Hi Team,
I am new to Pytorch so this might be a silly question but hopefully someone can help, I have tried my best over the past few days to debug/educate myself more to try and resolve my problem but have been unable to.
Set up:
- I am building a variational auto encoder
- Data is just y values of some graph that has multiple Gaussians, there are 239 points.
- I have 45k of these “y data” arrays for training and 5k for testing
- I am preprocessing my data by removing outliers and applying a whitening transformation which uses the mean and std per dimension calculated on all 50k sets of data
VAE: I followed to blog post tutorial by Raviraja G
https://graviraja.github.io/vanillavae/
I am using these parameters
BATCH_SIZE = 64 # number of data points in each batch
N_EPOCHS = 20 # times to run the model on complete data
INPUT_DIM = 239 # size of each input
HIDDEN_DIM = 50 # hidden dimension
LATENT_DIM = 5 # latent vector dimension
lr = 1e-7 # learning rate
#import for generalisation, so data is fed in randomly
SHUFFLE = True
and this is how I have set up the encoder, decoder and VAE
class Encoder(nn.Module):
""" This the encoder part of VAE
"""
def __init__(self, input_dim, hidden_dim, z_dim):
super().__init__()
self.linear = nn.Linear(input_dim, hidden_dim)
self.mu = nn.Linear(hidden_dim, z_dim)
self.var = nn.Linear(hidden_dim, z_dim)
def forward(self, x):
# x is of shape [batch_size, input_dim]
hidden = F.relu(self.linear(x))
# hidden is of shape [batch_size, hidden_dim]
z_mu = self.mu(hidden)
# z_mu is of shape [batch_size, latent_dim]
z_var = self.var(hidden)
# z_var is of shape [batch_size, latent_dim]
return z_mu, z_var
class Decoder(nn.Module):
""" This the decoder part of VAE
"""
def __init__(self, z_dim, hidden_dim, output_dim):
super().__init__()
self.linear = nn.Linear(z_dim, hidden_dim)
self.out = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
# x is of shape [batch_size, latent_dim]
hidden = F.relu(self.linear(x))
# hidden is of shape [batch_size, hidden_dim]
predicted = torch.sigmoid(self.out(hidden))
# predicted is of shape [batch_size, output_dim]
return predicted
class VAE(nn.Module):
""" This is the VAE, which takes a encoder and decoder.
"""
def __init__(self, enc, dec):
super().__init__()
self.enc = enc
self.dec = dec
def forward(self, x):
# encode
z_mu, z_var = self.enc(x)
# sample from the distribution having latent parameters z_mu, z_var
# reparameterize
std = torch.exp(z_var / 2)
eps = torch.randn_like(std)
x_sample = eps.mul(std).add_(z_mu)
# decode
predicted = self.dec(x_sample)
return predicted, z_mu, z_var
And I am running training and testing the following way.
def train(model):
# set the train mode
model.train()
# loss of the epoch
train_loss = 0
for i, (x,n,f) in enumerate(train_iterator):
# reshape the data into [batch_size, 784]
x = x.view(-1, 239)
x = x.to(device)
# update the gradients to zero
optimizer.zero_grad()
# forward pass
x_sample, z_mu, z_var = model(x.float())
#reconstruction loss
try:
recon_loss = F.binary_cross_entropy(x_sample, x.float(), size_average=False)
except:
print(x)
print(np.min(x.numpy()), np.max(x.numpy()), np.min(x.numpy()), np.max(x.numpy()))
print(f[i])
# kl divergence loss
kl_loss = 0.5 * torch.sum(torch.exp(z_var) + z_mu**2 - 1.0 - z_var)
# total loss
loss = recon_loss + kl_loss
# backward pass
loss.backward()
train_loss += loss.item()
# update the weights
optimizer.step()
return train_loss
def test(model):
# set the evaluation mode
model.eval()
# test loss for the data
test_loss = 0
# we don't need to track the gradients, since we are not updating the parameters during evaluation / testing
with torch.no_grad():
for i, (x,n,f) in enumerate(test_iterator):
# reshape the data
x = x.view(-1, 239)
x = x.to(device)
# forward pass
x_sample, z_mu, z_var = model(x.float())
#reconstruction loss
try:
recon_loss = F.binary_cross_entropy(x_sample, x.float(), size_average=False)
except:
print(x)
print(np.min(x.numpy()), np.max(x.numpy()), np.min(x.numpy()), np.max(x.numpy()))
print(f[i])
# kl divergence loss
kl_loss = 0.5 * torch.sum(torch.exp(z_var) + z_mu**2 - 1.0 - z_var)
# total loss
loss = recon_loss + kl_loss
test_loss += loss.item()
return test_loss
train_ll = []
test_ll = []
best_test_loss = float('inf')
for e in range(N_EPOCHS):
train_loss = train(model)
test_loss = test(model)
train_loss /= len(train_dataset)
test_loss /= len(test_dataset)
print(f'Epoch {e}, Train Loss: {train_loss:.2f}, Test Loss: {test_loss:.2f}')
train_ll.append(train_loss)
test_ll.append(test_loss)
if best_test_loss > test_loss:
best_test_loss = test_loss
patience_counter = 1
else:
patience_counter += 1
if patience_counter > 3:
break
THE PROBLEM:
During the training/testing stage my F.Binary cross entropy fails as it says the values need to be between 0,1. This is where things get odd. before feeding my data into the VAE it appears to be scaled correctly. The target and input values for the BCE are usually between [-1, 3] and occasionally have a large or small value |3000| somewhere in that tensor.
Occasionally it does train without failing, sometimes it fails. When it does not fail the loss does not really get better but the VAE kind of works?
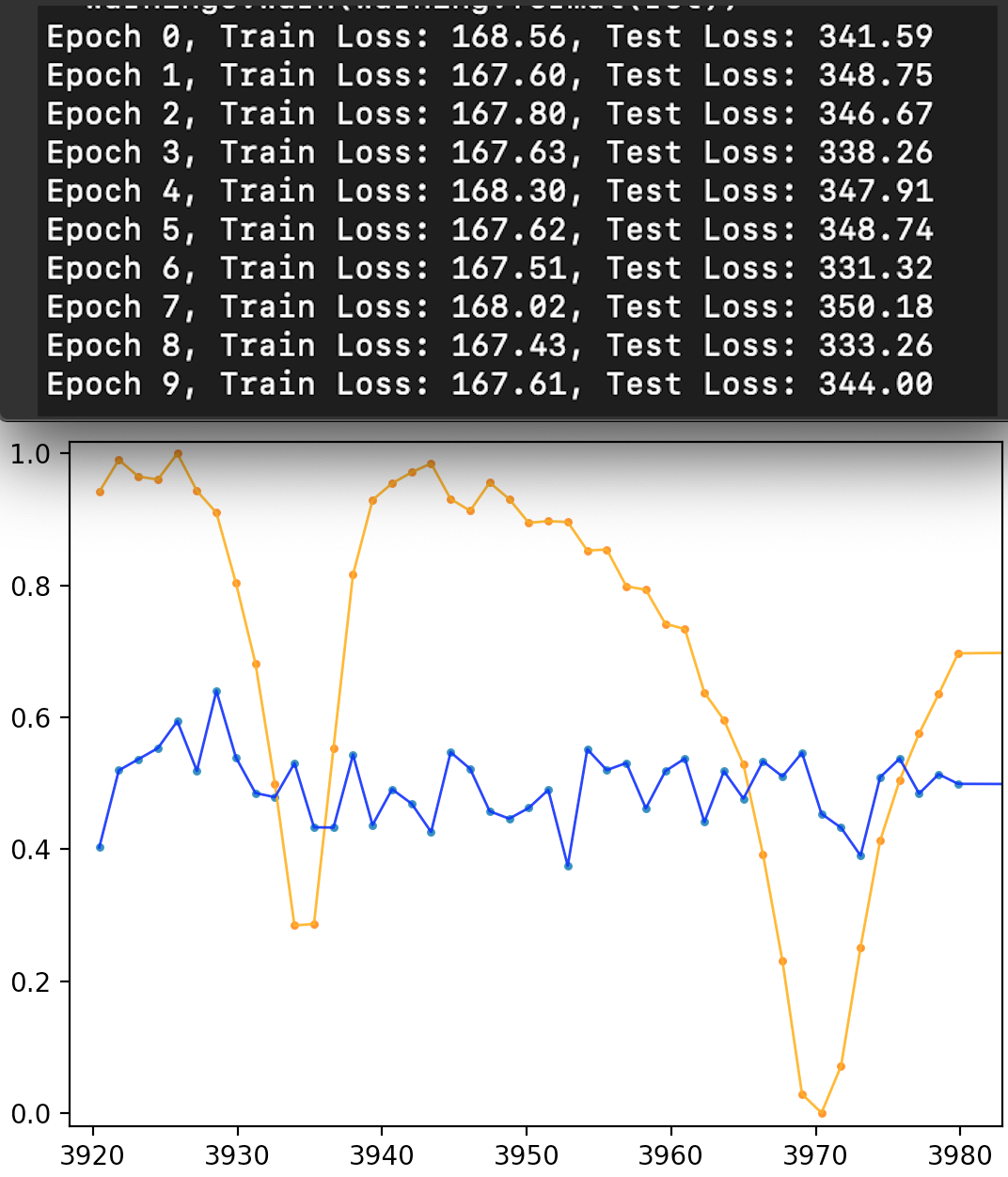
And here are the results, blue line is the original data and yellow is output of the same data through the VAE.
Questions:
- I am unsure if the way I have set up the VAE is the best way to do this problem, WHat are some other things I could change/test?
- Why would the BCE fail only sometimes when nothing has been changed?
- The error I get sometimes from BCE, What are some things I could do to check/debug what could be creating that.
- How do I improve the VAE? should I bump up the epochs or something else? I am unsure how to interpret the Loss results.
Any suggestions or thought would be greatly appreciated. thank you ![]()

