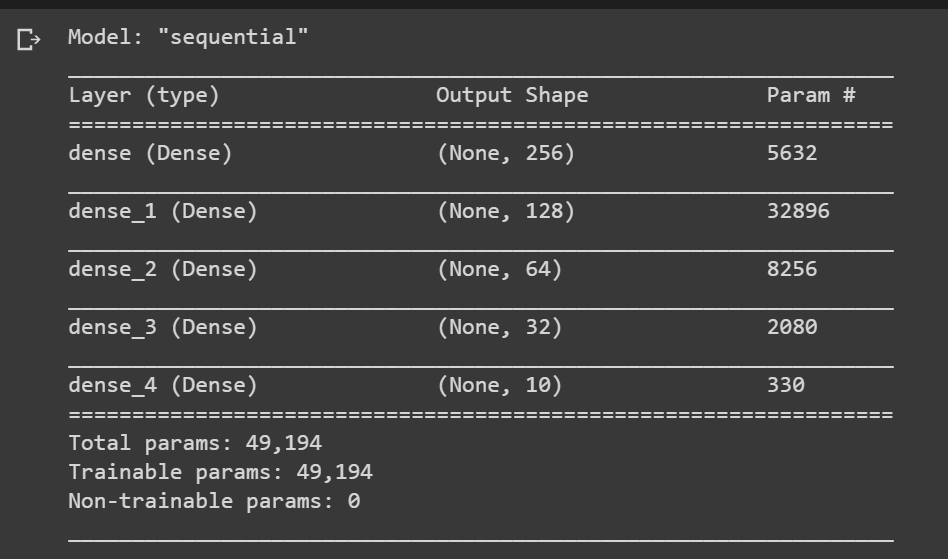
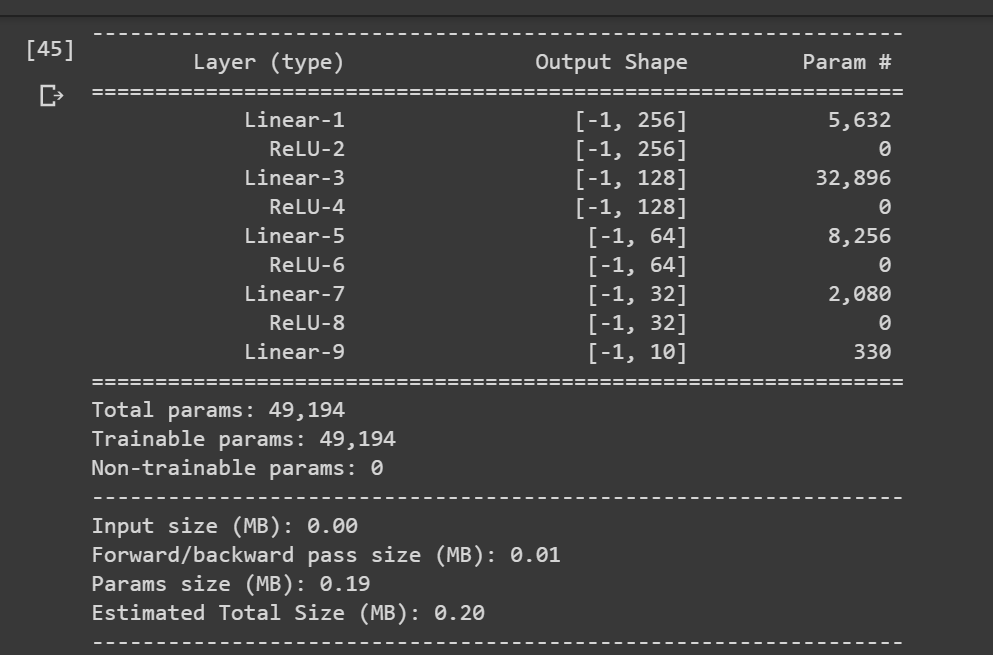
Here is the keras architecture
model=Sequential()
model.add(Dense(units=255,activation='relu',input_shape=[21]))
model.add(Dense(units=128,activation='relu'))
model.add(Dense(units=64,activation='relu'))
model.add(Dense(units=32,activation='relu'))
model.add(Dense(units=10,activation='softmax'))
Here is the pytorch architecture
class nonseqV2(torch.nn.Module):
def __init__(self):
super(nonseqV2,self).__init__()
self.fcLayer1=torch.nn.Linear(in_features=21, out_features=256)
self.fcLayer2=torch.nn.Linear(in_features=256, out_features=128)
self.fcLayer3=torch.nn.Linear(in_features=128, out_features=64)
self.fcLayer4=torch.nn.Linear(in_features=64, out_features=10)
self.relu=torch.nn.ReLU()
self.softmax=torch.nn.Softmax(dim=1)
def forward(self,x):
x=self.fcLayer1(x)
x=self.relu(x)
x=self.fcLayer2(x)
x=self.relu(x)
x=self.fcLayer3(x)
x=self.relu(x)
x=self.fcLayer4(x)
x=self.softmax(x)
return x
Keras compiling and training
model.compile(optimizer=Adam(0.0001),loss='categorical_crossentropy',metrics=['accuracy'])
model.fit(x=train_modeling,y=train_target_binary,batch_size=200,epochs=50,verbose=0,validation_data=(valid_modeling,valid_target_binary))
Pytoch training
for ep in range(50):
for xtb,ytb in train_loader:
xtb,ytb=xtb.cuda(),ytb.cuda()
tpred=model(xtb)
loss=crossentropy(tpred,ytb.long())
opt.zero_grad()
loss.backward()
opt.step()
Keras loss
log_loss(valid_target_binary,y_pred)
Pytorch Loss
log_loss(val_labels,yprd.detach().cpu().numpy())
As pytorch accept 1D label, so the variable names are different, but essentially they have same data.
This is how data feeded to keras is converted to pytorch tensor
val_features=torch.Tensor(valid_modeling)
val_labels=torch.Tensor(np.argmax(valid_target_binary,axis=1))
But loss obtained from Keras is 1.4 and PyTorch its 10.43. I know because of initilization factor, result should be bit different, but it should not be much different.