Hello,
I am trying to backpropagate gradients computed for a GAN. In addition to the normal GAN loss function, this one has a penalty on the gradients of discriminator on real data like such: 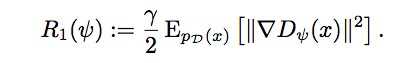
My code per iteration is below where I get the error that “one of the variables needed for gradient computation has been modified by an inplace operation” but I cannot locate which operation is being labeled as in-place.
for epoch in iter_range:
for i, data in enumerate(dataloader,0):
for j in range(extraD):
############################
# (1) Update D network: maximize log(D(x)) + log(1 - D(G(z))), do it more than generator
###########################
# train with real
netD.zero_grad()
#real_cpu = torch.tensor(data[0].to(device), requires_grad=True)
real_cpu = data[0].to(device).requires_grad_()
batch_size = real_cpu.size(0)
label = torch.full((batch_size,), real_label, device=device)
#real_cpu.requires_grad_()
output_r = netD(real_cpu)
#real_cpu.requires_grad_()
#output_r.sum().requires_grad_()
errD_real = criterion(output_r, label)
#errD_real.backward()
D_x = output_r.mean().item()
penalty = grad(output_r.sum(), real_cpu, create_graph=True)[0].view(-1,1).norm(2,1).pow(2).mean()
# train with fake
noise = torch.randn(batch_size, nz, 1, 1, device=device)
fake = netG(noise)
label.fill_(fake_label)
output_f = netD(fake.detach())
errD_fake = criterion(output_f, label)
#errD_fake.backward()
D_G_z1 = output_f.mean().item()
errD = errD_real + errD_fake
(errD + (gamma/2)*penalty).backward()
optimizerD.step()
Does anyone know where the problem is? Thanks for your help.