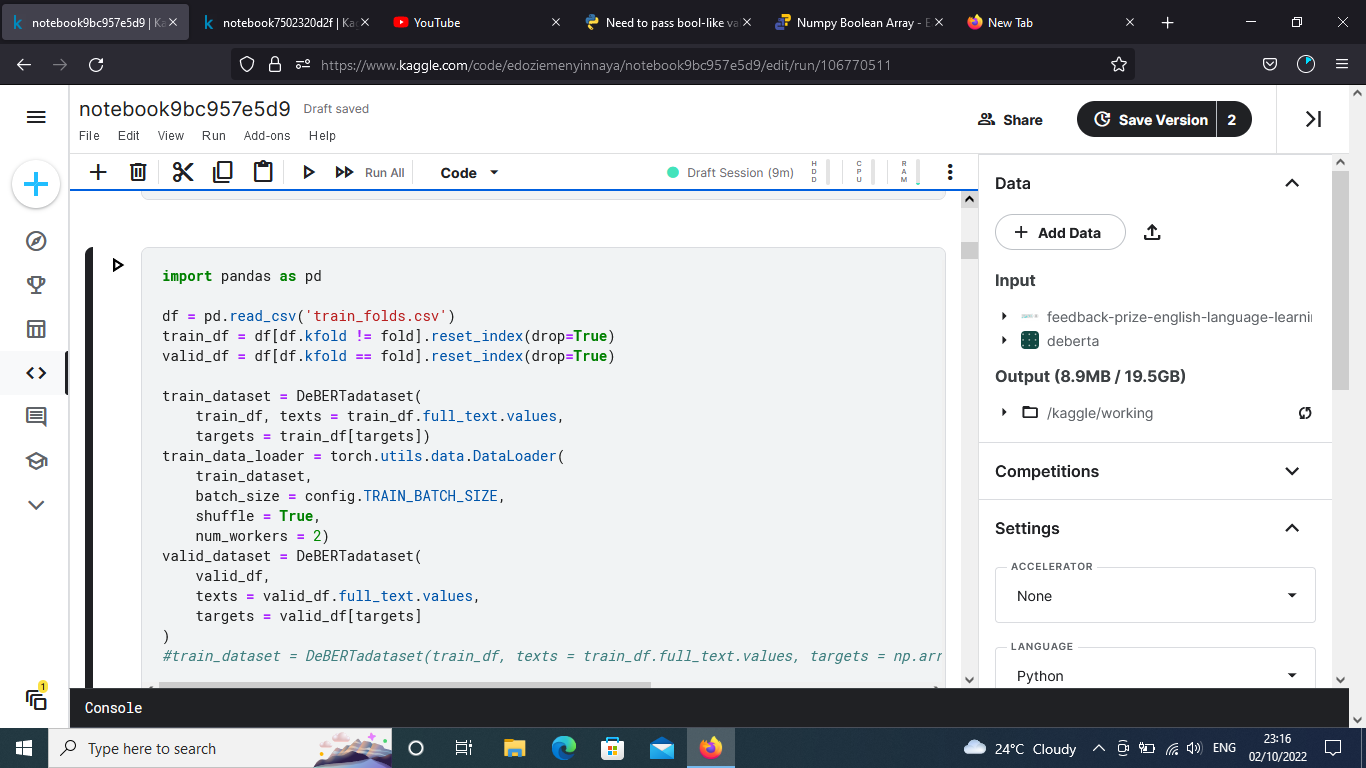
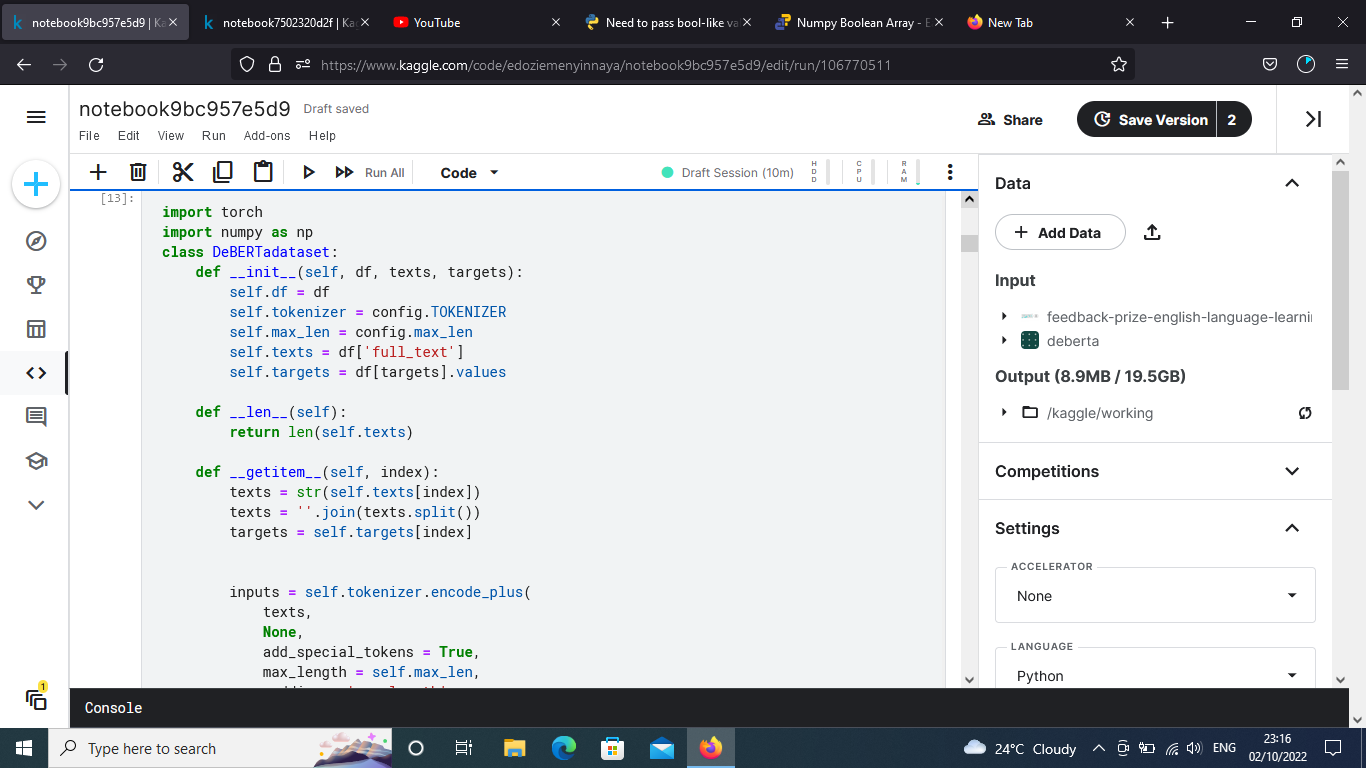
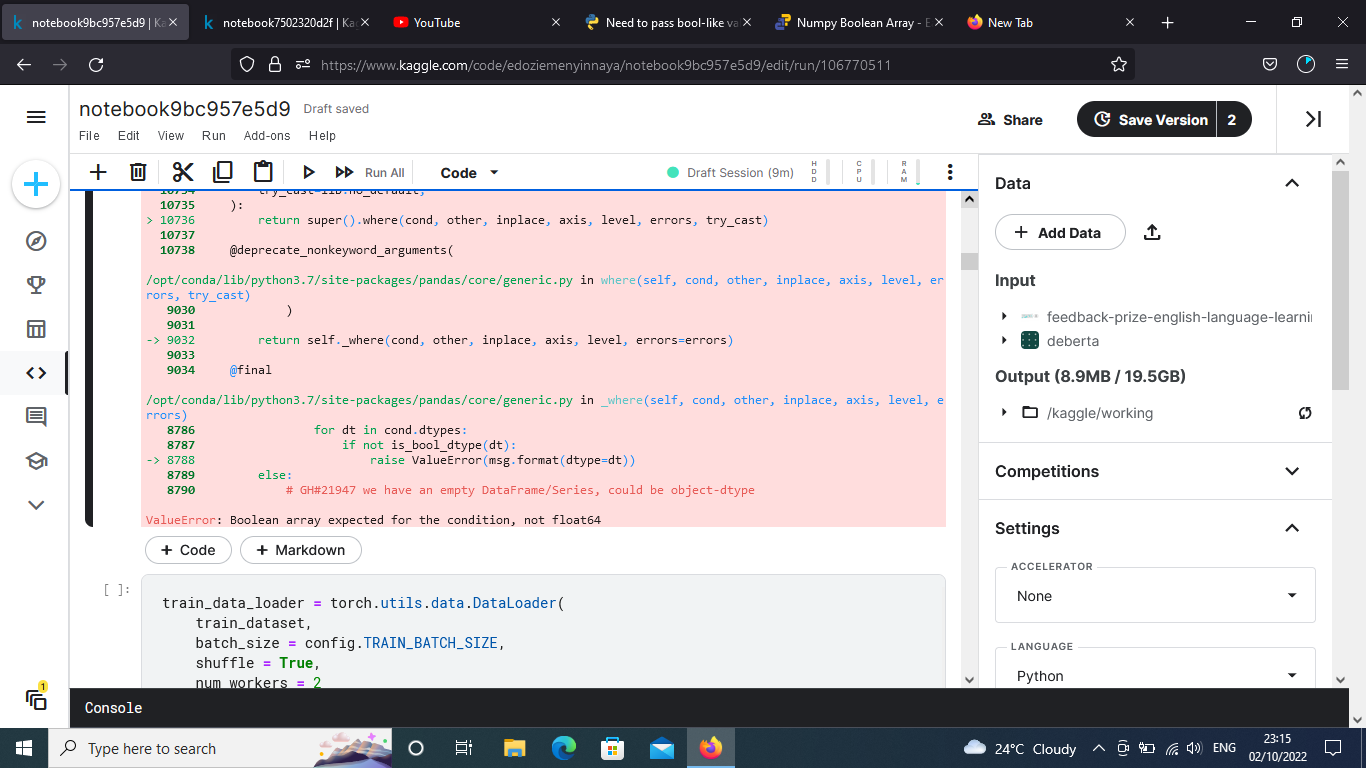
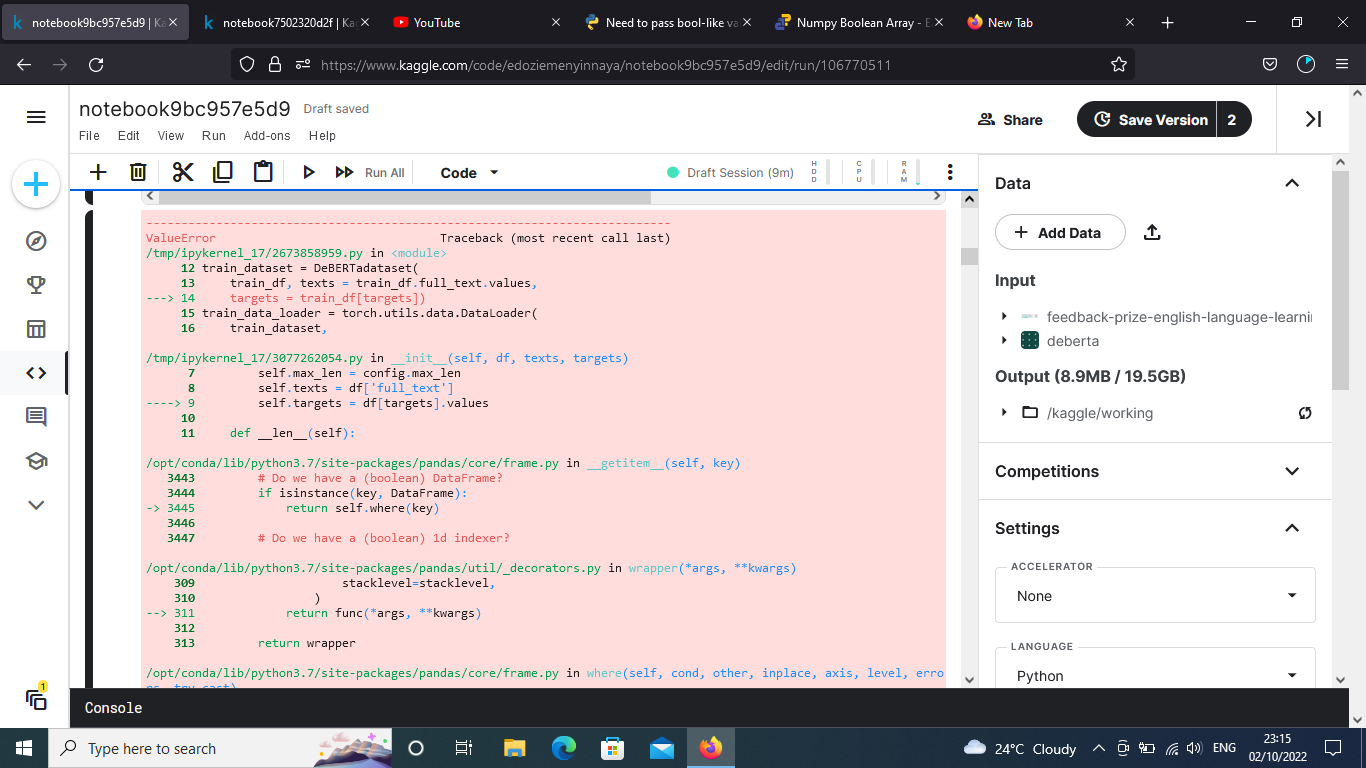
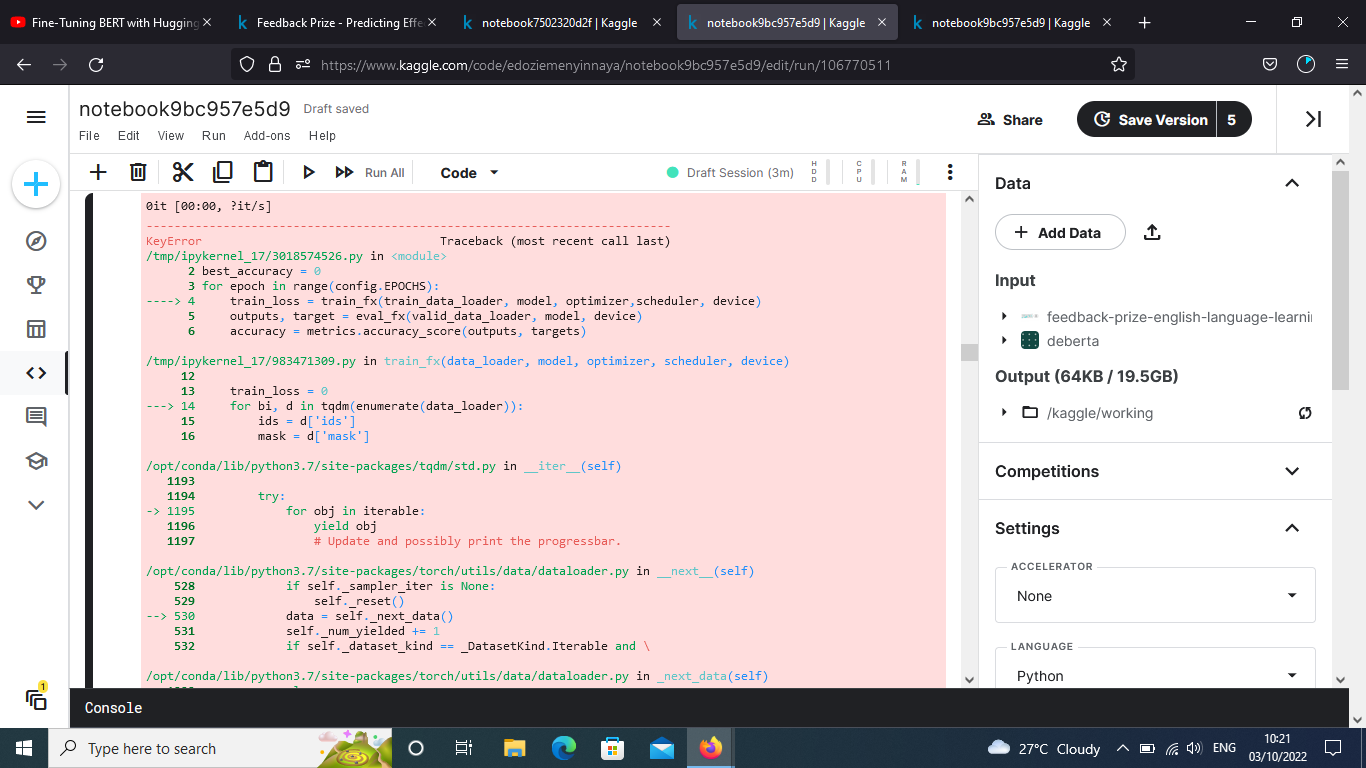
I got this error when dealing with multiple targets in multioutput classification problem.
I don’t know if I need to turn it to Boolean first for the targets=train_df[targets]?
I got this error when dealing with multiple targets in multioutput classification problem.
I’m not sure which line of code is rasing the error but it seems you might have narrowed it down to the indexing of the pandas.DataFrame? Are you trying to pass floating point values as the index to it?
This line targets=train_df[targets].values is the problem, since I tried passing in float numbers from the dataframe as targets which contains 6 target variables of all float numbers, so calling “ targets=train_df[targets].values ” gave the error?
Based on your screenshot it is indeed an error in the indexing of the pandas.DataFrame, so make sure you are passing valid indices to it.
PS: you can post code snippets by wrapping them into three backticks ``` instead of screenshots which generally makes debugging easier.
If you get stuck, feel free to post a minimal, executable code snippet which would reproduce the error.
import torch
import torch.nn as nn
class BertDataset:
def init(self, df, texts, targets):
self.df = df
self.targets = df[‘targets’]
self.max_len = config.max_len
self.texts = df[‘full_text’]
self.tokenizer = config.TOKENIZER
def __len__(self):
return len(self.texts)
def __getitem__(self, index):
texts = ' '.join(str(self.texts[index]).split())
inputs = self.tokenizer.encode(
texts,
None,
max_length = self.max_len,
padding = 'max_length',
truncation = True,
add_special_tokens = True
)
resp = {
'ids': torch.tensor(inputs['input_ids'], dtype=torch.long),
'mask': torch.tensor(inputs['attention_mask'], dtype=torch.long),
'token_type_ids': torch.tensor(inputs['token_type_ids'], dtype=torch.long),
'target': torch.tensor(self.targets[index], dtype=torch.long)
}
return resp
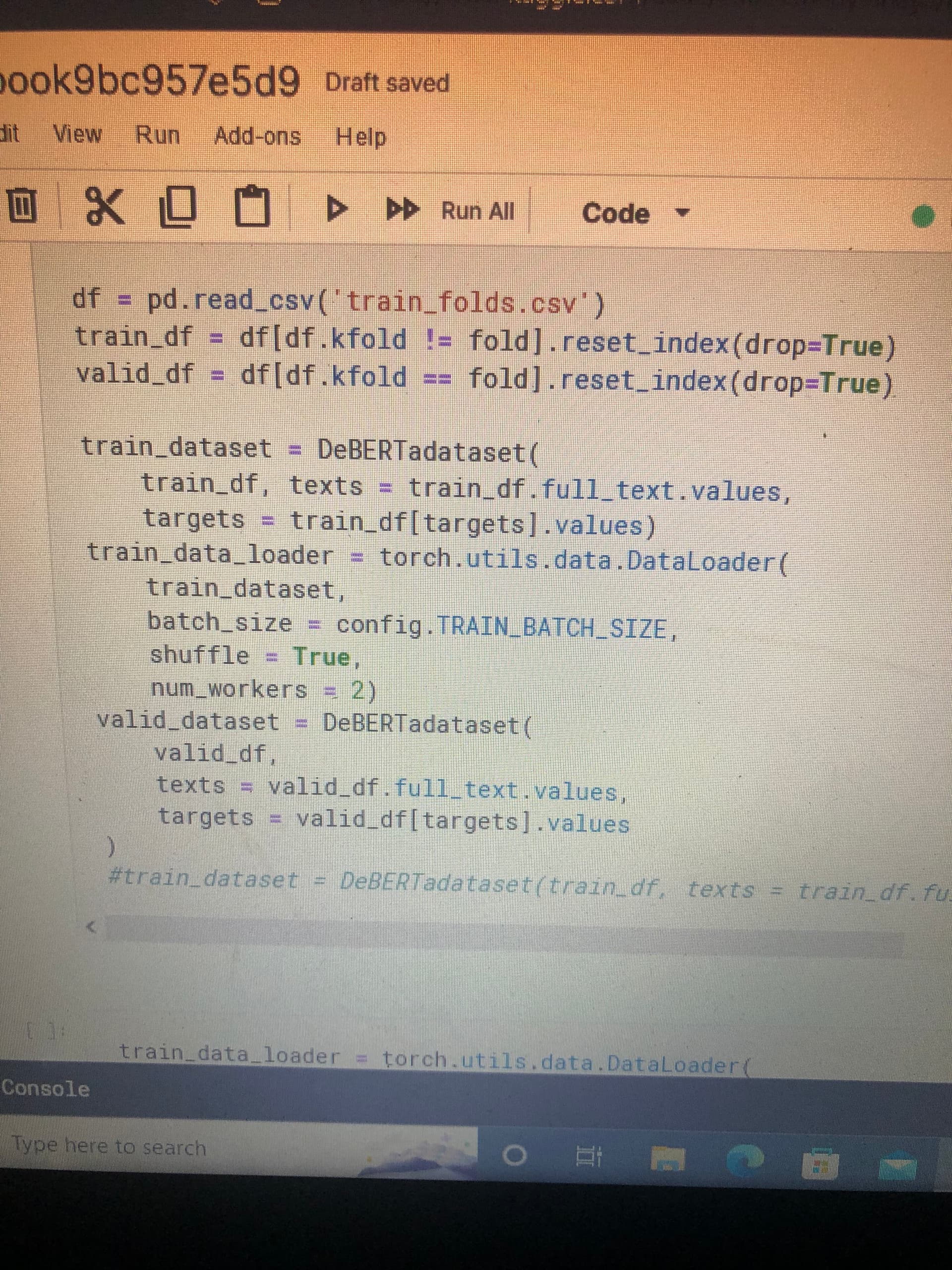
I passed in the correct index in the dataframe and it’s still giving issues? It says none of the index are in the column?
Your code is not executable so I cannot debug it, but your error seems to be pandas-specific and unrelated to PyTorch. If you could create a minimal and executable code snippet which we could copy/paste to debug, I’m happy to help. Otherwise, I can only refer to the pandas docs to check how DataFrames should be indexed.
import pandas as pd
df = pd.read_csv(‘train_folds.csv’)
train_df = df[df.kfold != fold].reset_index(drop=True)
valid_df = df[df.kfold == fold].reset_index(drop=True)
train_dataset = DeBERTadataset(
train_df, texts = train_df.full_text.values,
target = train_df.loc[:, targets].values)
train_data_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size = config.TRAIN_BATCH_SIZE,
shuffle = True,
num_workers = 2)
valid_dataset = DeBERTadataset(
valid_df,
texts = valid_df.full_text.values,
target = valid_df.loc[:, targets].values
)
valid_data_loader = torch.utils.data.DataLoader(
valid_dataset,
batch_size = config.VALID_BATCH_SIZE,
shuffle = False,
num_workers = 1
)
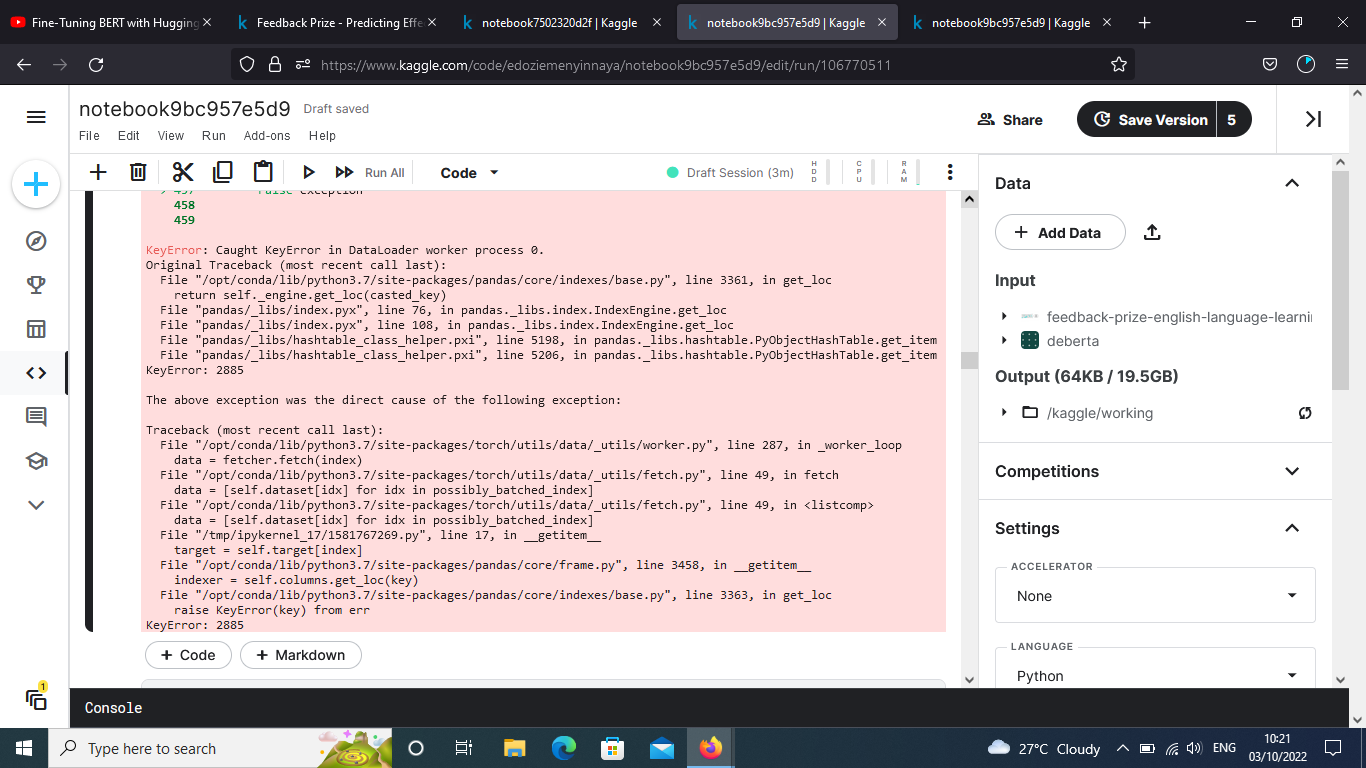
The new error now points to an invalid key value (the type is correct this time).
I don’t really know where it’s coming from but I feel it might be from the dataset class?
Maybe the getitem function?
No, it’s the indexing in the pandas.DataFrame again and unrelated to PyTorch:
df = pd.DataFrame({'a': np.random.randn(10)})
df[2885]
# KeyError: 2885
I guess I didn’t specify the targets columns in the df=pd.read_csv(input, column=targets), since i placed in targets to be targets = [‘cohesion’, ‘syntax’, ‘vocabulary’, ‘phraseology’, ‘grammar’, ‘conventions’]………
But I don’t know if it will work fine?