Hi all,
I am training on a Volta V-100 non state-of-art default architectures, but a standard CNN with the same layer repeated multiple times to assess the impact of increasing the number of layers / filters separately.
The task is classification on CIFAR10
One of them for instance look like this:
Conv_Net(
(act): ReLU()
(V): Conv2d(3, 64, kernel_size=(8, 8), stride=(1, 1), padding=(3, 3))
(P): MaxPool2d(kernel_size=4, stride=4, padding=2, dilation=1, ceil_mode=False)
(W): ModuleList(
(0): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(5): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(7): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(9): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(10): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(12): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(14): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
)
(C): Linear(in_features=4096, out_features=10, bias=True)
)
I get the next result for varying the depth between [16, 32] and the filters between [32,64].
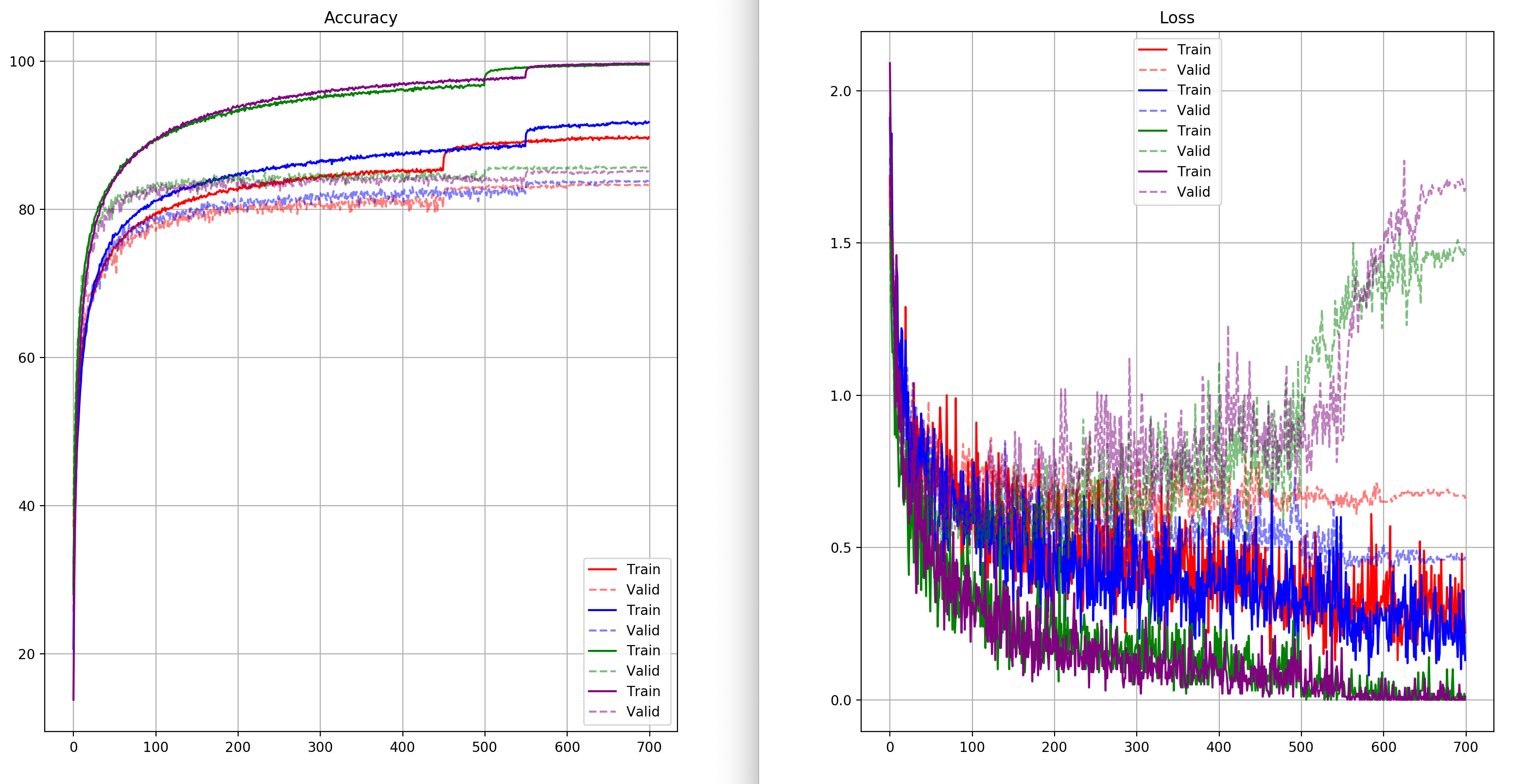
Is it normal that I see how the evolution of the loss in the validation set increases (normally when I reduce the learning rate by 10) I think indicating strong overfitting, but the validation accuracy keeps improving? Or at least not decreasing as I expected?
If so, what would be the explanation?
Thank you in advance
