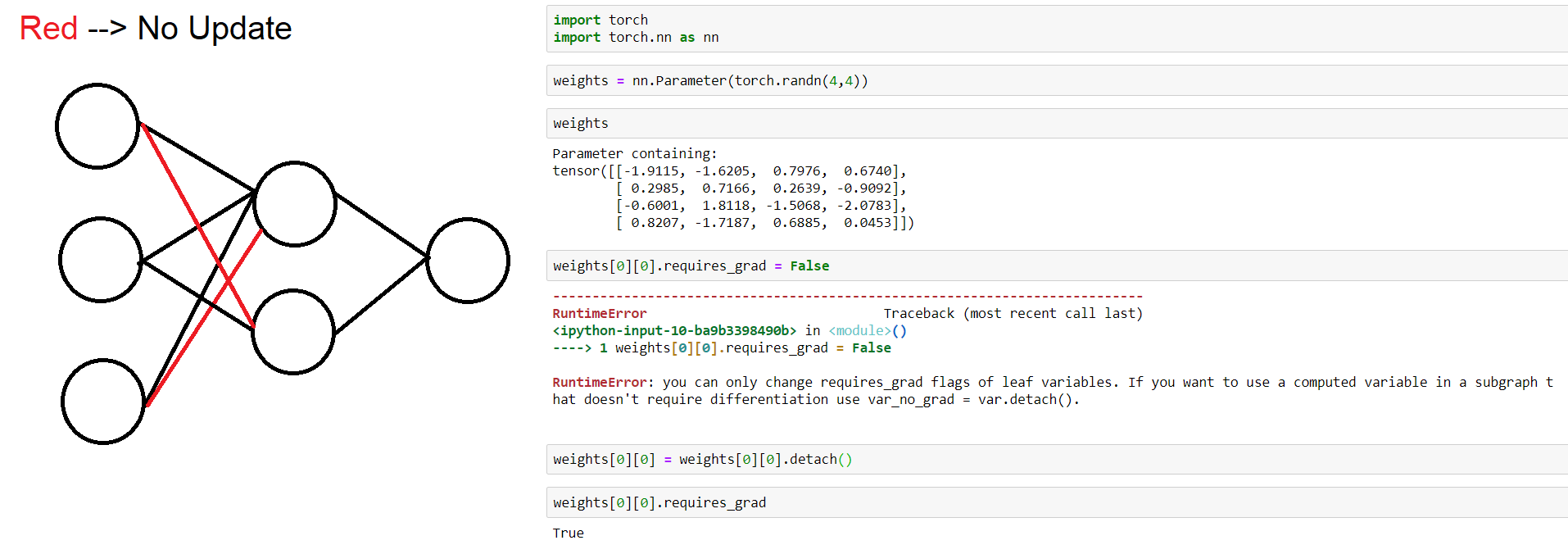
Hi.For a related problem, i would like to update parts of the weights, and keep the rest frozen. For example, Consider the below network, where the red weights are weights i want to freeze and not update during backpropagation. However, I can only set the requires_grad = False on a layer weights, not on some weights of a layer. I’ve used .detach() for that specific weight, and PyTorch gives no error, but the particular weight still has the requires_grad = false. Is there any way to specify the update to happen on some weights of a particular layer before calling .backward()
1 Like
interesting question. im curious to know how this can be possible?
No, detach() is used if you don’t want to do backward on that variable
To freeze some weights, you can add them to a different param groups in the optimizer, and set the learning rate there to be 0.
You can also manually set the grad of those weight to 0 before calling step()
Hi.Thanks for your answer. I can’t go with the second option because I want to freeze them before doing the backpropagation. However, for the first option, it dosen’t work as well. PyTorch still tells me that it can’t optimize these parameters. This is my code, and below is the error i get:
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.layer1 = nn.Linear(3,5, bias = False)
def forward(self, x):
return self.layer1(x)
net = Net()
total_num = sum(p.numel() for p in net.parameters() if p.requires_grad)
print(total_num) # 15 parameters in total
print(list(net.parameters())[0][1:].numel()) # 12 parameters to optimize
param = list(list(net.parameters())[0][1:])
optim = torch.optim.SGD(param, lr = 0)
ValueError: can't optimize a non-leaf Tensor
Is there any other way?
Thank you in advance!
I don’t think it’s possible necessarily because the whole layer is a weight matrix and the requires_grad attribute is for that whole variable. What you can do though is to
- After the forward pass, make a copy of the weights
- do backprop as usual
- apply the gradients to update the weights as ussual
- overwrite the weights you want to have frozen using the weights from the copy in (1) – you can simply use a mask for that, should be straightforward.
While it sounds like an ugly workaround, this is probably the most efficient approach, I assume, as you don’t have to add some custom checks during the forward or backward passes but just do a copy -> mask -> overwrite
Hi Sebastian Raschka,
Thanks for your answer. Yes it should work that way,but I’d like to save training time and not perform backprop on the weights i want to freeze. So the whole thing needs to happen before loss.backward(). If i do as you mentioned, or i set the gradients to zero before optimizer.step(), it still works, but there is no point because the backpropgation on all weights is happening anyways when calling loss.backward().
It seems that this is not possible in PyTorch by any means.
If there is anyone from the community that has a solution to this, it would be great if you share it here!
Then your only option might be to unvectorize your weights. Like I said, the problem is that you use weight matrices where the weight matrix as a whole counts as a parameter. If you want to not backprop certain weights, you need to unroll the weights into a for loop such that each weight_{i, j} is a network parameter with its own “requires_grad”
Or, after the backward() call and before the .step() call, you can go into layer.weight.grad and zero the weights that you want to not updated (I think this would be equivalent in most cases).
Btw I don’t see that as a Python or PyTorch limitation but rather that we vectorize for loops and partial derivative computations using matrix calculus. So this problem you have would be the same with pen&paper and other toolkits if you were to use matrix calculus.
Hi. Thanks for your answer.
Not calculating the gradients using a matrix multiplication was my last option. So it seems i’ll go with it.
Thanks for your kind reply! Highly appreciated.
There is an “easy” way of doing this. By actually specifying parameter-specific learning rates and setting them to 0 as already suggested in the other comments.
As you already found out you can’t specify each specific parameter in the optimizer like so: {'params': model.conv.weight[0, 0, 0, 0], 'lr': 0}. This raises the ValueError: can't optimize a non-leaf Tensor.
But you can specify a tensor for the learning rate that has the same shape as the parameter group: {'params': model.conv.weight, 'lr': tensor.zeros_like(model.conv.weight)}. If you do so you will encounter another problem: The optimizer e.g. Adam doesn’t allow a tensor as learning rate as addcdiv_() expects a scalar for its argument value. Therefore you need to change this last line in the step method to: p.data.add_((-step_size * (exp_avg / denom)))
Hi @oezguensi. Thanks for your reply. Yes that solves the problem. But in this case, I still need to do loss.backward() and perform backprop for all the weights. Then, I can do the update as you specified. My main question was about not performing backprop for some of the weights within the layer. I really appreciate your help though!
Hey! have you found an efficient solution?
I’m also facing a similar problem, where I need to freeze my weights to a fixed value. I want to save training time by neglecting the backprop on the weights that I freeze.
For now, I’m overwriting the weights again and again to the fixed value in every forward pass. But that’s not an efficient way.