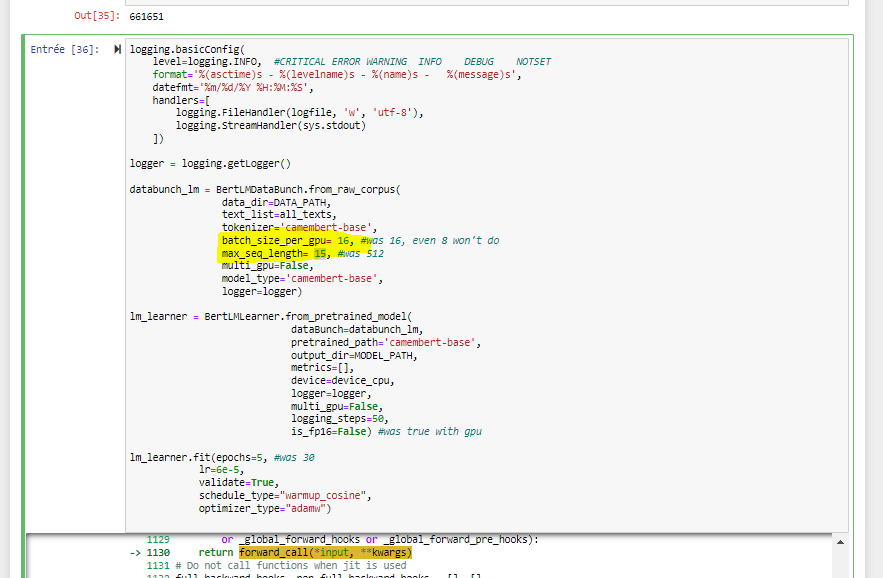
I am trying to fine tune Camembert on my data for classification. I have two classes Accepted and Rejected. I installed manually Camembert Base in my work laptop. I am having this issue. I tried to change the embedding dimensions as well as max length seq.
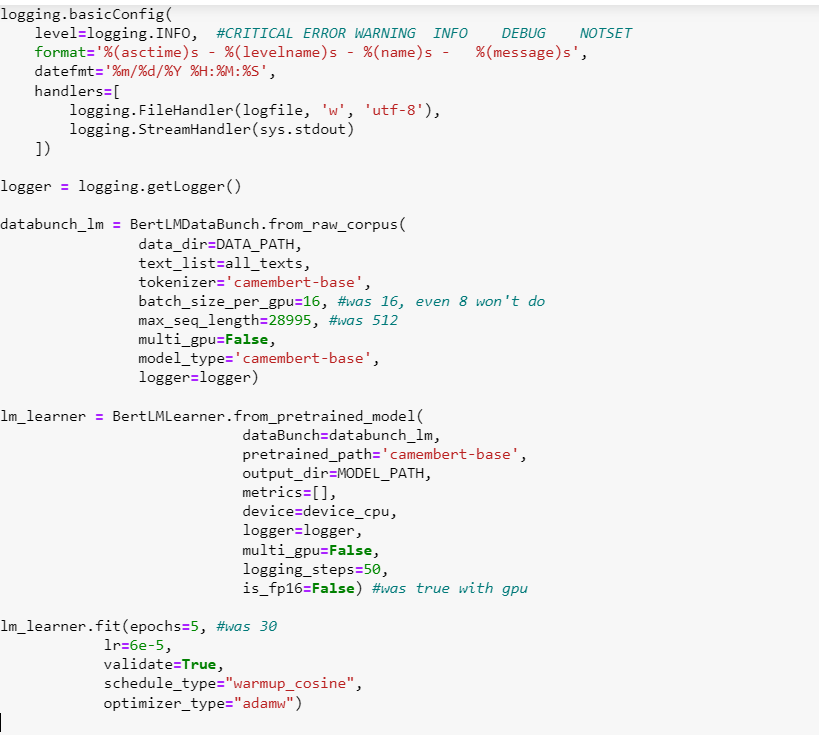
IndexError Traceback (most recent call last)
Input In [66], in <cell line: 1>()
----> 1 lm_learner.fit(epochs=5, #was 30
2 lr=6e-5,
3 validate=True,
4 schedule_type=“warmup_cosine”,
5 optimizer_type=“adamw”)
File ~\Miniconda3\envs\env2clone\lib\site-packages\fast_bert-2.0.6-py3.8.egg\fast_bert\learner_lm.py:211, in BertLMLearner.fit(self, epochs, lr, validate, schedule_type, optimizer_type)
209 inputs, labels = self.data.mask_tokens(batch)
210 cpu_device = torch.device(“cpu”)
→ 211 loss = self.training_step(batch)
213 tr_loss += loss.item()
214 epoch_loss += loss.item()
File ~\Miniconda3\envs\env2clone\lib\site-packages\fast_bert-2.0.6-py3.8.egg\fast_bert\learner_lm.py:312, in BertLMLearner.training_step(self, batch)
310 outputs = self.model(inputs, labels=labels)
311 else:
→ 312 outputs = self.model(inputs, labels=labels)
314 loss = outputs[0]
316 if self.n_gpu > 1:
File ~\Miniconda3\envs\env2clone\lib\site-packages\torch\nn\modules\module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don’t have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
→ 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = ,
File ~\Miniconda3\envs\env2clone\lib\site-packages\transformers\models\roberta\modeling_roberta.py:1098, in RobertaForMaskedLM.forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, labels, output_attentions, output_hidden_states, return_dict)
1088 r"“”
1089 labels (torch.LongTensor of shape (batch_size, sequence_length), optional):
1090 Labels for computing the masked language modeling loss. Indices should be in `[-100, 0, …,
(…)
1094 Used to hide legacy arguments that have been deprecated.
1095 “”"
1096 return_dict = return_dict if return_dict is not None else self.config.use_return_dict
→ 1098 outputs = self.roberta(
1099 input_ids,
1100 attention_mask=attention_mask,
1101 token_type_ids=token_type_ids,
1102 position_ids=position_ids,
1103 head_mask=head_mask,
1104 inputs_embeds=inputs_embeds,
1105 encoder_hidden_states=encoder_hidden_states,
1106 encoder_attention_mask=encoder_attention_mask,
1107 output_attentions=output_attentions,
1108 output_hidden_states=output_hidden_states,
1109 return_dict=return_dict,
1110 )
1111 sequence_output = outputs[0]
1112 prediction_scores = self.lm_head(sequence_output)
File ~\Miniconda3\envs\env2clone\lib\site-packages\torch\nn\modules\module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don’t have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
→ 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = ,
File ~\Miniconda3\envs\env2clone\lib\site-packages\transformers\models\roberta\modeling_roberta.py:844, in RobertaModel.forward(self, input_ids, attention_mask, token_type_ids, position_ids, head_mask, inputs_embeds, encoder_hidden_states, encoder_attention_mask, past_key_values, use_cache, output_attentions, output_hidden_states, return_dict)
837 # Prepare head mask if needed
838 # 1.0 in head_mask indicate we keep the head
839 # attention_probs has shape bsz x n_heads x N x N
840 # input head_mask has shape [num_heads] or [num_hidden_layers x num_heads]
841 # and head_mask is converted to shape [num_hidden_layers x batch x num_heads x seq_length x seq_length]
842 head_mask = self.get_head_mask(head_mask, self.config.num_hidden_layers)
→ 844 embedding_output = self.embeddings(
845 input_ids=input_ids,
846 position_ids=position_ids,
847 token_type_ids=token_type_ids,
848 inputs_embeds=inputs_embeds,
849 past_key_values_length=past_key_values_length,
850 )
851 encoder_outputs = self.encoder(
852 embedding_output,
853 attention_mask=extended_attention_mask,
(…)
861 return_dict=return_dict,
862 )
863 sequence_output = encoder_outputs[0]
File ~\Miniconda3\envs\env2clone\lib\site-packages\torch\nn\modules\module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don’t have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
→ 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = ,
File ~\Miniconda3\envs\env2clone\lib\site-packages\transformers\models\roberta\modeling_roberta.py:132, in RobertaEmbeddings.forward(self, input_ids, token_type_ids, position_ids, inputs_embeds, past_key_values_length)
129 token_type_ids = torch.zeros(input_shape, dtype=torch.long, device=self.position_ids.device)
131 if inputs_embeds is None:
→ 132 inputs_embeds = self.word_embeddings(input_ids)
133 token_type_embeddings = self.token_type_embeddings(token_type_ids)
135 embeddings = inputs_embeds + token_type_embeddings
File ~\Miniconda3\envs\env2clone\lib\site-packages\torch\nn\modules\module.py:1130, in Module._call_impl(self, *input, **kwargs)
1126 # If we don’t have any hooks, we want to skip the rest of the logic in
1127 # this function, and just call forward.
1128 if not (self._backward_hooks or self._forward_hooks or self._forward_pre_hooks or _global_backward_hooks
1129 or _global_forward_hooks or _global_forward_pre_hooks):
→ 1130 return forward_call(*input, **kwargs)
1131 # Do not call functions when jit is used
1132 full_backward_hooks, non_full_backward_hooks = ,
File ~\Miniconda3\envs\env2clone\lib\site-packages\torch\nn\modules\sparse.py:158, in Embedding.forward(self, input)
157 def forward(self, input: Tensor) → Tensor:
→ 158 return F.embedding(
159 input, self.weight, self.padding_idx, self.max_norm,
160 self.norm_type, self.scale_grad_by_freq, self.sparse)
File ~\Miniconda3\envs\env2clone\lib\site-packages\torch\nn\functional.py:2199, in embedding(input, weight, padding_idx, max_norm, norm_type, scale_grad_by_freq, sparse)
2193 # Note [embedding_renorm set_grad_enabled]
2194 # XXX: equivalent to
2195 # with torch.no_grad():
2196 # torch.embedding_renorm_
2197 # remove once script supports set_grad_enabled
2198 no_grad_embedding_renorm(weight, input, max_norm, norm_type)
→ 2199 return torch.embedding(weight, input, padding_idx, scale_grad_by_freq, sparse)
IndexError: index out of range in self