Hi, I`m trying to overlap the computation and memory operation with HuggingFace SwitchTransformer.
Here’s a detailed explanation.
- The memory operation is for data movement from CPU to GPU, and its size is 4MB per block.
- The number of blocks is variable (typically from 2 to 6 in total).
- The computation operation comprises several very small computation operations like GEMM, which takes 10s to 100s microseconds per each.
- I’m trying to use CudaStream, so I created two different Cuda streams and pushed memory operation and computation operation to each of them.
- But it had not been overlapped.
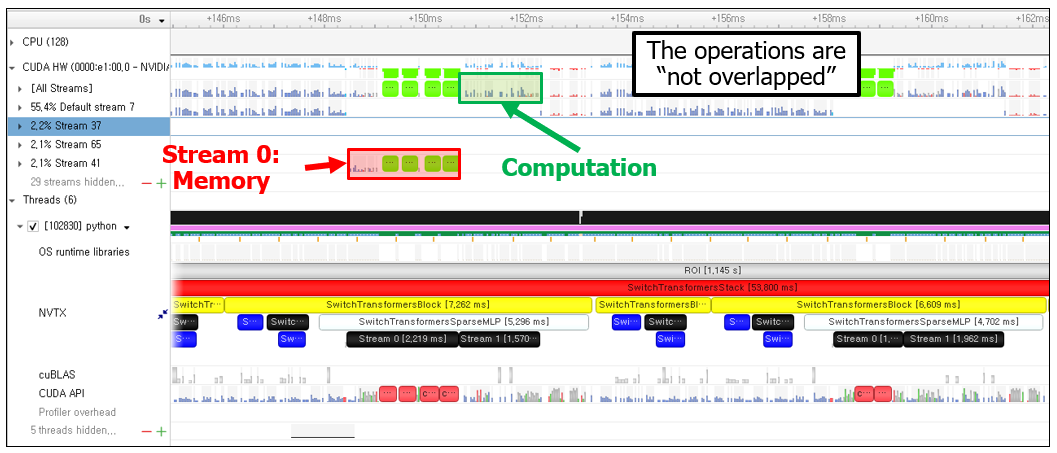
And here’s my question.
-
Firstly, I’d learn that to overlap the memory operation (CPU->GPU) and computation operation, the memory in the CPU should be pinned. But in my case, as can be seen in the figure, it is pageable memory, not pinned. Is it a reason that this cannot be overlapped?
-
Second, I conducted an experiment to prove it with a simple example (overlapping GEMM with CPU->GPU memory operation), and here`s the output.
This is pageable memory.
This is pinned memory.
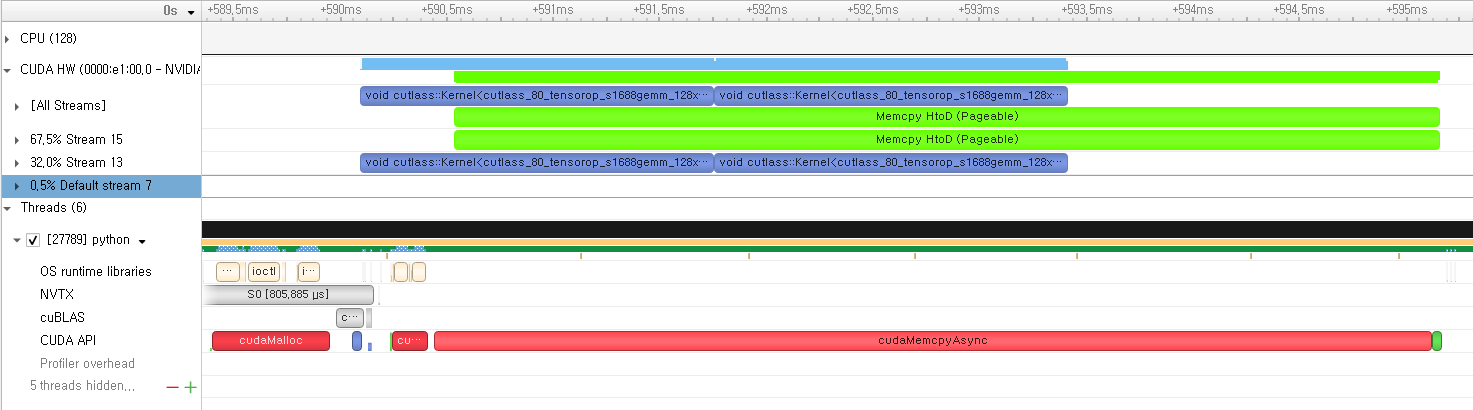

It seems like pageable memory also can be overlapped.
Then, what is the reason that my application is not overlapping?