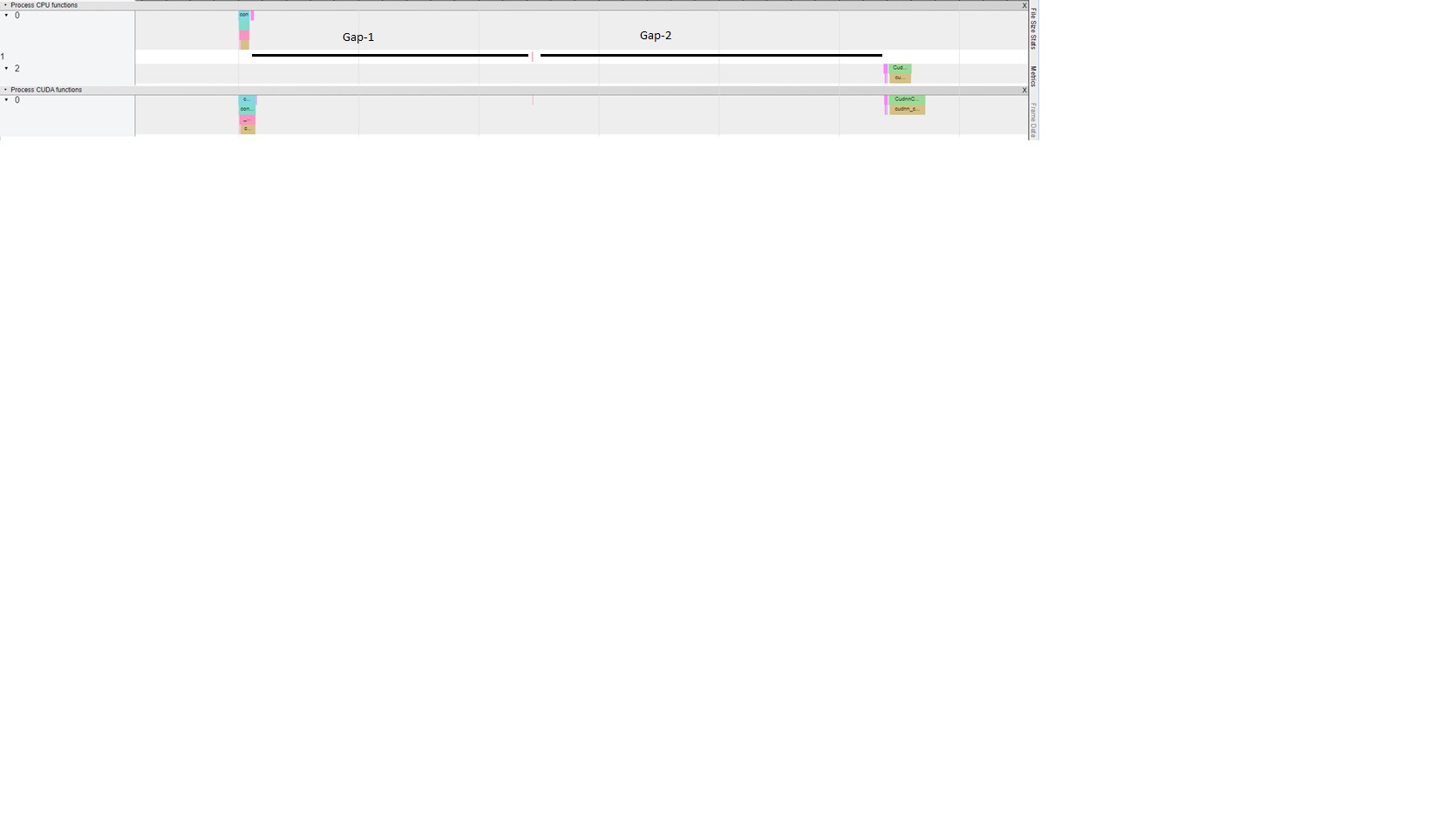
I am profiling forward and backward pass of convolution using the following code, and visualizing the profile using chrome://tracing.
I notice big gaps between forward and backward computations, before and after torch::autograd::GraphRoot, shown in the following picture.
Any ideas why these gaps are there?
import torch
import torch.nn.functional as F
import torch.autograd as Ag
Device = torch.device("cuda:0")
ProblemSize = 100
NumChannels = 5
NumFilters = 96
ClassTypeName = "Single"
ClassType = torch.float32
X = torch.rand(1, NumChannels, ProblemSize, ProblemSize, dtype=ClassType, requires_grad=True).to(Device)
weights = torch.rand(NumFilters, NumChannels, 10, 10, dtype=ClassType, requires_grad=True).to(Device)
#warm up
Y = F.conv2d(X, weights)
Ysum = torch.sum(Y)
grad = Ag.grad(Ysum, weights)
Y = F.conv2d(X, weights)
Ysum = torch.sum(Y)
grad = Ag.grad(Ysum, weights)
#profile
with torch.autograd.profiler.profile(use_cuda=True) as prof:
Y = F.conv2d(X, weights)
Ysum = torch.sum(Y)
grad = Ag.grad(Ysum, weights)
print(prof)
prof.export_chrome_trace("pytorch_profile_conv_grad.json")