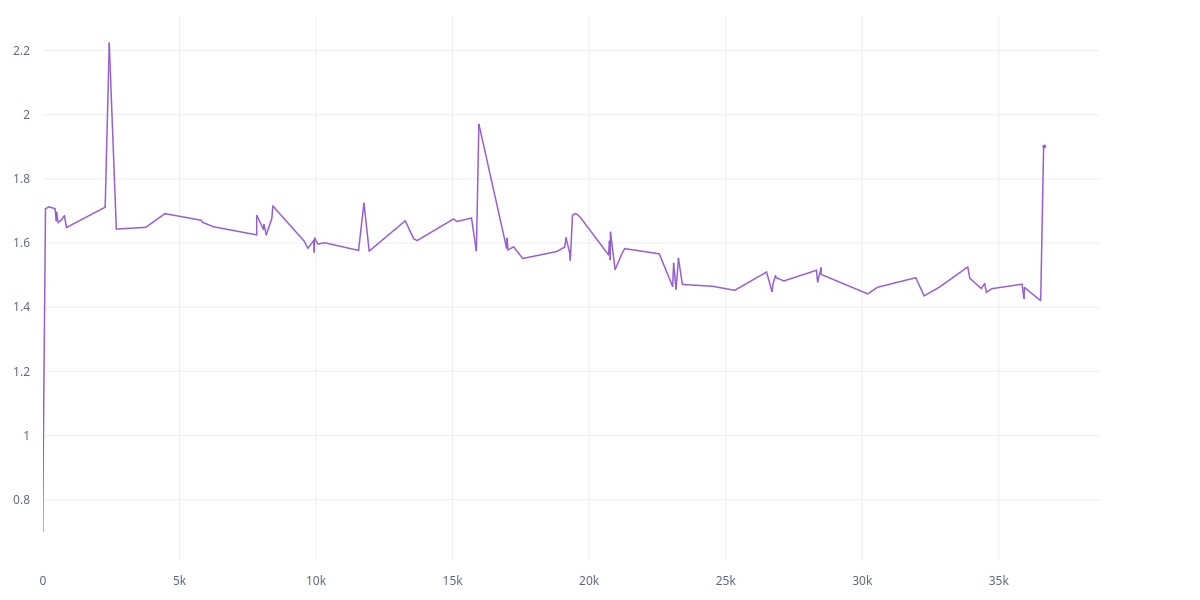
However, if I use the second approach (the Meta one), here are the L2 and cov:
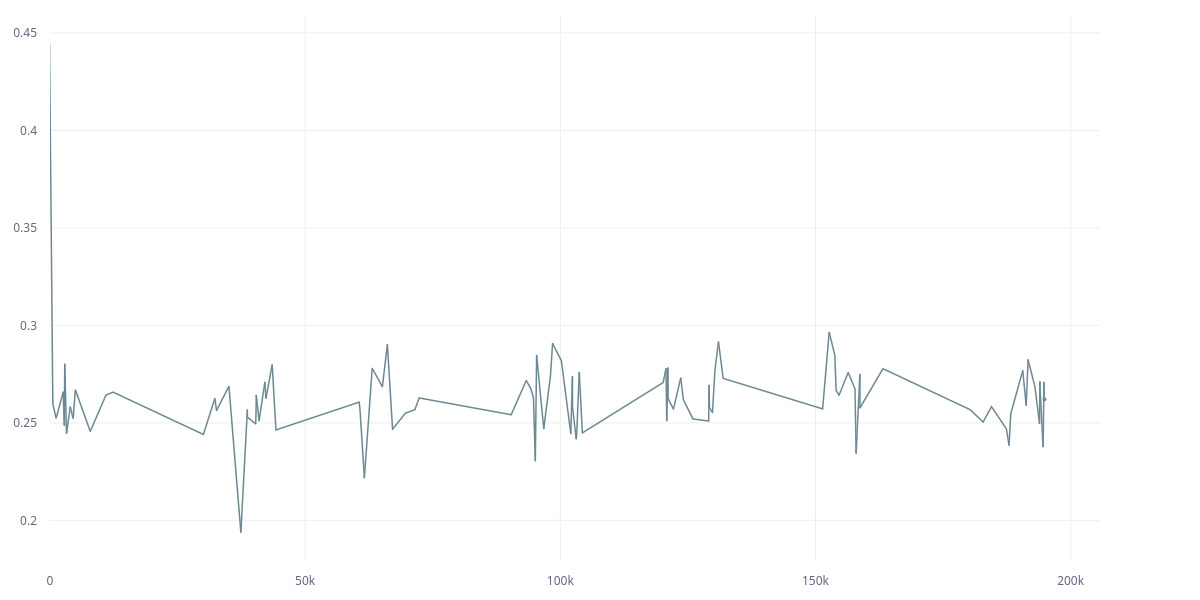
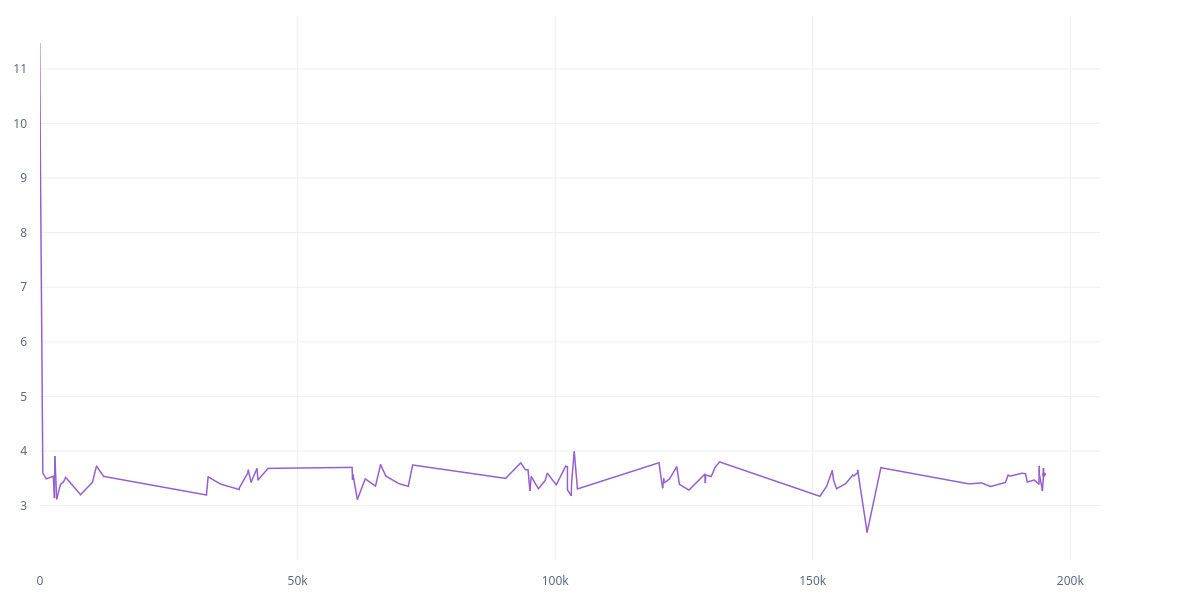
I don’t understand why such a huge difference in training. Is it because of removing Linear and Maxpooling? There was no mention of the effect of pooling in the paper. And what is the best approach to use Resnet? The first approach seems easier and I it was actually suggested here. Does Identity() breaks gradient backpropagation? It doesn’t seem to me to do so according to it’s source.