I tried to use register_hook to freeze some parameters while training.
Here is the code:
def hook(grad):
new_grad = grad.clone()
np.random.seed(0)
sample_np = np.random.choice([1, 0], size=grad.size())
sample = torch.from_numpy(sample_np).byte().cuda()
new_grad[sample] = 0
return new_grad
I print the performance on the first conv layer in VGG16, where P represents the first 15 Parameters, W represents the corresponding gradients.
…
(‘PPPPPPPP’, tensor([ 0.5000, 0.4274, -0.0500, 0.2500, 0.0525, -0.4154, -0.0461,
-0.2650, -0.3166, 0.4115, 0.4319, -0.0625, 0.2500, 0.0537,
-0.5000]))
(‘WWWWWWWWWWW’, tensor(1.00000e-02 *
[-0.0000, -6.1934, -5.9751, -0.0000, -6.2996, -6.1873, -6.5755,
-6.6100, -6.5485, -6.3036, -6.3281, -0.0000, -0.0000, -6.2196,
-0.0000]))
(‘PPPPPPPP’, tensor([ 0.5000, 0.4274, -0.0500, 0.2500, 0.0525, -0.4154, -0.0461,
-0.2650, -0.3166, 0.4115, 0.4320, -0.0625, 0.2500, 0.0537,
-0.5000]))
(‘WWWWWWWWWWW’, tensor(1.00000e-02 *
[ 0.0000, 8.0362, 8.0241, 0.0000, 7.7295, 8.1179, 7.5825,
7.7483, 8.3302, 5.4533, 5.9402, 0.0000, 0.0000, 6.0850,
0.0000]))
(‘PPPPPPPP’, tensor([ 0.4999, 0.4273, -0.0501, 0.2500, 0.0524, -0.4156, -0.0462,
-0.2651, -0.3167, 0.4115, 0.4319, -0.0625, 0.2500, 0.0537,
-0.4999]))
(‘WWWWWWWWWWW’, tensor(1.00000e-02 *
[ 0.0000, 7.9904, 8.8366, 0.0000, 7.6422, 8.3999, 7.1233,
6.7701, 8.1726, 6.9615, 7.0442, 0.0000, 0.0000, 6.7049,
0.0000]))
(‘PPPPPPPP’, tensor([ 0.4999, 0.4272, -0.0503, 0.2500, 0.0522, -0.4157, -0.0463,
-0.2653, -0.3169, 0.4114, 0.4319, -0.0625, 0.2500, 0.0536,
-0.4999]))
(‘WWWWWWWWWWW’, tensor(1.00000e-02 *
[ 0.0000, 2.8951, 2.6120, 0.0000, 2.3587, 1.6937, 1.6543,
1.2820, 0.7402, 5.4065, 5.4882, 0.0000, 0.0000, 5.1986,
0.0000]))
…
As you can see, after some iterations, the fixed parameters(e.g. 0.5000–>0.4999) changed!
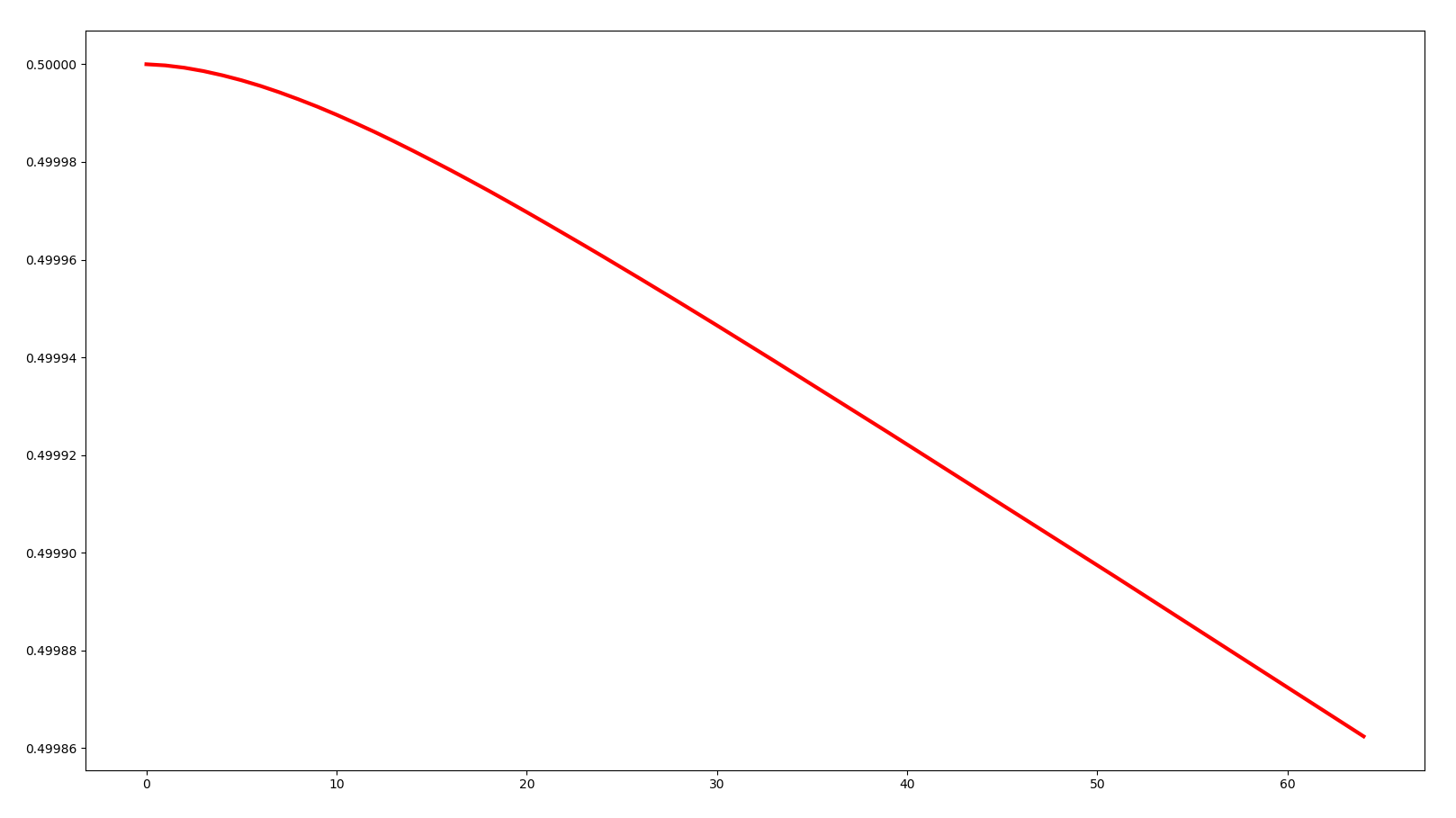
This plot is the change of the value of the first parameter.
Any idea about solving this is appreciated!