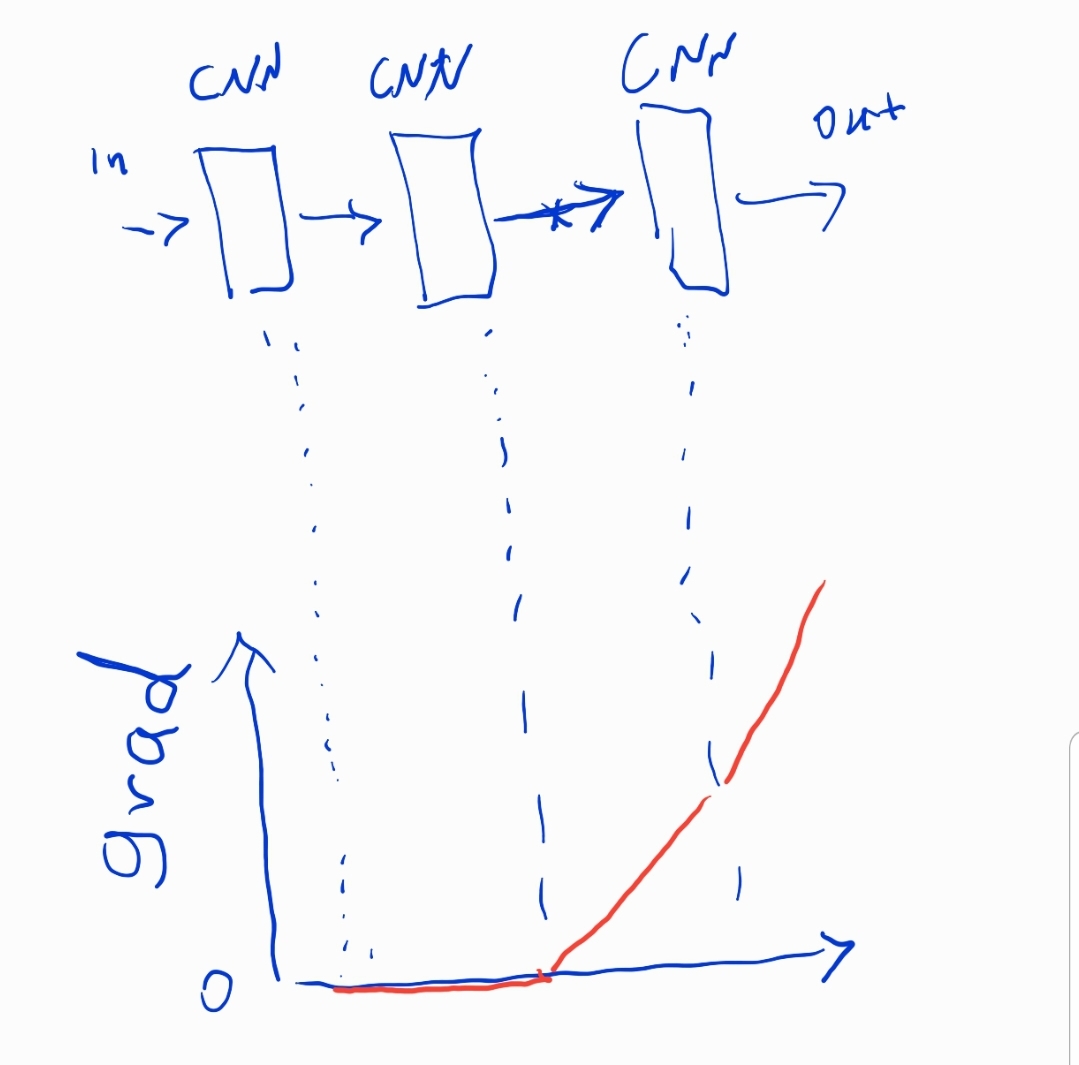
I wanted to creat an architecture that gradient flow is blocked from a certain layer beckward and the former layer will not update. I don’t want freeze that part. I want to put gradient of the intended layer be zero and block the gradient flow somehow the former layer will not be updated in this path. Is there any solution? I tried to put the grad of the intended output’s layer to be zero manually in the forward path of the model but I still have the gradient values for the layers before that.
If you know during the forward which part you want to block the gradients from, you can use .detach() on the output of this block to exclude it from the backward.
If you only know after the forward which part you want to block, you will need to add a hook to the Tensor that is the output of your block as:
Please could you explain what you mean by this? If I am implementing my own optimiser, how else should my optimiser modify the underlying data of a tensor, without modifying the data attribute of that tensor?
Using .data bypasses certain checks around mutations which can lead to incorrect gradients
If you are building your own optimizer you can modify the parameters in-place (e.g., torch.add_) in no-grad mode (this is also how optim writes their optimizers)