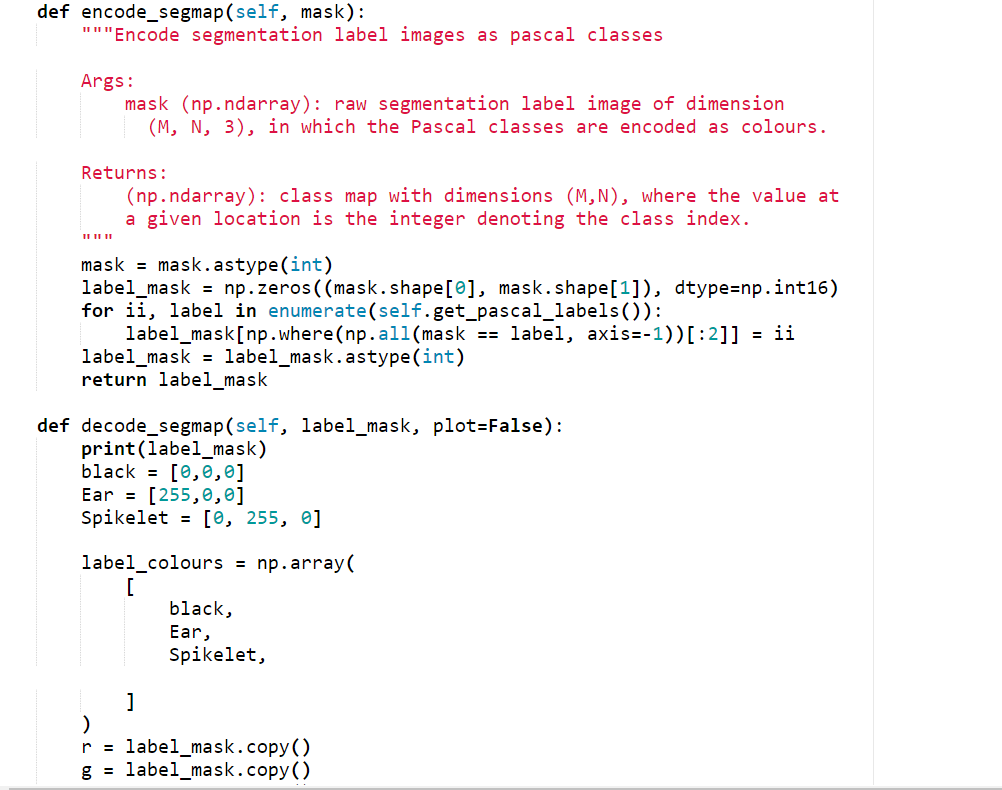
I think I don’t have a good understanding of train accuracy. This is the snippet for train the model and calculates the loss and train accuracy for segmentation task.
for epoch in range(2): # loop over the dataset multiple times
running_loss = 0
total_train = 0
correct_train = 0
for i, data in enumerate(train_loader, 0):
# get the inputs
t_image, mask = data
t_image, mask = Variable(t_image.to(device)), Variable(mask.to(device))
# zeroes the gradient buffers of all parameters
optimizer.zero_grad()
# forward + backward + optimize
outputs = model(t_image) # forward
loss = criterion(outputs, mask) # calculate the loss
loss.backward() # back propagation
optimizer.step() # update gradients
running_loss += loss.item()
# accuracy
_, predicted = torch.max(outputs.data, 1)
total_train += mask.size(0)
correct_train += predicted.eq(mask.data).sum().item()
train_accuracy = 100 * correct_train / total_train
#avg_accuracy = train_accuracy / len(train_loader)
print('Epoch {}, train Loss: {:.3f}'.format(epoch, loss.item()), "Training Accuracy: %d %%" % (train_accuracy))
I am getting a number like below for the training accuracy which I assume is the amount of pixel which corresponds with the ground truth (mask). is that correct?
Epoch 0, train Loss: 0.721 Training Accuracy: 500300 %
Epoch 0, train Loss: 0.707 Training Accuracy: 676000 %
You are currently summing all correctly predicted pixels and divide it by the batch size. To get a valid accuracy between 0 and 100% you should divide correct_train by the number of pixels in your batch.
Try to calculate total_train as total_train += mask.nelement().
first line: return the indices of max values along rows in softmax probability output (torch.max returns a tuple containing the maximum value and the index of the maximum value within the tensor. Since the index in our case represents the classified category itself, we will only take that ignoring the actual probability).
second line: number of pixel in the batch
third line: By summing the output of the .eq() function, we get a count of the number of times the neural network has produced a correct output, and we take an accumulating sum of these correct predictions so that we can determine the accuracy of the network.
I am getting 100% accuracy. I don’t know how to correct it. I am using the code of following link on my own dataset. The dataset set 400 training images and 120 validation images. Please help me.
Are you concerned about possible errors in the calculation of the accuracy or are you concerned you might have another error in the code, e.g. data leakage?
Yes i’m concerned about possible errors in the calculation of the accuracy. On each model i’m getting 100% accuracy after some epochs i think there some over fitting or some issue with accuracy calculation but i don’t know how to correct.
How would you like to define your accuracy?
If you are dealing with a multi-class classification use case, you could compare the predictions to the targets via:
Hey, I am computing the accuracy in a same way. As
for epoch in range(epochs):
net.train()
epoch_loss = 0
total_train = 0
correct_train = 0
with tqdm(total=n_train, desc=f'Epoch {epoch + 1}/{epochs}', unit='img') as pbar:
for batch in train_loader:
#continue
imgs = batch['image']
true_masks = batch['mask']
n_batch = np.ceil(n_train/batch_size)
assert imgs.shape[1] == net.n_channels, \
f'Network has been defined with {net.n_channels} input channels, ' \
f'but loaded images have {imgs.shape[1]} channels. Please check that ' \
'the images are loaded correctly.'
imgs = imgs.to(device=device, dtype=torch.float32)
mask_type = torch.float32 if net.n_classes == 1 else torch.long
true_masks = true_masks.to(device=device, dtype=mask_type)
logits,probs,masks_pred = net(imgs) #logits, probas, preds
loss = criterion(logits, true_masks)
epoch_loss += loss.item()
#writer.add_scalar('Loss/train', loss.item(), global_step)
pbar.set_postfix(**{'loss (batch)': loss.item()})
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_value_(net.parameters(), 0.1)
#! nvidia-smi
optimizer.step()
torch.cuda.empty_cache()
#! nvidia-smi
total_train += true_masks.nelement()
print('total_train',total_train)
#print('masks_pred.eq(true_masks).sum()',masks_pred.eq(true_masks).sum())
correct_train += masks_pred.eq(true_masks).sum().item()
print('correct_train',correct_train)
train_accuracy = 100*correct_train/total_train
print('train_accuracy',train_accuracy)
The weird thing is that, when my batch_size=1, the accuracy is a value between 0-100%. But, when the batch_size => 2, the accuracy isn’t in a range of 100% any more. I tried to compute the
train_accuracy =
100*correct_train/total_train
outside of the
for batch in train_loader:
but, still didn’t get a reasonable value. I didn’t get why it doesn’t work properly, when the batch_size = > 2. Could you please explain it? Thank u. @ptrblck@Neda
might use broadcasting, if you don’t use tensors in the right shape.
I would recommend to print the shapes of all tensors, which are used to compute the accuracy and make sure they have matching shapes.
Many thanks for putting me into right direction. Yes, when the batch_size=1, my true_masks.shape =[1,1,640,959], when the batch_size=2, my true_masks.shape=[2,1,640,959]. Using torch.squeeze(true_masks,1) solved my problem. @ptrblck