So I’m currently trying to implement this model:
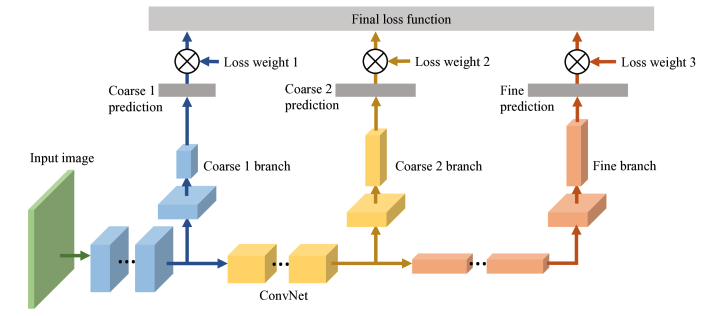
The authors use a VGG16 BN pretrained model and add in three FC branches, which I think I’ve done in this:
class BCNN(nn.Module):
def __init__(self):
super(BCNN,self).__init__()
# Load pretrained model
vgg_model = models.vgg16_bn(pretrained=True)
self.Conv1 = nn.Sequential(*list(vgg_model.features.children())[0:7])
self.Conv2 = nn.Sequential(*list(vgg_model.features.children())[7:14])
# Level-1 classifier after second conv block
self.level_one_clf = nn.Sequential(nn.Linear(128*56*56, 256),
nn.ReLU(),
nn.BatchNorm1d(256),
nn.Dropout(0.5),
nn.Linear(256, 256),
nn.BatchNorm1d(256),
nn.Dropout(0.5),
nn.Linear(256, 2))
self.Conv3 = nn.Sequential(*list(vgg_model.features.children())[14:24])
# Level-2 classifier after third conv block
self.level_two_clf = nn.Sequential(nn.Linear(256*28*28, 1024),
nn.ReLU(),
nn.BatchNorm1d(1024),
nn.Dropout(0.5),
nn.Linear(1024, 1024),
nn.BatchNorm1d(1024),
nn.Dropout(0.5),
nn.Linear(1024, 7))
self.Conv4 = nn.Sequential(*list(vgg_model.features.children())[24:34])
self.Conv5 = nn.Sequential(*list(vgg_model.features.children())[34:44])
# Level-3 classifier after fifth conv block
self.level_three_clf = nn.Sequential(nn.Linear(512*7*7, 4096),
nn.ReLU(),
nn.BatchNorm1d(4096),
nn.Dropout(0.5),
nn.Linear(4096, 4096),
nn.BatchNorm1d(4096),
nn.Dropout(0.5),
nn.Linear(4096, 25))
def forward(self,x):
x = self.Conv1(x)
x = self.Conv2(x)
lvl_one = x.view(x.size(0), -1)
lvl_one = self.level_one_clf(lvl_one)
x = self.Conv3(x)
lvl_two = x.view(x.size(0), -1)
lvl_two = self.level_two_clf(lvl_two)
x = self.Conv4(x)
x = self.Conv5(x)
lvl_three = x.view(x.size(0), -1)
lvl_three = self.level_three_clf(lvl_three)
return lvl_one, lvl_two, lvl_three
The actual training I’m a bit more uncertain about – especially if I’m implementing the losses correctly. If I understand it, there’s 1 loss function that is made up of the 3 losses from each FC branch. Also, the weights for each loss are changed depending on the epoch. The entire training loop looks like so:
def train_model(model, dataloader, criterion, optimizer, save_path_loss, save_path_acc, num_epochs=25):
for epoch in range(num_epochs):
#Custom learning rate scheduler
if epoch > 53:
optimizer = scheduler(optimizer, epoch)
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
model.eval() # Set model to evaluate mode
running_loss = 0.0
l1_running_corrects = 0
l2_running_corrects = 0
l3_running_corrects = 0
# # Iterate over data.
for inputs, y1, y2, y3 in dataloader[phase]:
inputs = inputs.to(device)
l1_label = y1.to(device)
l2_label = y2.to(device)
l3_label = y3.to(device)
optimizer.zero_grad()
l1_out, l2_out, l3_out = model(inputs)
with torch.set_grad_enabled(phase == 'train'):
loss = losses(l1_out, l1_label,
l2_out, l2_label,
l3_out, l3_label,
criterion, epoch)
running_loss += loss.item() * inputs.size(0)
l1_batch_corrects, \
l2_batch_corrects, \
l3_batch_corrects = batch_accs(l1_out, l1_label,
l2_out, l2_label,
l3_out, l3_label)
l1_running_corrects += l1_batch_corrects
l2_running_corrects += l2_batch_corrects
l3_running_corrects += l3_batch_corrects
if phase == 'train':
loss.backward()
optimizer.step()
epoch_loss = running_loss / len(dataloader[phase].dataset)
l1_epoch_acc = l1_running_corrects.double() / len(dataloader[phase].dataset)
l2_epoch_acc = l2_running_corrects.double() / len(dataloader[phase].dataset)
l3_epoch_acc = l3_running_corrects.double() / len(dataloader[phase].dataset)
print('{} Loss: {:.4f}\nLevel-1 Acc: {:.4f}\nLevel-2 Acc: {:.4f}\nLevel-3 Acc: {:.4f}'.format(phase,
epoch_loss,
l1_epoch_acc,
l2_epoch_acc,
l3_epoch_acc)
return model
The function that calculates the losses is:
def losses(l1_out, l1_label, l2_out, l2_label, l3_out, l3_label, criterion, epoch):
l1_loss = criterion(l1_out, l1_label)
l2_loss = criterion(l2_out, l2_label)
l3_loss = criterion(l3_out, l3_label)
if epoch <= 12:
total_loss = 0.98 * l1_loss + 0.01 * l2_loss + 0.01 * l3_loss
if epoch > 12 and epoch <= 22:
total_loss = 0.1 * l1_loss + 0.8 * l2_loss + 0.1 * l3_loss
if epoch > 22 and epoch <= 32:
total_loss = 0.1 * l1_loss + 0.2 * l2_loss + 0.7 * l3_loss
if epoch > 32:
total_loss = l3_loss
return total_loss
And accuracies, in case I have something glaringly wrong here:
def batch_accs(l1_out, l1_label, l1_running_corrects,
l2_out, l2_label, l2_running_corrects,
l3_out, l3_label, l3_running_corrects):
l1_pred = torch.argmax(l1_out, dim=1)
l2_pred = torch.argmax(l2_out, dim=1)
l3_pred = torch.argmax(l3_out, dim=1)
l1_running_corrects += torch.sum(l1_pred == l1_label)
l2_running_corrects += torch.sum(l2_pred == l2_label)
l3_running_corrects += torch.sum(l3_pred == l3_label)
return l1_running_corrects, l2_running_corrects, l3_running_corrects
I’m mainly concerned if I am implementing the losses correctly. For example, I read that it’s okay to sum separate losses and call .backward(), but I’m not 100% certain that I should do that rather than 3 separate losses and backwards.
Any feedback would be greatly appreciated!