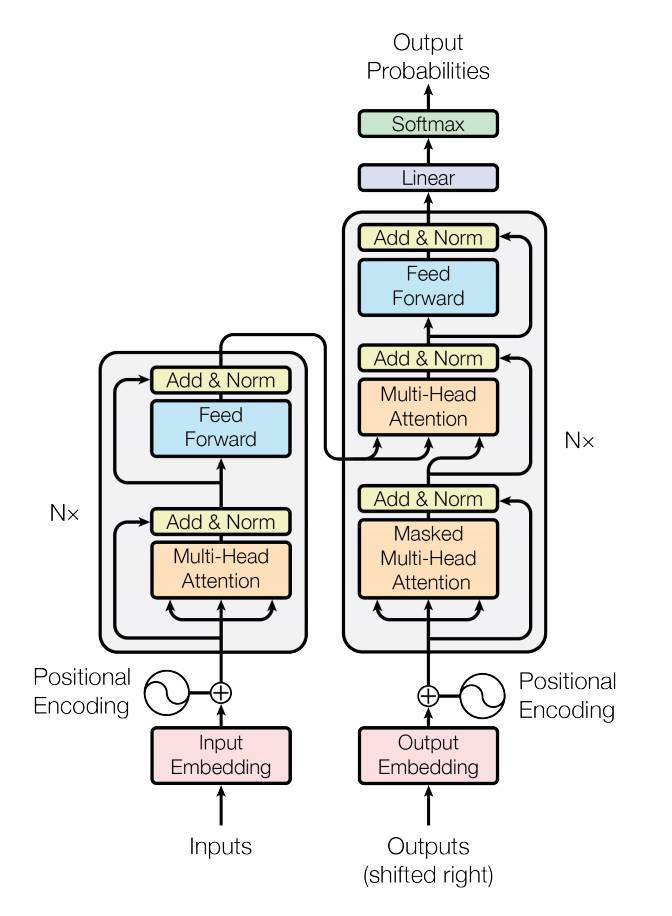
Embeddings - these are learnable weights where each token(token could be a word, sentence piece, subword, character, etc) are converted into a vector, say, with 500 values between 0 and 1 that are trainable.
Positional Encoding - for each token, we want to inform the model where it’s located, orderwise. This is because linear layers are not ideal for handling sequential information. So we manually pass this in by adding a vector of sine and cosine values on the first 2 elements in the embedding vector.
This sequence of vectors goes through an attention layer, which basically is like a learnable digitized database search function with keys, queries and values. In this case, we are “searching” for the most likely next token.
The Feed Forward is just a basic linear layer, but is applied across each embedding in the sequence separately(i.e. 3 dim tensor instead of 2 dim).
Then the final Linear layer is where we want to get out our predicted next token in the form of a vector of probabilities, which we apply a softmax to put the values in the range of 0 to 1.
There are two sides because when that diagram was developed, it was being used in language translations. But generative language models for next token prediction just use the Transformer decoder and not the encoder.
Here is a PyTorch tutorial that might help you go through how it works.
https://pytorch.org/tutorials/beginner/transformer_tutorial.html
And this is a tutorial that builds one from scratch in Pytorch: