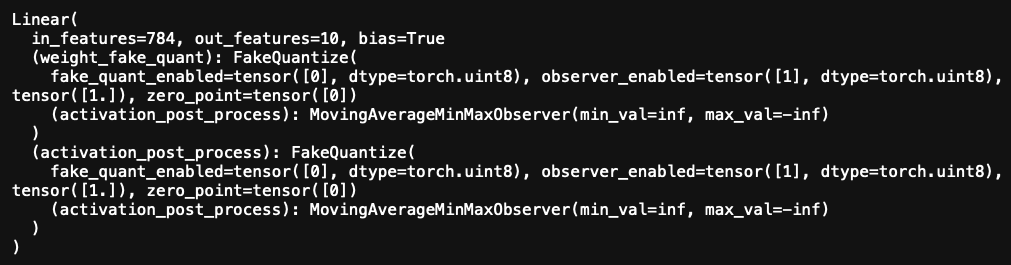
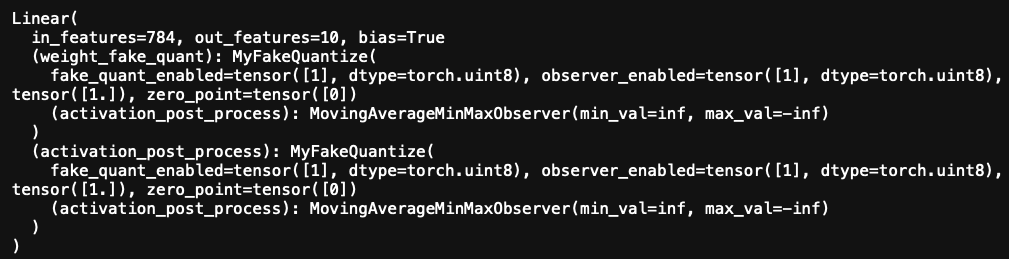
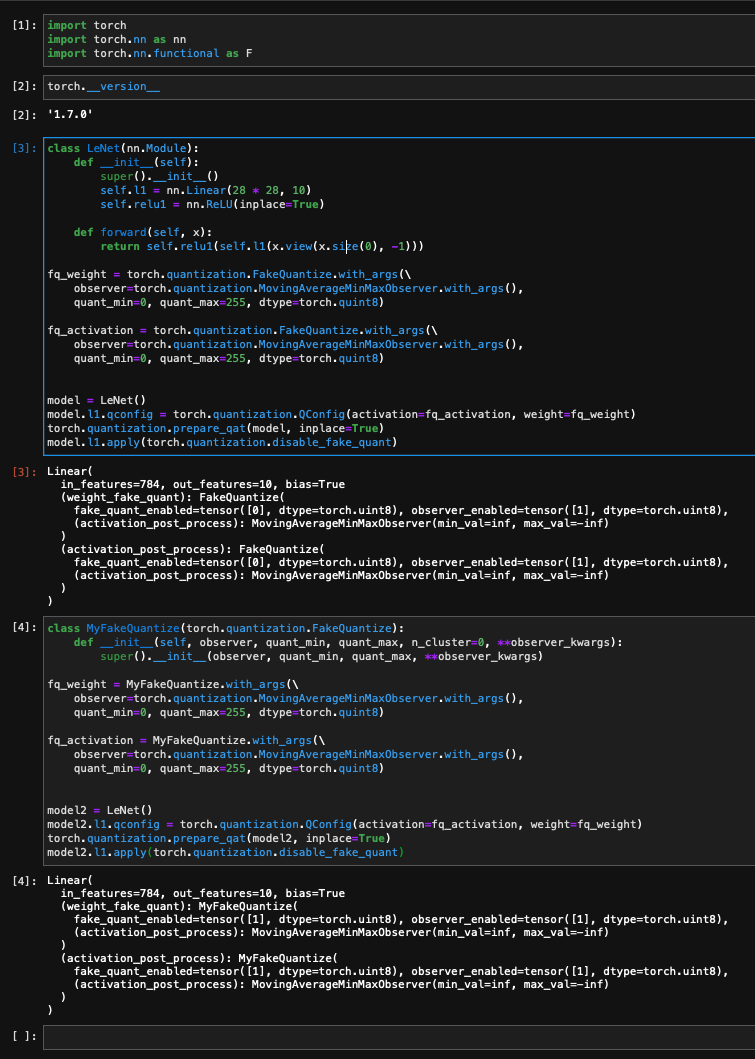
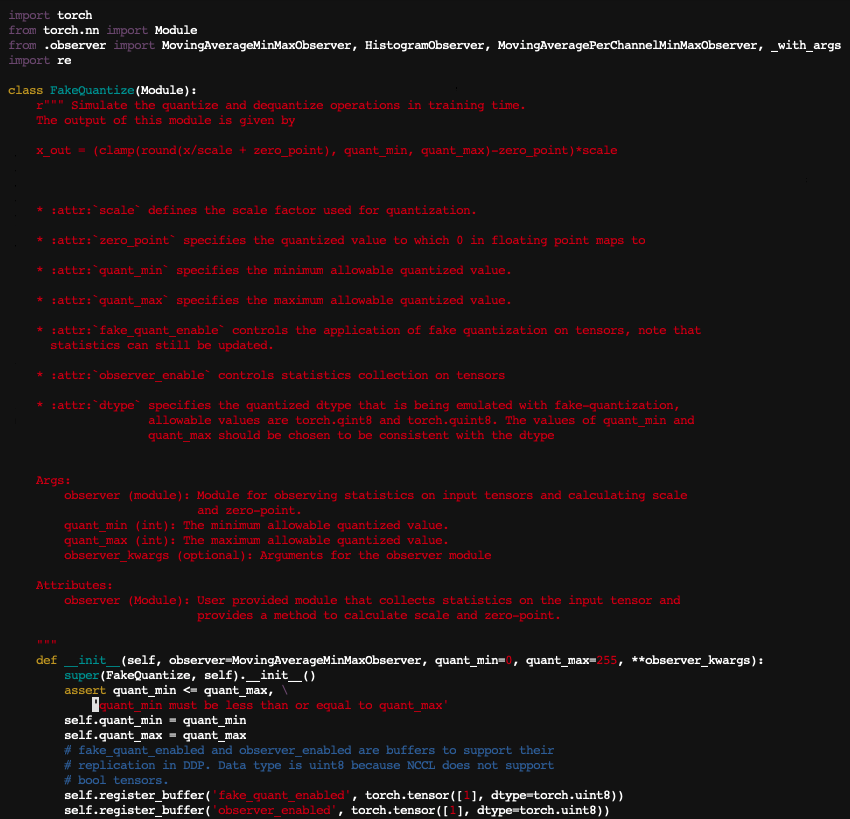
hi @thyeros, I cannot reproduce this on master. Could you check if you reproduce this on v1.7 or master? Which version did you originally see the issue on?
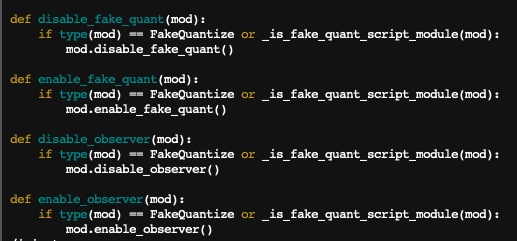
hi @thyeros, unfortunately we cannot repro this on master and this is not a known KP. Could you try the debug script in gist:61ac9744858509e175d4ce50258782e4 · GitHub and narrow down which exact part of disable_fake_quant is not working in your environment? In the debug script, I just copied the disable_fake_quant definition so it’s easy to debug.
First of all, thanks for the help in this matter. Really appreciated. The code from you doesn’t work out of the box, as FakeQuantizeBase is not available.
Since I know that FakeQuantize is based on FakeQuantizeBase, it looks strange to me as well, hence I checked out the torch/quantization/fake_quantize.py and found out that the pytorch 1.7.0 in my image doesn’t have FakeQuantizeBase and has very different implementations for disable/enable_quant/observer.
Thanks for the additional info. Looks like what you are describing was not supported, and added recently with https://github.com/pytorch/pytorch/pull/48072. Before that PR, the type(mod) == FakeQuantize check would not pass for custom fake quant classes. It should pass now. Could you try updating your PyTorch installation and see if it works with 1.7.1 or master?
Looking at Releases · pytorch/pytorch · GitHub, it doesn’t look like this PR was in 1.7.1. So, you could try master. Or, you could write your own function which disables fake_quants (for example, by copying the code after the PR above) and call that, without having to update your PyTorch installation.
Thanks Vasiliy for double confirming the latest PR. I will perhaps live with a custom implementation for now (like yours) wait for the official release. Thanks again!