Hello,
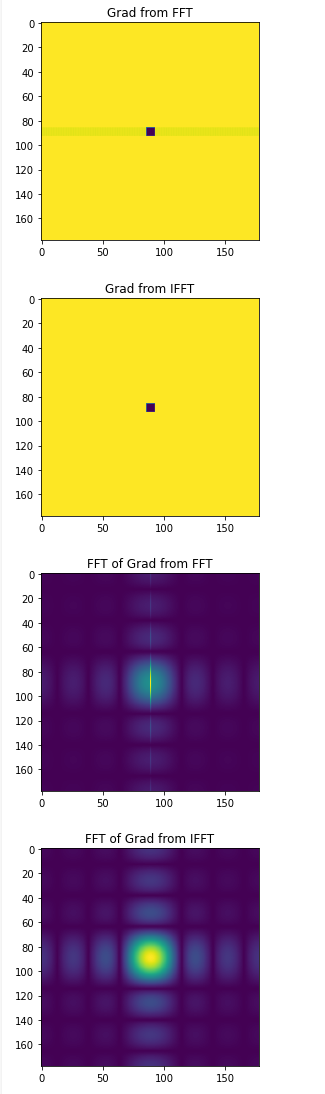
while playing around with a model that will feature calls to the fft functions, I have noticed something odd about the behavior of the gradient. Basically, I cannot do a basic gradient descent when I have exact target data. My starting point is some volumetric data in the shape [1, size, size, size], so three dimensional, with an additional dimension for batch size.
Now if I start with a zeroed volume, then do a rfftn call and then calculate an error based on the FFT of my target volume, I end up with no learning whatsoever. Here is my sample code:
import torch
import torch.fft
import torch.optim
import numpy as np
cuda0 = torch.device('cuda:0')
size = 178
#Target volume
tensorImage = torch.zeros([1, size, size, size], dtype=torch.float32)
for x in range(178):
# Circle
if pow(x - size/2,2) > 10:
continue
for y in range(178):
if pow(y - size/2,2) > 10:
continue
for z in range(178):
if pow(z - size/2,2) > 10:
continue
tensorImage[0,z,y,x] = 1
tensorImage = tensorImage.to(cuda0)
tensorFFT = torch.fft.rfftn(tensorImage, dim=(1,2,3))
#Starting volume, with only 0s
tensorZeroImage = torch.zeros(tensorImage.size(), requires_grad=True, device=cuda0)
optim = torch.optim.SGD([tensorZeroImage], lr=0.01)
for i in range(1000):
optim.zero_grad()
tensorFFTZero = torch.fft.rfftn(tensorZeroImage, dim=(1,2,3))
tensorFFTDiff = tensorFFTZero - tensorFFT
tensorFFTDiffAbs = tensorFFTDiff.abs()
tensorFFTDiffAbsSqrd = tensorFFTDiffAbs
error = tensorFFTDiffAbsSqrd.sum()
error.backward()
optim.step()
if (i+1)%100==0:
print(error)
Output is
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
tensor(8.2181e+10, device='cuda:0', grad_fn=<SumBackward0>)
So no learning whatsoever. There seems to be something odd about the backpropagation through the rfftn call (or fftn).
If I add an ifftn call and then compare the two volumes directly, I get correct learning as expected.
Is there any explanation, why the code above with an error calculation on the fourier transform does not work as expected?