I am doing a pixel-wise regression using VNet architecture. The loss decreases continuously over epochs, as expected and the loss function has a form of ln(L1 x L2) where L1 and L2 are lagrangian and eulerian MSE Losses. The very weird thing is that the predictions of the model after epoch 1 is wayyyyy better than the one from epoch 30 or 50 etc. I am training on 51200 samples, each of shape (3,64,64,64) and testing is performed on 5120 samples of the same shape.
The loss function looks as follows:
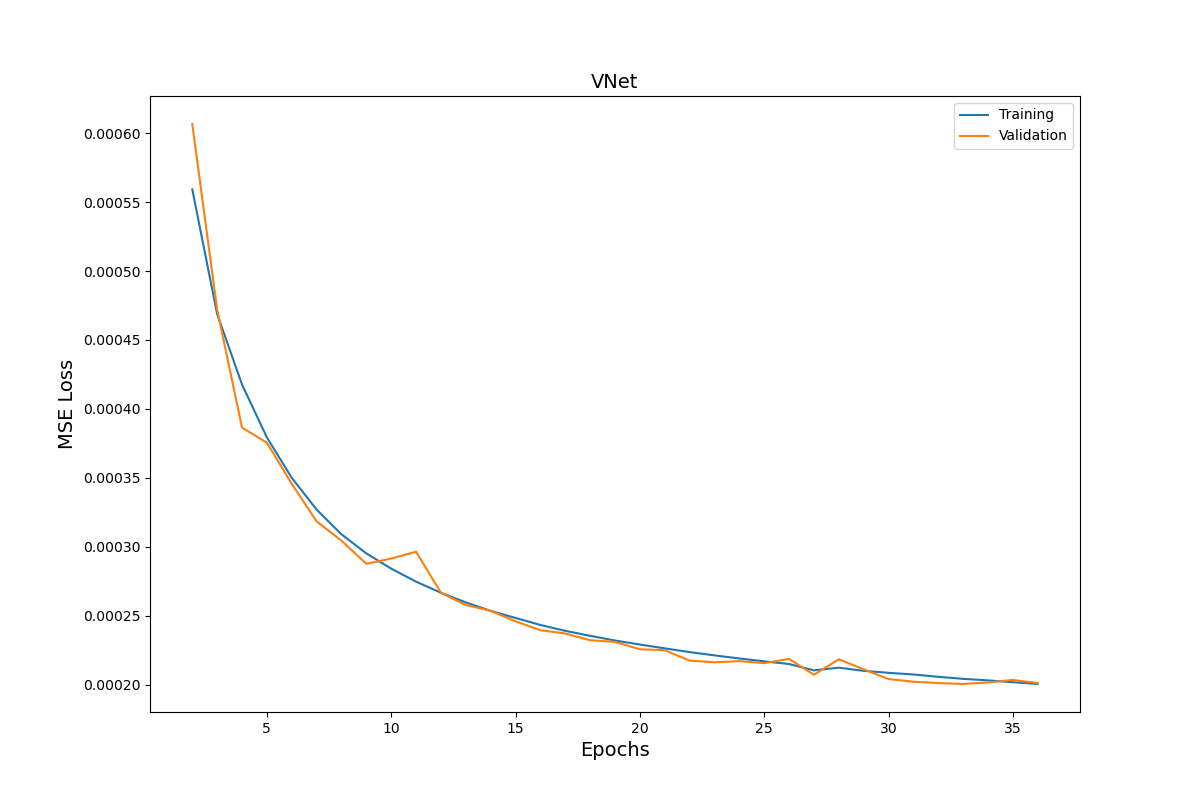
The predictions (one of the 4 statistics we use) is as follows:
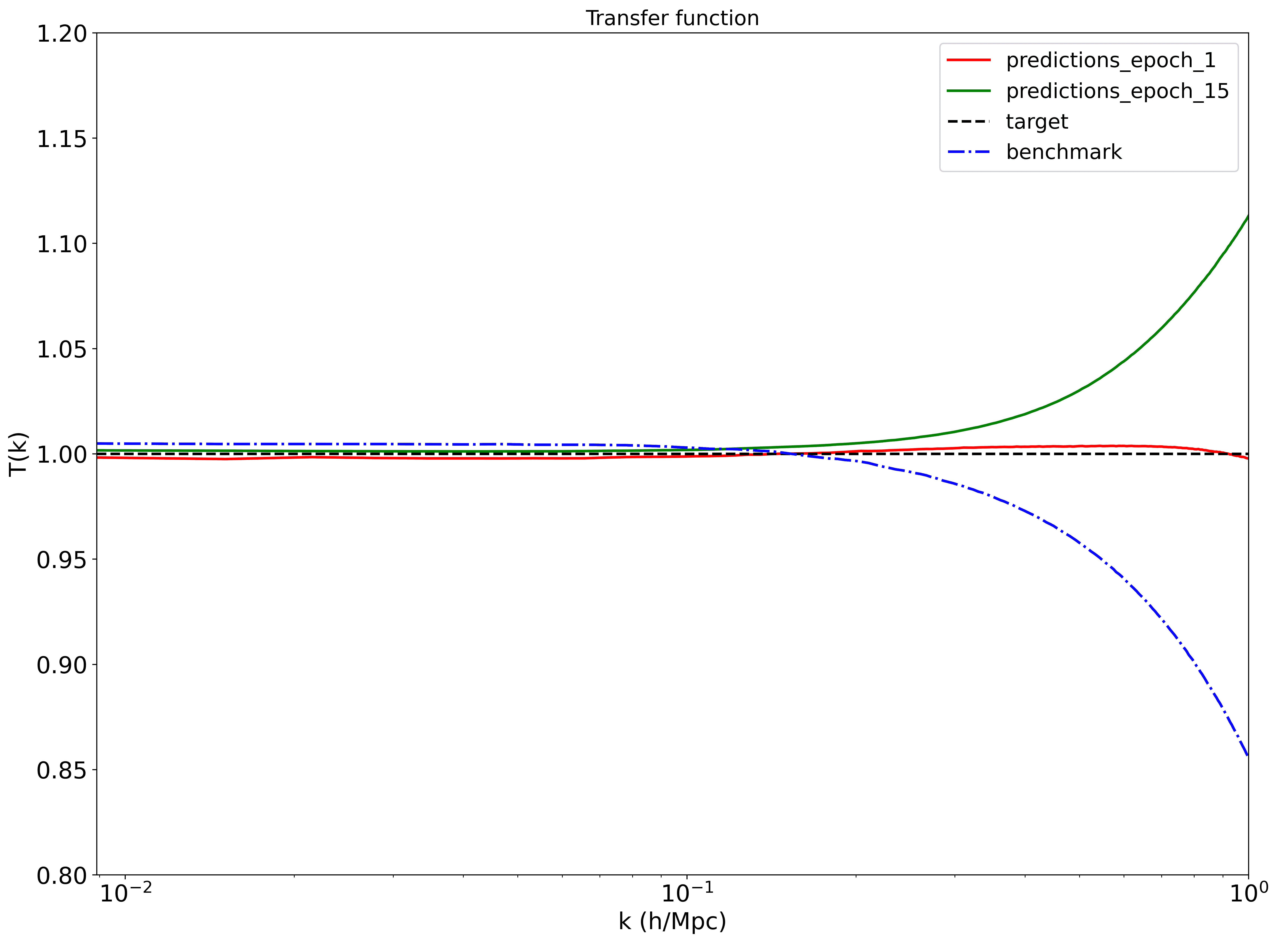
What might be wrong?