This is more generally the case with any RNN that uses bi-directionality.
We can see what is occurring by printing out the parameters per weight tensor, as follows:
import torch.nn as nn
model = nn.LSTM(20, 50, 3, bias=False)
model2 = nn.LSTM(20, 50, 3, bias=False, bidirectional=True)
for param in model.parameters():
print(param.size())
print("-----")
for param in model2.parameters():
print(param.size())
That should produce:
torch.Size([200, 20])
torch.Size([200, 50])
torch.Size([200, 50])
torch.Size([200, 50])
torch.Size([200, 50])
torch.Size([200, 50])
-----
torch.Size([200, 20])
torch.Size([200, 50])
torch.Size([200, 20])
torch.Size([200, 50])
torch.Size([200, 100])
torch.Size([200, 50])
torch.Size([200, 100])
torch.Size([200, 50])
torch.Size([200, 100])
torch.Size([200, 50])
torch.Size([200, 100])
torch.Size([200, 50])
We can then look at the original RNN Bidirectional paper:
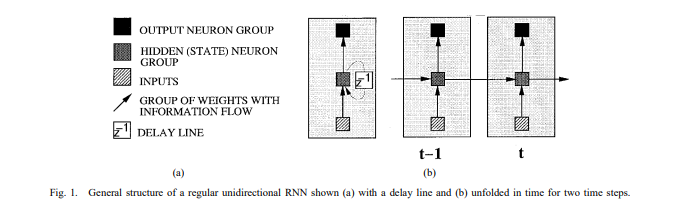
A standard RNN layer looks like this:
With each arrow, we have a set of weights. Normally, in an RNN, the above sizes would only differ in that the dim 0 would be the same as the hidden dim, i.e. (50, 20), (50, 50), etc.
The 1 dim of the tensors conveys the input size into that tensor(it may seem counterintuitive to put the output size as dim 0 and input size as dim 1, but this is done for functionality and speed because of how the matmul operation works, not for our viewing convenience, but I digress).
LSTMs have 4x the size of outputs due to the gating channels involved(i.e. 200 for LSTM vs. 50 for RNN in this example), but we’re not delving into that here. We’ll just use the RNN case, as it applies the same to all types of RNNs(LSTM, GRU, etc.).
So each layer in a unidirectional RNN has the weights giving input into the hidden state. Then an activation function is used to decide whether to keep the old state elementwise or use the new. The second set of weights is used after it goes through the activation. Hence the two weights per layer for a unidirectional RNN.
So now we come to the bidirectional RNN:
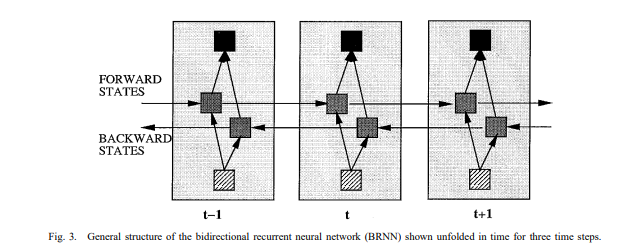
Drawing from the same paper, we see that there are double the arrows vertically, so 1 layer now has 4 sets of weights instead of 2. Each for forward and backward, two applied to the inputs and two applied to the old state.
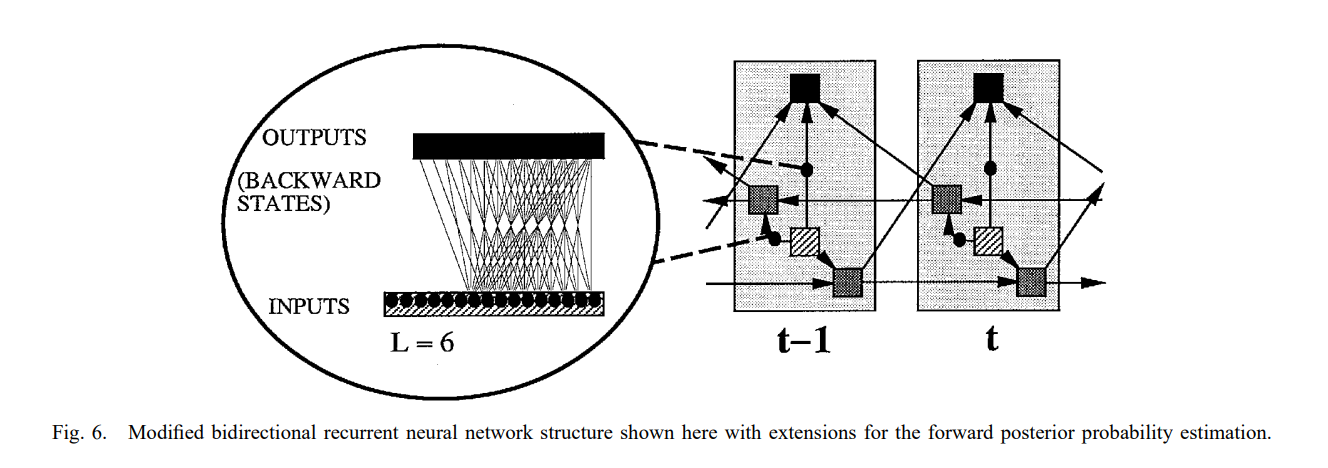
Further in the paper, Schuster proposed a modified BRNN which looks like this:
We can see what gets passed to later layers as inputs are:
- The current hidden combined with the last hidden(i.e. torch.cat);
- The current hidden combined with the next hidden;
Those yield double the hidden size as an input to the set of weights for subsequent layers.