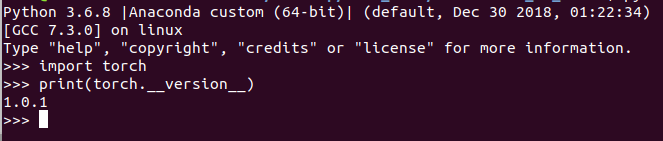
I have 1.0.1 version and it is still giving this error:
Traceback (most recent call last):
File "<ipython-input-2-0cb739d0d1fb>", line 1, in <module>
runfile('/home/hiwi/Desktop/HIWI_Data/Combustion_NN_Model/train.py', wdir='/home/hiwi/Desktop/HIWI_Data/Combustion_NN_Model')
File "/home/hiwi/anaconda3/lib/python3.6/site-packages/spyder_kernels/customize/spydercustomize.py", line 668, in runfile
execfile(filename, namespace)
File "/home/hiwi/anaconda3/lib/python3.6/site-packages/spyder_kernels/customize/spydercustomize.py", line 108, in execfile
exec(compile(f.read(), filename, 'exec'), namespace)
File "/home/hiwi/Desktop/HIWI_Data/Combustion_NN_Model/train.py", line 70, in <module>
main(config, args.resume)
File "/home/hiwi/Desktop/HIWI_Data/Combustion_NN_Model/train.py", line 42, in main
train_logger=train_logger)
File "/home/hiwi/Desktop/HIWI_Data/Combustion_NN_Model/trainer/trainer.py", line 16, in __init__
super(Trainer, self).__init__(model, loss, metrics, optimizer, resume, config, train_logger)
File "/home/hiwi/Desktop/HIWI_Data/Combustion_NN_Model/base/base_trainer.py", line 21, in __init__
self.model = model.to(self.device)
File "/home/hiwi/anaconda3/lib/python3.6/site-packages/torch/jit/__init__.py", line 1280, in fail
raise RuntimeError(name + " is not supported on TracedModules")
RuntimeError: to is not supported on TracedModules
this is how it is being implemented:
class BaseTrainer:
"""
Base class for all trainers
"""
def __init__(self, model, loss, metrics, optimizer, resume, config, train_logger=None):
self.config = config
self.logger = logging.getLogger(self.__class__.__name__)
# setup GPU device if available, move model into configured device
self.device, device_ids = self._prepare_device(config['n_gpu'])
self.model = model.to(self.device)
if len(device_ids) > 1:
self.model = torch.nn.DataParallel(model, device_ids=device_ids)
self.loss = loss
self.metrics = metrics
self.optimizer = optimizer
self.epochs = config['trainer']['epochs']
self.save_freq = config['trainer']['save_freq']
self.verbosity = config['trainer']['verbosity']
self.train_logger = train_logger
# configuration to monitor model performance and save best
self.monitor = config['trainer']['monitor']
self.monitor_mode = config['trainer']['monitor_mode']
assert self.monitor_mode in ['min', 'max', 'off']
self.monitor_best = math.inf if self.monitor_mode == 'min' else -math.inf
self.start_epoch = 1
# setup directory for checkpoint saving
start_time = datetime.datetime.now().strftime('%m%d_%H%M%S')
self.checkpoint_dir = os.path.join(config['trainer']['save_dir'], config['name'], start_time)
# setup visualization writer instance
writer_dir = os.path.join(config['visualization']['log_dir'], config['name'], start_time)
self.writer = WriterTensorboardX(writer_dir, self.logger, config['visualization']['tensorboardX'])
# Save configuration file into checkpoint directory:
ensure_dir(self.checkpoint_dir)
config_save_path = os.path.join(self.checkpoint_dir, 'config.json')
with open(config_save_path, 'w') as handle:
json.dump(config, handle, indent=4, sort_keys=False)
if resume:
self._resume_checkpoint(resume)
and I am using the traced modules like this:
Model File
import torch
import torch.nn as nn
import torch.nn.functional as F
from base import BaseModel
import json
import argparse
class CombustionModel(BaseModel):
def __init__(self, num_features=7):
super(CombustionModel, self).__init__()
sizes = self.get_botleneck_size() #sizes for bottlenecks
self.Fc1 = nn.Linear(in_features = 2, out_features = 500, bias=True)
self.Fc2 = nn.Linear(in_features = 500, out_features = 500, bias=True)
self.Fc3_bottleneck = nn.Linear(in_features = 500, out_features = sizes[0], bias=True)
self.Fc4 = nn.Linear(in_features = sizes[0], out_features = 500, bias=True)
self.Fc5_bottleneck = nn.Linear(in_features = 500, out_features = sizes[1], bias=True)
self.Fc6 = nn.Linear(in_features = sizes[1], out_features = 500, bias=True)
self.Fc7_bottleneck = nn.Linear(in_features = 500, out_features = sizes[2], bias=True)
self.Fc8 = nn.Linear(in_features = sizes[2], out_features = 500, bias=True)
self.Fc9_bottleneck = nn.Linear(in_features = 500, out_features = sizes[3], bias=True)
self.Fc10 = nn.Linear(in_features = sizes[3], out_features = 500, bias=True)
self.Fc11_bottleneck = nn.Linear(in_features = 500, out_features = sizes[4], bias=True)
self.Fc12 = nn.Linear(in_features = sizes[4], out_features = num_features, bias=True)
def get_botleneck_size(self):
parser = argparse.ArgumentParser(description='BottleNeck')
parser.add_argument('-c', '--config', default='config.json', type=str,
help='config file path (default: None)')
args = parser.parse_args()
config = json.load(open(args.config))
bottleneck_size = config['arch']['bottleneck_size']
if type(bottleneck_size) is list:
if len(bottleneck_size) == 5: #comparing it to 5 because we have 5 bottlenecks in the model
pass
else:
raise Exception("bottleneck's list length in config.json file is not equal to number of bottnecks in model's structure")
return bottleneck_size
elif type(bottleneck_size) is int:
list_tmp = []
for i in range(5):
list_tmp.append(bottleneck_size)
bottleneck_size = list_tmp
del(list_tmp)
return bottleneck_size
@torch.jit.script_method
def forward(self, x):
'''
This function computes the network computations based on input x
built in the constructor of the the CombustionModel
'''
'''First Layer'''
x = self.Fc1(x)
x = F.relu(x)
'''First ResNet Block'''
res_calc = self.Fc2(x)
res_calc = F.relu(res_calc)
res_calc = self.Fc3_bottleneck(res_calc)
x = F.relu(torch.add(x, res_calc))
'''Second ResNet Block'''
res_calc = self.Fc4(x)
res_calc = F.relu(res_calc)
res_calc = self.Fc5_bottleneck(res_calc)
x = F.relu(torch.add(x, res_calc))
'''Third ResNet Block'''
res_calc = self.Fc6(x)
res_calc = F.relu(res_calc)
res_calc = self.Fc7_bottleneck(res_calc)
x = F.relu(torch.add(x, res_calc))
'''Fourth ResNet Block'''
res_calc = self.Fc8(x)
res_calc = F.relu(res_calc)
res_calc = self.Fc9_bottleneck(res_calc)
x = F.relu(torch.add(x, res_calc))
'''Fifth ResNet Block'''
res_calc = self.Fc10(x)
res_calc = F.relu(res_calc)
res_calc = self.Fc11_bottleneck(res_calc)
x = F.relu(torch.add(x, res_calc))
'''Regression layer'''
return self.Fc12(x)
this is base model file
import logging
import torch
import numpy as np
class BaseModel(torch.jit.ScriptModule):
"""
Base class for all models
"""
def __init__(self):
super(BaseModel, self).__init__()
self.logger = logging.getLogger(self.__class__.__name__)
def forward(self, *input):
"""
Forward pass logic
:return: Model output
"""
raise NotImplementedError
def summary(self):
"""
Model summary
"""
model_parameters = filter(lambda p: p.requires_grad, self.parameters())
params = sum([np.prod(p.size()) for p in model_parameters])
self.logger.info('Trainable parameters: {}'.format(params))
self.logger.info(self)