Hello, I encountered some problems when transferring the model. The problems are as follows:
def convert_onnx():
x = torch.randn((1, 3, 224, 224)).cuda()
config = Configs()
device = torch.device("cuda", index=0)
net = Net(config, device).to(device)
net.load_state_dict(
torch.load("/workspace/code/TReS/Save_TReS_50/spaq_6_2022/sv/bestmodel_6_2022"))
net.eval()
path = "/workspace/code/TReS/Save_TReS_50/"
torch.onnx.export(net,
x,
"noise.onnx",
export_params=True,
opset_version=13,
training=False,
do_constant_folding=False,
input_names=['input'],
output_names=['output'],
dynamic_axes={"input": {0: "batch_size"}, "output": {0: "batch_size"}})
print("save model to %s" % path)
errors:
/workspace/code/TReS/models.py:29: TracerWarning: Converting a tensor to a Python integer might cause the trace to be incorrect. We can’t record the data flow of Python values, so this value will be treated as a constant in the future. This means that the trace might not generalize to other inputs!
out = F.conv2d(input, self.filter, stride=self.stride, padding=self.padding, groups=input.shape[1])
Traceback (most recent call last):
File “/workspace/code/TReS/save_onnx.py”, line 63, in
convert_onnx()
File “/workspace/code/TReS/save_onnx.py”, line 36, in convert_onnx
dynamic_axes={“input”: {0: “batch_size”}, “output”: {0: “batch_size”}})
File “/opt/conda/envs/tres/lib/python3.6/site-packages/torch/onnx/init.py”, line 276, in export
custom_opsets, enable_onnx_checker, use_external_data_format)
File “/opt/conda/envs/tres/lib/python3.6/site-packages/torch/onnx/utils.py”, line 94, in export
use_external_data_format=use_external_data_format)
File “/opt/conda/envs/tres/lib/python3.6/site-packages/torch/onnx/utils.py”, line 698, in _export
dynamic_axes=dynamic_axes)
File “/opt/conda/envs/tres/lib/python3.6/site-packages/torch/onnx/utils.py”, line 465, in _model_to_graph
module=module)
File “/opt/conda/envs/tres/lib/python3.6/site-packages/torch/onnx/utils.py”, line 206, in _optimize_graph
graph = torch._C._jit_pass_onnx(graph, operator_export_type)
File “/opt/conda/envs/tres/lib/python3.6/site-packages/torch/onnx/init.py”, line 309, in _run_symbolic_function
return utils._run_symbolic_function(*args, **kwargs)
File “/opt/conda/envs/tres/lib/python3.6/site-packages/torch/onnx/utils.py”, line 990, in _run_symbolic_function
symbolic_fn = _find_symbolic_in_registry(domain, op_name, opset_version, operator_export_type)
File “/opt/conda/envs/tres/lib/python3.6/site-packages/torch/onnx/utils.py”, line 947, in _find_symbolic_in_registry
return sym_registry.get_registered_op(op_name, domain, opset_version)
File “/opt/conda/envs/tres/lib/python3.6/site-packages/torch/onnx/symbolic_registry.py”, line 112, in get_registered_op
raise RuntimeError(msg)
RuntimeError: Exporting the operator broadcast_tensors to ONNX opset version 13 is not supported. Please feel free to request support or submit a pull request on PyTorch GitHub.
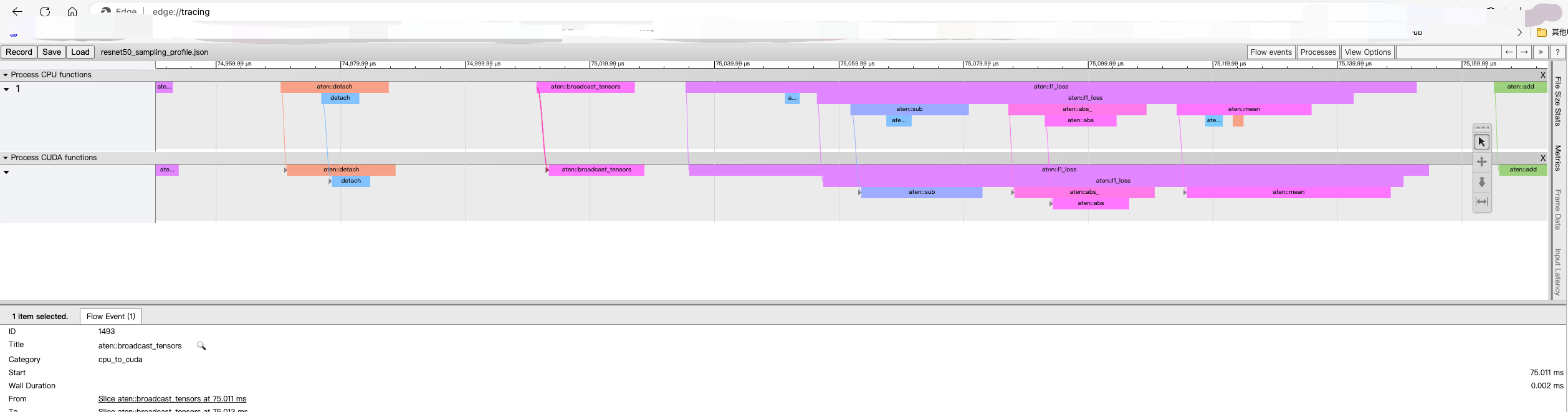
I tried to find the unsupported operator in my model, using this command, but did not find it, would like to ask everyone how to find this operator and replace it:
with torch.autograd.profiler.profile(enabled=True, use_cuda=True, record_shapes=False,
profile_memory=False) as prof:
outputs = model(dump_input)
print(prof.table())
prof.export_chrome_trace('./resnet50_sampling_profile.json')
My version is :
pytorch 1.8.0 py3.6_cuda11.1_cudnn8.0.5_0 pytorch
Model Structure:
Net(
(L2pooling_l1): L2pooling()
(L2pooling_l2): L2pooling()
(L2pooling_l3): L2pooling()
(L2pooling_l4): L2pooling()
(model): ResNet(
(conv1): Conv2d(3, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(maxpool): MaxPool2d(kernel_size=3, stride=2, padding=1, dilation=1, ceil_mode=False)
(layer1): Sequential(
(0): Bottleneck(
(conv1): Conv2d(64, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(256, 64, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(64, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer2): Sequential(
(0): Bottleneck(
(conv1): Conv2d(256, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(256, 512, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(512, 128, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(128, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer3): Sequential(
(0): Bottleneck(
(conv1): Conv2d(512, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(512, 1024, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(3): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(4): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(5): Bottleneck(
(conv1): Conv2d(1024, 256, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(256, 1024, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(layer4): Sequential(
(0): Bottleneck(
(conv1): Conv2d(1024, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
(downsample): Sequential(
(0): Conv2d(1024, 2048, kernel_size=(1, 1), stride=(2, 2), bias=False)
(1): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
)
)
(1): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
(2): Bottleneck(
(conv1): Conv2d(2048, 512, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1), bias=False)
(bn2): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv3): Conv2d(512, 2048, kernel_size=(1, 1), stride=(1, 1), bias=False)
(bn3): BatchNorm2d(2048, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(relu): ReLU(inplace=True)
)
)
(avgpool): AdaptiveAvgPool2d(output_size=(1, 1))
(fc): Linear(in_features=2048, out_features=1000, bias=True)
)
(transformer): Transformer(
(encoder): TransformerEncoder(
(layers): ModuleList(
(0): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=3840, out_features=3840, bias=True)
)
(linear1): Linear(in_features=3840, out_features=64, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
(linear2): Linear(in_features=64, out_features=3840, bias=True)
(norm1): LayerNorm((3840,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((3840,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.5, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
)
(1): TransformerEncoderLayer(
(self_attn): MultiheadAttention(
(out_proj): _LinearWithBias(in_features=3840, out_features=3840, bias=True)
)
(linear1): Linear(in_features=3840, out_features=64, bias=True)
(dropout): Dropout(p=0.5, inplace=False)
(linear2): Linear(in_features=64, out_features=3840, bias=True)
(norm1): LayerNorm((3840,), eps=1e-05, elementwise_affine=True)
(norm2): LayerNorm((3840,), eps=1e-05, elementwise_affine=True)
(dropout1): Dropout(p=0.5, inplace=False)
(dropout2): Dropout(p=0.5, inplace=False)
)
)
(norm): LayerNorm((3840,), eps=1e-05, elementwise_affine=True)
)
)
(position_embedding): PositionEmbeddingSine()
(fc2): Linear(in_features=3840, out_features=2048, bias=True)
(fc): Linear(in_features=4096, out_features=1, bias=True)
(ReLU): ReLU()
(avg7): AvgPool2d(kernel_size=(7, 7), stride=(7, 7), padding=0)
(avg8): AvgPool2d(kernel_size=(8, 8), stride=(8, 8), padding=0)
(avg4): AvgPool2d(kernel_size=(4, 4), stride=(4, 4), padding=0)
(avg2): AvgPool2d(kernel_size=(2, 2), stride=(2, 2), padding=0)
(drop2d): Dropout(p=0.1, inplace=False)
(consistency): L1Loss()
)
maybe L1 loss not support?
consistloss1 = self.consistency(out_t_c, fout_t_c.detach())
consistloss2 = self.consistency(layer4, flayer4.detach())
consistloss = 1 * (consistloss1 + consistloss2)