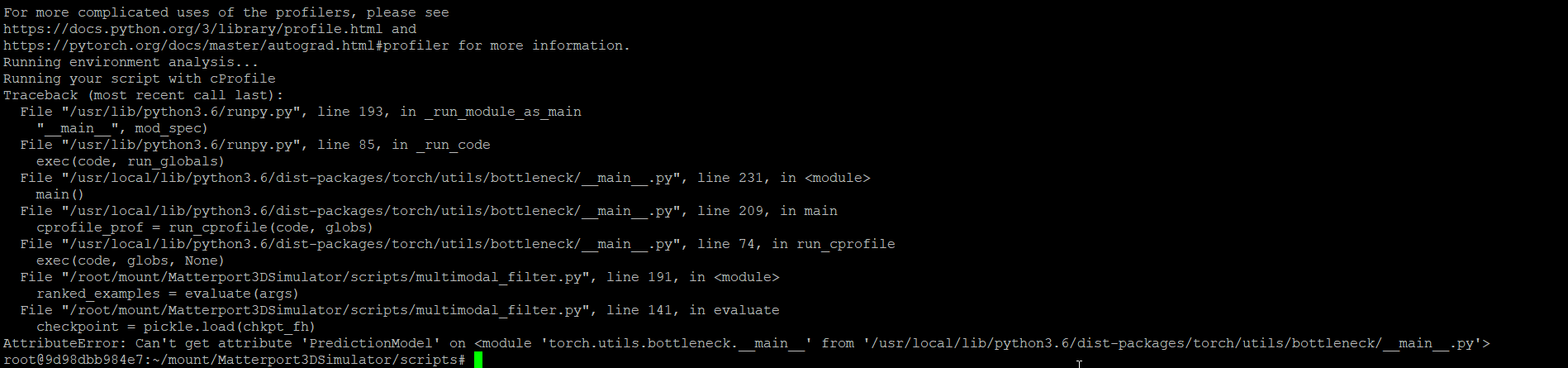
I’m trying to profile code using the bottleneck util. Running CUDA_VISIBLE_DEVICES=2 python3 -m torch.utils.bottleneck /root/mount/Matterport3DSimulator/scripts/multimodal_filter.py --mode eval --batch_size 3000 --checkpoint best_model.pt, gives the following error:
The class its referring to is a class declared in the multimodal_filter script. That script works with no issues.
I’m using docker (nvidia-docker), PyTorch 1.4.0, Cuda compilation tools, release 10.0 (I’m assuming this is the cuda version).
Did you store the complete model or its state_dict?
The latter case is recommended, but I haven’t seen this particular issue with the former approach yet, so not sure, if this might cause the error.
1 Like
The model is copied using deepcopy, stored in a dictionary with other information required to run the model, and pickled (Code below). I’ll try using the state_dict instead of storing the entire, see if that fixes the issue.
Out of curiosity, why is saving only the state_dict recommend?
Here is storage part of the code:
if best_test_acc <= (test_correct/test_total):
print("Best model saved")
bestModel = deepcopy(model)
best_test_acc = (test_correct/test_total)
checkpoint_data = {
"vocab": vocab,
"model" : bestModel,
"processor" : processor,
"test_acc" : best_test_acc
}
return checkpoint_data
Here is the pickling, the code above returns the variable checkpoint.
checkpoint = train(args)
with open(args.checkpoint, 'wb+') as pk_fh:
pickle.dump(checkpoint, pk_fh)
If you store the complete model and would like to reload it, you would have to make sure to recreate the directory structure as described in the serialization docs and might thus easily break.
Serialization of the entire model was the issue. Thanks for your help!