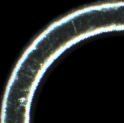
The ones above are two different paintings of mine that I’m trying to classify. I have 700 examples each. My classes are OK and NOK. The size of my pictures is 122x122, 140x140. When I train, I train as 144x144. I’ve been working on it for a long time. I tried many models and hyperparameters. Still I can’t get proper results. While my F1 score can reach 0.8 in the train section, it remains at 0.50 in the valid section. I cut a plate as a result of segmentation of my data. Since my data quality was low and noisy, I softened my image in this part as well.
My first question: If you were to show me some samples from your data,
say ten to one hundred each of OK and NOK, and give me a few words of
explanation about what made them different, how well would I be able to
do classifying your validation data set?
This is a simplistic, but very practical measure of how difficult you problem is.
Is there any correlation between your image sizes and whether an image
is OK or NOK? For example, are most of your OK images 122x122, while
most of your NOK images are 140x140?
How do you get your images with size 144x144? Do you upsample them?
Do you pad them?
If I understand you correctly, your model performs significantly better (although
not close to perfectly) on your training data set, but quite poorly on your
validation data set. This could be overfitting.
How big are your training and validation datasets?
You haven’t told us what your model looks like (or how long you’ve trained for),
but, depending on the architecture of your model, you could add to it techniques
like Dropout that are designed to reduce overfitting when training your model.
You could also use data augmentation as a way to semi-artificially increase the
size of your training dataset which again should reduce overfitting.
Also, just to check, do your training and validation datasets have the same
general character? A good way to insure that they’re statistically the same is
to take one large dataset and divide it randomly into a training and validation
datasets.
Softening your images might make sense, but you could take the attitude that
your network should itself “learn” to soften the images. You could argue that
even if softening makes the images look better to the eye, it could also obscure
some information that your network could use to classify the images.
For your first question: These pictures are a specific area of a metal plate. The black area between the 2 white circles may have scratches and dents. We classify them according to the size and depth of these scratches and dents. In the 1st picture, the white area in the bottom left is an example of an impact and we classify it as NOK. Sometimes I also have a hard time classifying OK or NOK because it can be difficult to decide the depth of the scratches. 90% of the time I can classify it.
For your second question: Because a part has a front and a back side and I crop this area as a result of segmentation, the dimensions can be different. Some of my parts are 124x123, 123x123, 160x161, 159x158 because the part on the back side is a bit smaller. This does not change for OK and NOK, in general it varies according to the front and back side and segmentation mask.
I use the function “img=cv2.resize(img,(144,144),interpolation=cv2.INTER_LINEAR)” to change the size.
For your third question: I have 600 OK and 600 NOK train yields. I have 60 OK and 60 NOK validation yields.
I used models such as resnet34, resnet50, densenet161 as models. The last layers of my model are as follows. For example
I use Adam or RmsProb algorithm, I use 0.1 as weight_decay and 0.00001 as learning rate. Batch_size is 2.
I only use gaussian noise as data augmentation.
I try to train up to 200 epochs but after a while my loss graphs show that it is overfit.
Finally, Training and validation sets have general properties
A quick summary: It does sound like you are seeing overfitting. Try more
data, augmented data, Dropout, pre-trained models, smaller models (if
they work for your use case), and SGD with momentum.
This sounds reasonable. It should be straightforward to build a classifier
that works on your use case (for some machine-learning definition of
“straightforward.”)
This is not an unreasonably small amount of data, but it’s not a lot. In general,
the best way to address overfitting is to get more training data if it is practical
to do so. (Of course it isn’t always.) A factor of ten more data – say 5000 to
10000 samples with ground-truth labels – could prove very helpful.
Pytorch’s resnet, say resnet34, consistent with the original resnet paper, does
not include Dropout, but you can add Dropout layers. (There is some debate
about whether Dropout works well with BatchNorm layers and where they
should be located relative to one another, but Dropout is, in general, a helpful
technique for reducing overfitting.)
Furthermore, if you’re not doing it already, you might try using a pre-trained
resnet model, and only fine tune the last few layers. Or you might first fine tune
the last few layers and then fine tune the whole model a little bit. The basic idea
is that the more (trainable) parameters a model has, the more likely it is to
overfit, so using the pre-trained parameter values as much as possible (which
know nothing about your data, so can’t already be overfitting it) could very well
help limit overfitting.
Because of the Sigmoid, I assume that you are using BCELoss. (If, not, that’s
a problem in and of itself.) This is unlikely to be your problem, but, for reasons
of numerical stability, you should get rid of the Sigmoid and use as your loss
criterion BCEWithLogitsLoss (which has logsigmoid() built into it).
There is some credible lore that Adam (as well as RMSprop) can be more
subject to overfitting than non-adaptive optimizers. Try using SGD (with
momentum).
Based on the images you posted, I assume that the white circular arcs in
your images are always in the same place. This would seem to limit the kinds
of data augmentation you could use – for example, RandomCrop would cause
the arcs to appear in somewhat different locations in your image, which might
not work for you.
However, it does look to me like you could reflect the images about the diagonal
that runs from the upper left to the lower right. That would only give you a factor
of two augmentation, but every little bit helps.
At the cost of interpolating pixel values (because pixels line up only for rotations
of 90 degrees), you might try augmenting by randomly rotating your plate images
around the center of the plate. (Whether the pixel-interpolation would hurt more
than the augmentation helps, I don’t know.)
Yes, but you would still want nonlinear “activations” (such as ReLU) between
your Linear layers.
That would be a reasonable thing to do. But having a learning-rate scheduler
doesn’t really have anything to do with overfitting – it just has the potential to
help with your training in other ways.
I would recommend trying to train for alternative output. Instead of binary out OK / NOK you should train to output rectangle which marks the biggest failure in the image. For the example images, the OK part should generate rectangle with coordinates (0,0),(0,0) and the NOK part should generate a rectangle around the segment of the image that causes the part to fail.
This would allow a practical way to see which kind of features your AI model finds for false positives or false negatives and checking for zeros in the output would be your final OK signal.
Trying to figure out why a binary model fails to output the expeted binary value is going to be really hard because you don’t have any clue about the detection quality.
And you could generate a lot more test cases by having slightly different coordinates for each failure case to train the model not to focus on individual pixels but overall area of the failure.
You could also train the model to output failure value (e.g. in range 0…1) for the failed detail (“how sure the AI model is about detecting failure”). Output 0 if the part is OK (that is , 1 if the part obviously fails and some value in between for borderline cases where even a human has hard time making the decision. That would further allow automating the output and separate parts that require further human decision but allow clear cases to be successfully marked automatically.