Hi,
I’m wondering if there is a way to block gradients along a certain pathway without completely detaching a tensor from the graph.
Say I have this setup where I have a model which computes a feature F and has two classification heads A and B. A is the “main” head and I want gradients from A to flow through the model normally. B is an auxiliary head and I want it to behave as if the rest of the model is frozen, so it learns to to classify something based off the values of F without affecting the training of the rest of the model.
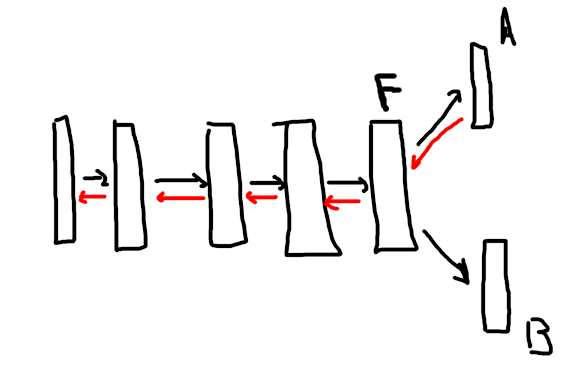
I’m not sure how to do this with detach. My understanding is that if I detach B, it just wont learn anything, but in my case I want it to learn but not to affect the rest of the model.
Thanks