Hi, I encountered a problem after converting the pytorch model to the torchscript model, C++ forward is much slower than python
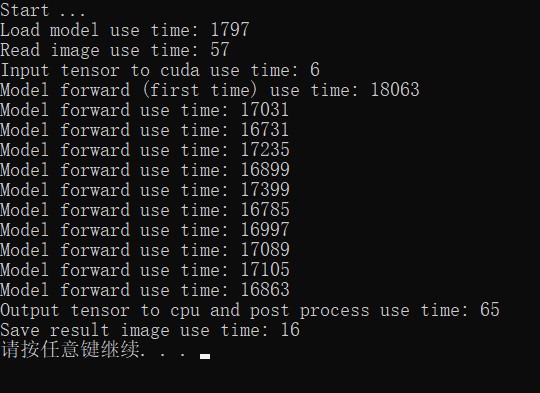
a well-trained model cannot be uploaded, i dont know how to provide this for testing, maybe email ?
graphic card: RTX2070
my python virtual env is:
cuda10.2
python3.7
pytorch1.5.1
torchvision0.6.1
below is some necessary code:
deeplabv3_plus.py →
import torch
import math
import torch.nn as nn
import torch.nn.functional as F
from torchvision import models
import torch.utils.model_zoo as model_zoo
from itertools import chain
'''
-> ResNet BackBone
'''
def initialize_weights(*models):
for model in models:
for m in model.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight.data, nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1.)
m.bias.data.fill_(1e-4)
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0.0, 0.0001)
m.bias.data.zero_()
class BaseModel(nn.Module):
def __init__(self):
super(BaseModel, self).__init__()
# self.logger = logging.getLogger(self.__class__.__name__)
def forward(self):
raise NotImplementedError
def summary(self):
model_parameters = filter(lambda p: p.requires_grad, self.parameters())
nbr_params = sum([np.prod(p.size()) for p in model_parameters])
self.logger.info(f'Nbr of trainable parameters: {nbr_params}')
def __str__(self):
model_parameters = filter(lambda p: p.requires_grad, self.parameters())
nbr_params = sum([np.prod(p.size()) for p in model_parameters])
return super(BaseModel, self).__str__() + f'\nNbr of trainable parameters: {nbr_params}'
#return summary(self, input_shape=(2, 3, 224, 224))
class ResNet(nn.Module):
def __init__(self, in_channels=3, output_stride=16, backbone='resnet101', pretrained=True):
super(ResNet, self).__init__()
model = getattr(models, backbone)(pretrained)
if not pretrained or in_channels != 3:
self.layer0 = nn.Sequential(
nn.Conv2d(in_channels, 64, 7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
initialize_weights(self.layer0)
else:
self.layer0 = nn.Sequential(*list(model.children())[:4])
self.layer1 = model.layer1
self.layer2 = model.layer2
self.layer3 = model.layer3
self.layer4 = model.layer4
if output_stride == 16: s3, s4, d3, d4 = (2, 1, 1, 2)
elif output_stride == 8: s3, s4, d3, d4 = (1, 1, 2, 4)
if output_stride == 8:
for n, m in self.layer3.named_modules():
if 'conv1' in n and (backbone == 'resnet34' or backbone == 'resnet18'):
m.dilation, m.padding, m.stride = (d3,d3), (d3,d3), (s3,s3)
elif 'conv2' in n:
m.dilation, m.padding, m.stride = (d3,d3), (d3,d3), (s3,s3)
elif 'downsample.0' in n:
m.stride = (s3, s3)
for n, m in self.layer4.named_modules():
if 'conv1' in n and (backbone == 'resnet34' or backbone == 'resnet18'):
m.dilation, m.padding, m.stride = (d4,d4), (d4,d4), (s4,s4)
elif 'conv2' in n:
m.dilation, m.padding, m.stride = (d4,d4), (d4,d4), (s4,s4)
elif 'downsample.0' in n:
m.stride = (s4, s4)
def forward(self, x):
x = self.layer0(x)
x = self.layer1(x)
low_level_features = x
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
return x, low_level_features
'''
-> (Aligned) Xception BackBone
Pretrained model from https://github.com/Cadene/pretrained-models.pytorch
by Remi Cadene
'''
class SeparableConv2d(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size=3, stride=1, dilation=1, bias=False, BatchNorm=nn.BatchNorm2d):
super(SeparableConv2d, self).__init__()
if dilation > kernel_size//2: padding = dilation
else: padding = kernel_size//2
self.conv1 = nn.Conv2d(in_channels, in_channels, kernel_size, stride, padding=padding,
dilation=dilation, groups=in_channels, bias=bias)
self.bn = nn.BatchNorm2d(in_channels)
self.pointwise = nn.Conv2d(in_channels, out_channels, 1, 1, bias=bias)
def forward(self, x):
x = self.conv1(x)
x = self.bn(x)
x = self.pointwise(x)
return x
class Block(nn.Module):
def __init__(self, in_channels, out_channels, stride=1, dilation=1, exit_flow=False, use_1st_relu=True):
super(Block, self).__init__()
if in_channels != out_channels or stride !=1:
self.skip = nn.Conv2d(in_channels, out_channels, 1, stride=stride, bias=False)
self.skipbn = nn.BatchNorm2d(out_channels)
else: self.skip = None
rep = []
self.relu = nn.ReLU(inplace=True)
rep.append(self.relu)
rep.append(SeparableConv2d(in_channels, out_channels, 3, stride=1, dilation=dilation))
rep.append(nn.BatchNorm2d(out_channels))
rep.append(self.relu)
rep.append(SeparableConv2d(out_channels, out_channels, 3, stride=1, dilation=dilation))
rep.append(nn.BatchNorm2d(out_channels))
rep.append(self.relu)
rep.append(SeparableConv2d(out_channels, out_channels, 3, stride=stride, dilation=dilation))
rep.append(nn.BatchNorm2d(out_channels))
if exit_flow:
rep[3:6] = rep[:3]
rep[:3] = [
self.relu,
SeparableConv2d(in_channels, in_channels, 3, 1, dilation),
nn.BatchNorm2d(in_channels)]
if not use_1st_relu: rep = rep[1:]
self.rep = nn.Sequential(*rep)
def forward(self, x):
output = self.rep(x)
if self.skip is not None:
skip = self.skip(x)
skip = self.skipbn(skip)
else:
skip = x
x = output + skip
return x
class Xception(nn.Module):
def __init__(self, output_stride=16, in_channels=3, pretrained=True):
super(Xception, self).__init__()
# Stride for block 3 (entry flow), and the dilation rates for middle flow and exit flow
if output_stride == 16: b3_s, mf_d, ef_d = 2, 1, (1, 2)
if output_stride == 8: b3_s, mf_d, ef_d = 1, 2, (2, 4)
# Entry Flow
self.conv1 = nn.Conv2d(in_channels, 32, 3, 2, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(32)
self.relu = nn.ReLU(inplace=True)
self.conv2 = nn.Conv2d(32, 64, 3, 1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(64)
self.block1 = Block(64, 128, stride=2, dilation=1, use_1st_relu=False)
self.block2 = Block(128, 256, stride=2, dilation=1)
self.block3 = Block(256, 728, stride=b3_s, dilation=1)
# Middle Flow
for i in range(16):
exec(f'self.block{i+4} = Block(728, 728, stride=1, dilation=mf_d)')
# Exit flow
self.block20 = Block(728, 1024, stride=1, dilation=ef_d[0], exit_flow=True)
self.conv3 = SeparableConv2d(1024, 1536, 3, stride=1, dilation=ef_d[1])
self.bn3 = nn.BatchNorm2d(1536)
self.conv4 = SeparableConv2d(1536, 1536, 3, stride=1, dilation=ef_d[1])
self.bn4 = nn.BatchNorm2d(1536)
self.conv5 = SeparableConv2d(1536, 2048, 3, stride=1, dilation=ef_d[1])
self.bn5 = nn.BatchNorm2d(2048)
initialize_weights(self)
if pretrained: self._load_pretrained_model()
def _load_pretrained_model(self):
url = 'http://data.lip6.fr/cadene/pretrainedmodels/xception-b5690688.pth'
pretrained_weights = model_zoo.load_url(url)
state_dict = self.state_dict()
model_dict = {}
for k, v in pretrained_weights.items():
if k in state_dict:
if 'pointwise' in k:
v = v.unsqueeze(-1).unsqueeze(-1) # [C, C] -> [C, C, 1, 1]
if k.startswith('block11'):
# In Xception there is only 8 blocks in Middle flow
model_dict[k] = v
for i in range(8):
model_dict[k.replace('block11', f'block{i+12}')] = v
elif k.startswith('block12'):
model_dict[k.replace('block12', 'block20')] = v
elif k.startswith('bn3'):
model_dict[k] = v
model_dict[k.replace('bn3', 'bn4')] = v
elif k.startswith('conv4'):
model_dict[k.replace('conv4', 'conv5')] = v
elif k.startswith('bn4'):
model_dict[k.replace('bn4', 'bn5')] = v
else:
model_dict[k] = v
state_dict.update(model_dict)
self.load_state_dict(state_dict)
def forward(self, x):
# Entry flow
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.conv2(x)
x = self.bn2(x)
x = self.block1(x)
low_level_features = x
x = F.relu(x)
x = self.block2(x)
x = self.block3(x)
# Middle flow
x = self.block4(x)
x = self.block5(x)
x = self.block6(x)
x = self.block7(x)
x = self.block8(x)
x = self.block9(x)
x = self.block10(x)
x = self.block11(x)
x = self.block12(x)
x = self.block13(x)
x = self.block14(x)
x = self.block15(x)
x = self.block16(x)
x = self.block17(x)
x = self.block18(x)
x = self.block19(x)
# Exit flow
x = self.block20(x)
x = self.relu(x)
x = self.conv3(x)
x = self.bn3(x)
x = self.relu(x)
x = self.conv4(x)
x = self.bn4(x)
x = self.relu(x)
x = self.conv5(x)
x = self.bn5(x)
x = self.relu(x)
return x, low_level_features
'''
-> The Atrous Spatial Pyramid Pooling
'''
def assp_branch(in_channels, out_channles, kernel_size, dilation):
padding = 0 if kernel_size == 1 else dilation
return nn.Sequential(
nn.Conv2d(in_channels, out_channles, kernel_size, padding=padding, dilation=dilation, bias=False),
nn.BatchNorm2d(out_channles),
nn.ReLU(inplace=True))
class ASSP(nn.Module):
def __init__(self, in_channels, output_stride):
super(ASSP, self).__init__()
assert output_stride in [8, 16], 'Only output strides of 8 or 16 are suported'
if output_stride == 16: dilations = [1, 6, 12, 18]
elif output_stride == 8: dilations = [1, 12, 24, 36]
self.aspp1 = assp_branch(in_channels, 256, 1, dilation=dilations[0])
self.aspp2 = assp_branch(in_channels, 256, 3, dilation=dilations[1])
self.aspp3 = assp_branch(in_channels, 256, 3, dilation=dilations[2])
self.aspp4 = assp_branch(in_channels, 256, 3, dilation=dilations[3])
self.avg_pool = nn.Sequential(
nn.AdaptiveAvgPool2d((1, 1)),
nn.Conv2d(in_channels, 256, 1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True))
self.conv1 = nn.Conv2d(256*5, 256, 1, bias=False)
self.bn1 = nn.BatchNorm2d(256)
self.relu = nn.ReLU(inplace=True)
self.dropout = nn.Dropout(0.5)
initialize_weights(self)
def forward(self, x):
x1 = self.aspp1(x)
x2 = self.aspp2(x)
x3 = self.aspp3(x)
x4 = self.aspp4(x)
x5 = F.interpolate(self.avg_pool(x), size=(x.size(2), x.size(3)), mode='bilinear', align_corners=True)
x = self.conv1(torch.cat((x1, x2, x3, x4, x5), dim=1))
x = self.bn1(x)
x = self.dropout(self.relu(x))
return x
'''
-> Decoder
'''
class Decoder(nn.Module):
def __init__(self, low_level_channels, num_classes):
super(Decoder, self).__init__()
self.conv1 = nn.Conv2d(low_level_channels, 48, 1, bias=False)
self.bn1 = nn.BatchNorm2d(48)
self.relu = nn.ReLU(inplace=True)
# Table 2, best performance with two 3x3 convs
self.output = nn.Sequential(
nn.Conv2d(48+256, 256, 3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, 3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(inplace=True),
nn.Dropout(0.1),
nn.Conv2d(256, num_classes, 1, stride=1),
)
initialize_weights(self)
def forward(self, x, low_level_features):
low_level_features = self.conv1(low_level_features)
low_level_features = self.relu(self.bn1(low_level_features))
H, W = low_level_features.size(2), low_level_features.size(3)
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
x = self.output(torch.cat((low_level_features, x), dim=1))
return x
'''
-> Deeplab V3 +
'''
class DeepLab(BaseModel):
def __init__(self, num_classes, in_channels=3, backbone='xception', pretrained=True,
output_stride=16, freeze_bn=False, **_):
super(DeepLab, self).__init__()
assert ('xception' or 'resnet' in backbone)
if 'resnet' in backbone:
# from resnest.torch import resnest50
self.backbone = ResNet(in_channels=in_channels, output_stride=output_stride, pretrained=pretrained)
# self.backbone = resnest50(pretrained=pretrained)
low_level_channels = 256
else:
self.backbone = Xception(output_stride=output_stride, pretrained=pretrained)
low_level_channels = 128
self.ASSP = ASSP(in_channels=2048, output_stride=output_stride)
self.decoder = Decoder(low_level_channels, num_classes)
if freeze_bn: self.freeze_bn()
def forward(self, x):
H, W = x.size(2), x.size(3)
x, low_level_features = self.backbone(x)
x = self.ASSP(x)
x = self.decoder(x, low_level_features)
x = F.interpolate(x, size=(H, W), mode='bilinear', align_corners=True)
return x
# Two functions to yield the parameters of the backbone
# & Decoder / ASSP to use differentiable learning rates
# FIXME: in xception, we use the parameters from xception and not aligned xception
# better to have higher lr for this backbone
def get_backbone_params(self):
return self.backbone.parameters()
def get_decoder_params(self):
return chain(self.ASSP.parameters(), self.decoder.parameters())
def freeze_bn(self):
for module in self.modules():
if isinstance(module, nn.BatchNorm2d): module.eval()
trace_model.py →
import torch
from deeplabv3_plus import DeepLab
from pathlib import Path
def main(num_classes, pth_path):
model = DeepLab(num_classes=num_classes, backbone="resnet50", freeze_bn=False, freeze_backbone=False)
visible_gpus = list(range(torch.cuda.device_count()))
device = torch.device('cuda:0' if len(visible_gpus) > 0 else 'cpu')
checkpoint = torch.load(pth_path)
model.load_state_dict(checkpoint)
model.to(device)
model.eval()
# save pt which can be called by c++
dummy_input = torch.rand(1, 3, 648, 483)
dummy_input = dummy_input.cuda()
traced_model = torch.jit.trace(model, dummy_input)
traced_model_path = str(Path(pth_path).parent.joinpath('traced_model.pt'))
traced_model.save(traced_model_path)
print('traced model saved as {}'.format(traced_model_path))
if __name__ == '__main__':
main(num_classes=4, pth_path='model_state_dict.pth')
libtorch_predict.cpp:
#include "assert.h"
#include <iostream>
#include <torch/script.h>
#include <map>
#include <cuda.h>
#include <cuda_runtime.h>
#include <string>
#include <time.h>
#include <opencv2/core.hpp>
#include <opencv2/opencv.hpp>
int main()
{
std::cout << "Start ..." << std::endl;
auto t1 = clock();
torch::jit::script::Module model = torch::jit::load("traced_model.pt");
model.to(at::kCUDA);
model.eval();
cudaDeviceSynchronize();
std::cout << "Load model use time: " << clock() - t1 << std::endl;
t1 = clock();
cv::Mat src = cv::imread("test.jpg");
cv::cvtColor(src, src, cv::COLOR_BGR2RGB);
src.convertTo(src, CV_32FC3, 1.0f / 255.0f);
auto input_tensor = torch::from_blob(src.data, { 1, src.rows, src.cols, 3 }).permute({ 0, 3, 1, 2 });
input_tensor[0][0] = input_tensor[0][0].sub_(0.5).div_(0.5);
input_tensor[0][1] = input_tensor[0][1].sub_(0.5).div_(0.5);
input_tensor[0][2] = input_tensor[0][2].sub_(0.5).div_(0.5);
cudaDeviceSynchronize();
std::cout << "Read image use time: " << clock() - t1 << std::endl;
t1 = clock();
// to gpu
input_tensor = input_tensor.to(at::kCUDA);
cudaDeviceSynchronize();
std::cout << "Input tensor to cuda use time: " << clock() - t1 << std::endl;
t1 = clock();
torch::NoGradGuard no_grad_guard;
torch::Tensor output_tensor = model.forward({ input_tensor }).toTensor();
cudaDeviceSynchronize();
std::cout << "Model forward (first time) use time: " << clock() - t1 << std::endl;
for (int i = 0; i < 10; i++) {
t1 = clock();
output_tensor = model.forward({ input_tensor }).toTensor();
cudaDeviceSynchronize();
std::cout << "Model forward use time: " << clock() - t1 << std::endl;
}
t1 = clock();
output_tensor = output_tensor.squeeze();
output_tensor = output_tensor.to(torch::kCPU);
auto prediction = output_tensor.softmax(0).max(0);
auto class_map = std::get<1>(prediction);
class_map = class_map.to(torch::kU8);
cudaDeviceSynchronize();
std::cout << "Output tensor to cpu and post process use time: " << clock() - t1 << std::endl;
t1 = clock();
int h = class_map.size(0);
int w = class_map.size(1);
cv::Mat result_img(h, w, CV_8UC1);
std::memcpy((void *)result_img.data, class_map.data_ptr(), sizeof(torch::kU8) * class_map.numel());
cv::imwrite("result.jpg", result_img * 80);
cudaDeviceSynchronize();
std::cout << "Save result image use time: " << clock() - t1 << std::endl;
system("pause");
return 0;
}