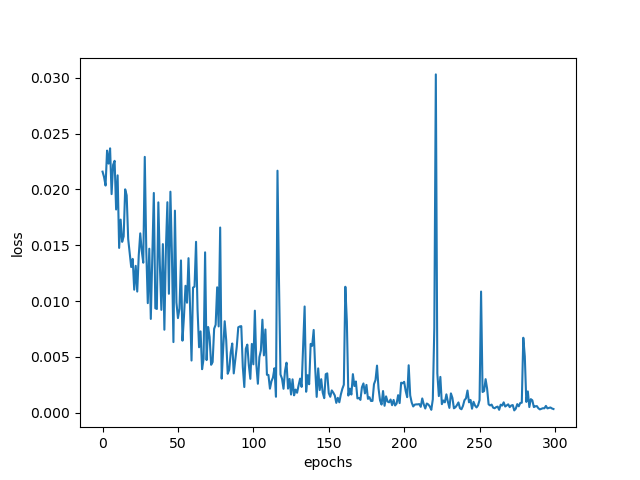
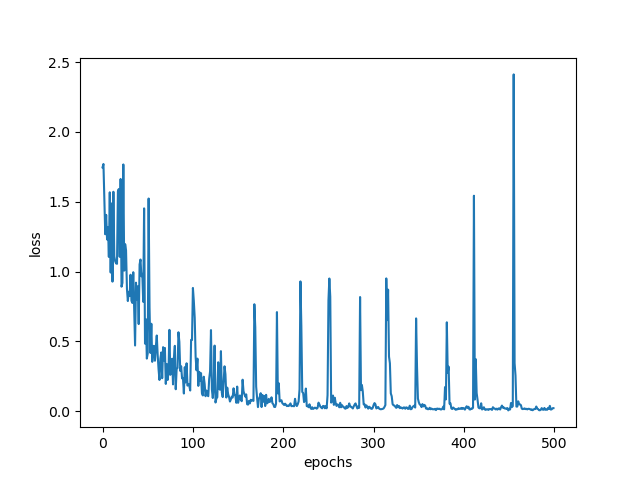
Hi,
My epoch loss curve for my multi-class UNET segmentation model looks really off. I get this weird periodic behavior and the loss doesn’t seem to stabilize even with 500 epochs.
Below is my training function:
def train_fn(loader, model, optimizer, loss_fn, scaler, loss_values):
loop = tqdm(loader)
running_loss = 0.0
for batch_idx, (data, targets, _) in enumerate(loop):
data = data.to(device=DEVICE)
targets = targets.long().unsqueeze(1).to(device=DEVICE)
# forward
with torch.cuda.amp.autocast():
predictions = model(data) #should be (N, C) where C = num of classes
loss = loss_fn(predictions, targets.squeeze(1))
# backward
optimizer.zero_grad()
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
running_loss =+ loss.item() * data.size(0)
# update tqdm loop
loop.set_postfix(loss=loss.item())
loss_values.append(running_loss/len(data))
which gets called for each epoch in the following snippet from main():
scaler = torch.cuda.amp.GradScaler()
loss_values = []
start = time.time()
for epoch in range(NUM_EPOCHS):
train_fn(train_loader, model, optimizer, loss_fn, scaler, loss_values)
# save model
checkpoint = {
"state_dict": model.state_dict(),
"optimizer":optimizer.state_dict(),
}
save_checkpoint(checkpoint)
# check accuracy
check_accuracy(val_loader, model, device=DEVICE)
end = time.time()
Any idea why this might be the case? Thank you!