I get broken pipeline error when num of workers > 0 in the dataloader. I did look at various solutions (which worked for multiple people) that suggested the code snippet as shown below:
def run():
# actual code
if __name__ = '__main__':
run()
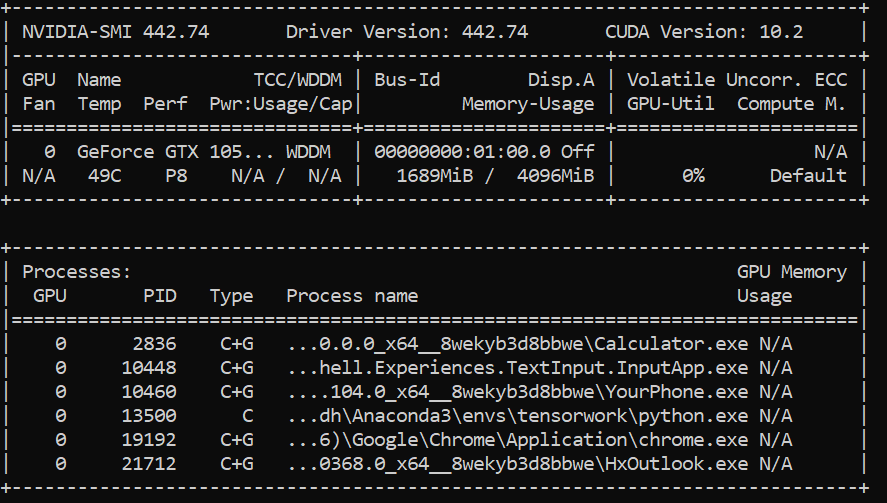
However, this does not seem to work for me. I have a PyTorch version of 1.0.0 , python version of 3.6.8 running on Windows 10 and my GPU details are shown below.
I am using Jupyter notebook to simulate this. Here is the minimal reproducible example. Since my input and ouput are of the shape [1700, 402] and [1700,] I used the similar size here.
import torch
import numpy
from torch.utils.data import Dataset, DataLoader
import pdb
# dataset class
class data(Dataset):
def __init__(self, x, y):
self.x = x
self.y = y
self.len = self.x.shape[0]
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
def __len__(self):
return self.len
if __name__ == "__main__":
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
x = numpy.random.rand(1700,402)
y = numpy.random.rand(1700)
dataset = data(torch.Tensor(x),torch.Tensor(y))
print('the length of the dataset = ', len(dataset))
print ('before loader')
data_loader = DataLoader(dataset, batch_size = 50, shuffle = True, pin_memory=True, num_workers = 1)
print ('after loader')
for idxs, (xx, yy) in enumerate(data_loader):
xx, yy = xx.to(device), yy.to(device)
print ('idx: {} x: {} y: {}'.format(idxs, xx, yy))
This time, the error is not shown however, the notebook gets stuck without displaying anything . It does print ‘after loader’ after which it gets stuck until I restart the kernel. It works perfectly fine if I set num_workers = 0.
Note: the brokern pipe error is still consistent with my original case.
Thank you for your response. The workaround works for now but I am getting a new error at the line:
p.map(workers.run(used_device), [i for i in range(0,3)])
642 return self._value
643 else:
--> 644 raise self._value
645
646 def _set(self, i, obj):
TypeError: 'NoneType' object is not callable
Here is the code snippet from the python file
import torch
import numpy
from torch.utils.data import Dataset, DataLoader
import pdb
class data(Dataset):
# Constructor
def __init__(self, x, y):
self.x = x
self.y = y
self.len = self.x.shape[0]
# Getter
def __getitem__(self, idx):
return self.x[idx], self.y[idx]
# Return the length
def __len__(self):
return self.len
def run(device):
x = numpy.random.rand(1700,402)
y = numpy.random.rand(1700)
dataset = data(torch.Tensor(x),torch.Tensor(y))
print('the length of the dataset = ', len(dataset))
data_loader = DataLoader(dataset, batch_size = 100, shuffle = True)
for idxs, (xx, yy) in enumerate(data_loader):
xx, yy = xx.to(device), yy.to(device)
print ('idx: {} x: {} y: {}'.format(idxs, xx, yy))
this is the code snippet from the Jupiter notebook:
from multiprocessing import Pool
import workers
if __name__ == "__main__":
used_device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
num_processors = 2
p=Pool(processes = num_processors)
p.map(workers.run(used_device), [i for i in range(0,3)])
No no no, I don’t think you understand the post. The correct thing is to do is to create a new source file worker.py with all your code in it and then in Jupyter Notebook you call worker.run("cuda"). You don’t need to use multiprocessing manually.
That’s exactly what I did. I created a new file workers.py. The data class and run function are in a separate file workers.py which is loaded in the jupyter notebook as import workers.
I did a mistake using multiprocessing pool here. Thanks for notifying me. Now it works smoothly. Cheers.