Hi!
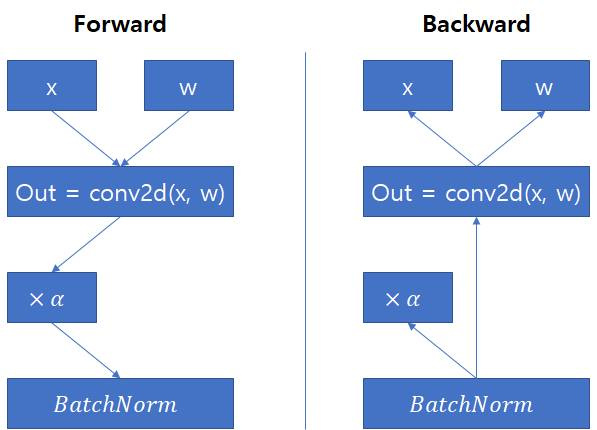
Is it possible implement model with backward path in attached image?
I have an alpha layer which multiply ‘alpha (trainable parameter)’.
In backward path, alpha layer doesn’t transfer gradient to convolution layer.
Instead, gradient calculated by BatchNorm layer feed gradient to convolution layer directly.
Is there any solutions?
Thanks ![]()