Hey everyone, I’m testing how both frameworks differ in their calculations at the same time I’m trying to make both close to same as possible. Well for this tests I use the same weights and bias parameters in Initialization for the same equivelant network arquitecture.
For this specific case I’m using a SGD optimizer with momentum at 0. I also use a custom function for the optimizer in Tensorflow so it becomes as similar to Pytorch.
# Given a callable model, inputs, outputs, and a learning rate...
def train_SGD_momentum0(model, x, y, learning_rate):
layer = 0
with tf.GradientTape(persistent=True) as t:
# Trainable variables are automatically tracked by GradientTape
current_loss = loss_func_TF(y, model(x))
for k in range(0,len(model.variables),2):
w = model.variables[k] #tf.Variable(model.get_weights()[0])
b = model.variables[k+1] # tf.Variable(model.get_weights()[1])
# Use GradientTape to calculate the gradients with respect to W and b
dw, db = t.gradient(current_loss, [w,b])
while type(model.layers[layer]) is keras.layers.MaxPooling2D or type(model.layers[layer]) is keras.layers.Dropout or type(model.layers[layer]) is keras.layers.Flatten:
layer=layer+1
# Subtract the gradient scaled by the learning rate
model.layers[layer].kernel.assign_sub(learning_rate * dw)
model.layers[layer].bias.assign_sub(learning_rate * db)
layer = layer +1
For the models training I’m using a costum function where i use the same inputs for Pytorch network and permute them to use it in Tensorflow training loop.
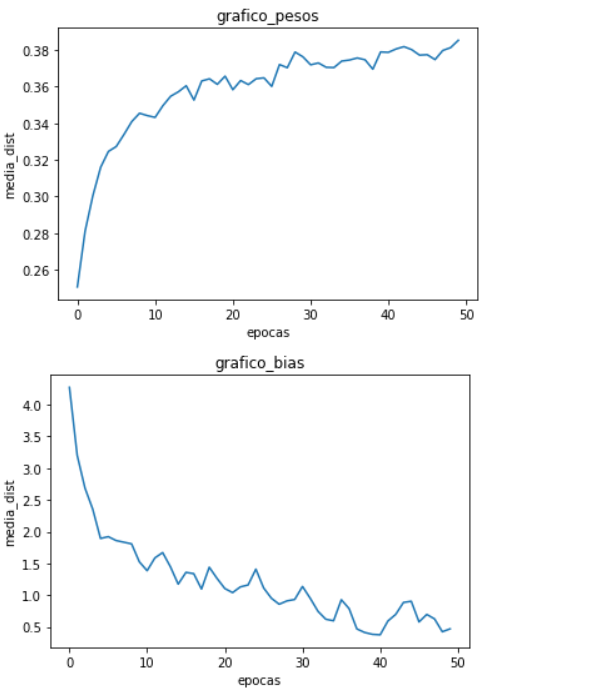
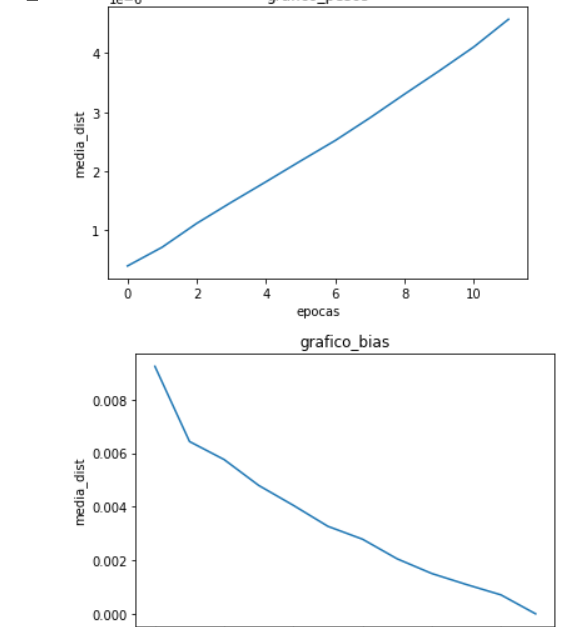
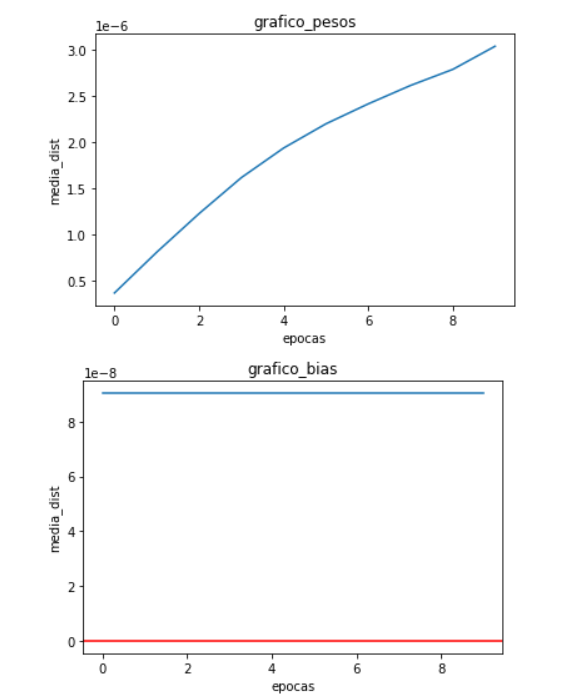
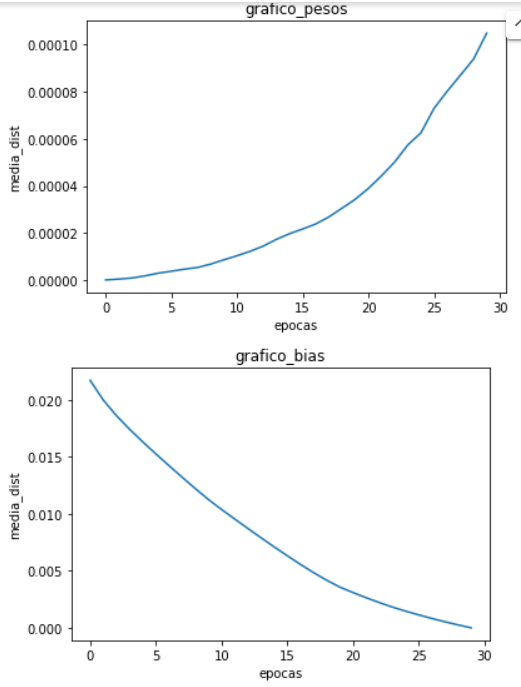
I run this in some different datasets and this was what i got:
For every figure above the first graphic represents the avarege difference of weights of both networks and the second represents the avarege difference of the biases of both networks.
My question is comes in what conclusion i can take from the first three where the avarege difference of weights become higher epoch after epoch and the biases become lower. And what for the same pipeline taken in the firsts three datasets why did GTSRB become different and is diverging?
Thanks a lot for all the help
Are you seeing these differences only between the frameworks or also if you just rerun the same training pipeline in a single framework?
If you are not making sure the outputs are bitwise deterministic, I would expect to see a difference convergence behavior and a different set of final parameters even in the same framework (the final accuracy might still be approx. equal).
So the weights seems to diverge and bias seems to be allways the same, i also got the same acc but the loss are diferrent on the evaluation of the models. I also got some really close different losses per batch in the training loop. So am I doing something wrong and if so what it is?
Here is also the training loop:
niter = 10
n_samples = len(train_pt)
for epoca in range(0, niter):
for i,(image_element,target_element) in enumerate(train_pt):
optimizer.zero_grad()
predictions = net(image_element)
loss = loss_criterion(predictions, target_element)
loss.backward()
optimizer.step()
net2.zero_grad()
outputs2 = net2(image_element)
loss2 = loss_criterion(outputs2, target_element)
loss2.backward() # compute gradients
for f in net2.parameters():
f.data.sub_(f.grad.data * optimizer.defaults['lr'])
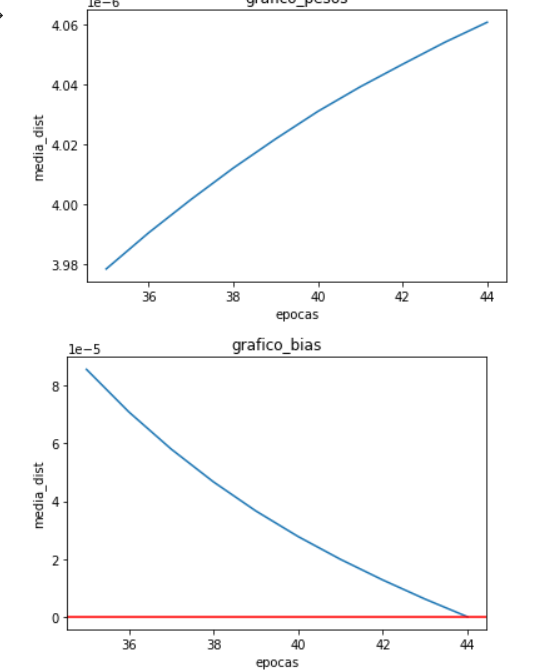
Differences in the 1e-6 range are expected for float32 if no-deterministic algorithms are used due to the limited floating point precision. You would also expect to see the same or a similar behavior using the same framework and different runs in case you are only seeding but are not forcing the usage of deterministic algorithms which is why I asked you to compare different runs in the same framework first.
Hey @ptrblck thanks again for the anwser. What bother me is the fact that the difference in weights is growing and not stable or 0 which i expect in case of the run in same framework. I really wanted to understand why in some cases the biases are becoming closer but in the GTSRB looks like are diverging, Could you give me some explanation about it?. Another thing is why, in the same framework, since I’m using the same pipeline, same models , same initialization and same seeds but the average difference of weights are not constant like the biases? I expected it to produce the same floating error at least. Also how can i make my algoritms deterministic in this case?
I don’t think this is a valid expectation. Let’s assume you are indeed using non-deterministic algorithms (you haven’t confirmed it): the output would differ by a “small” amount in the forward pass, the gradients would thus also have a small error (from the small error in the output as well as from non-deterministic algorithms to compute them), and the parameter updates would eventually move the entire parameter set using these small errors. Once the parameters were updated, the next iteration will still create the expected small absolute error caused by the non-deterministic algorithms, but will also increase the overall error in the output since the parameters now also differ.
I would not expect to see the model would “correct” it somehow and don’t know why it should happen, so could you explain your expectation a bit more?
Check the Reproducibility docs which explain how to force deterministic algorithms.
Hey @ptrblck, thanks again for your answer :). My goal here is to really understand how close i can get both frameworks to produce the same output. As far I as understood, there are differences than can be caused by differences in algoritms calculations or the default initializations. So the point here is to reduce the much as possible in the differences of the output so I be able to “name” the causes to the small growing errors occuring in the training process.
So if I take the case of checking differences between both frameworks what i got is that even without any training and just transposing the weights and biases to the other framework it will produce an small error on the loss and the acc about 1e-6 in the evaluation of any test set tested.
Due to this small small value and taking the fact that individualy calculating the loss for every input there are some that produce losses with really small differences and others which are exactly the same, i was ready for differences in the training just like what we can see from the weights graphic. The thing is, why are the biases taking a different behaviour of the weights and getting closer. What was going on my mind was that even if the weights were “diverging” the biases in other way were converging in compensation arround the error value because it was getting in the minimum. But there we go, I found one case where biases were not taking the same behaviour of the last one and were diverging. So about this part i want to understand if Im in a good spot or if Im wrong and there are more aspects to take in mind before i can assume the value error is only because of the floating calculations.
Now about the differences in the same framework it bring me a new point that maybe i havent deterministic all the process. But fun fact the biases in this case take another behaviour that is being constant.
I tried to resume all the idea so maybe you can get better my doubt about what i have obtained.
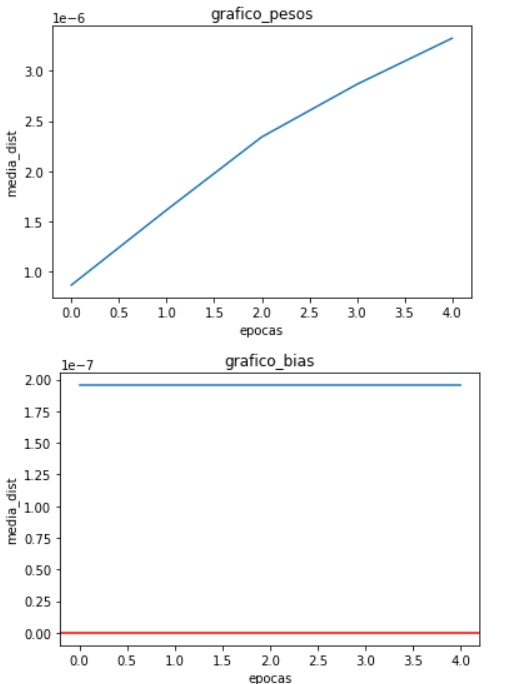
Hey @ptrblck. I have noticed that i was almost using everything for the reproducibility expect
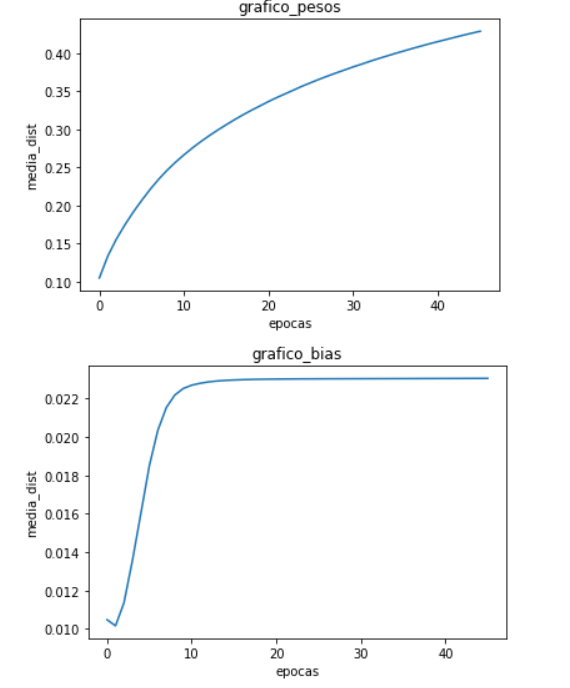
torch.use_deterministic_algorithms(True). Well for the rest I found out that for the training I had a small mistake done in the GTSRB dataset and after correct it this is how the avareage difference is:
Also an extra i found out that the loss value at the beginning when i eval the model with the test data is exactly the same but when it comes to training the loss slowly start to differ but in the firsts iterations is the same in 1e-15.